
随着 Kubernetes 的发展,有越来越多的公司尝试利用 Kubernetes 来管理机器学习工作负载,Kubeflow 也受到了更多的关注。社区中的各种项目都有了更多的贡献者和用户。katib 作为社区中云原生的自动机器学习系统,在近期发布了新的版本。这一文章主要介绍新版本 v1alpha2 的设计与实现。katib 第一个版本的介绍可以参考文章 Katib: Kubernetes native 的超参数训练系统。
问题背景
如今,机器学习技术和算法几乎应用于每个领域。而建立一个高质量的机器学习模型是一个迭代的、复杂的、耗时的过程,除了要有一个有效调整超参数的良好经验外,还需要尝试不同的算法和技术。有效地进行这个过程需要扎实的知识和经验。随着数据量的持续和巨大增长,人们已经认识到,有知识的数据科学家的数量无法扩大到足以解决这些难题。因此,将建立良好机器学习模型的过程自动化是至关重要的。
目前,深度学习领域有超参数搜索和模型结构搜索等技术来用计算力来减少人力需求。这些技术的主要目的是通过扮演领域专家的角色,减少人工在该过程中的作用,填补非专家机器学习用户的空白。这篇文章主要介绍了云原生的超参数搜索与模型结构搜索系统 katib 的设计与实现,并且对比了与其他工作的优劣。
相关工作
超参数搜索
超参数训练在工业界和学术界都有相当程度的关注,目前也已经相对成熟。其问题可以被形式化地表示为在给定的多维搜索空间下的黑盒优化问题。对于单一的超参数而言,其可能是离散的值,如激活函数的选择等,也有可能是连续的值。而由于超参数的数量不确定,因此搜索空间是多维的。而由于对于超参数训练而言,输入的参数与输出是相互独立的变量,因此属于黑盒优化的范畴。
目前工业界较常用的超参数训练算法主要有随机搜索,网格搜索和贝叶斯优化等。
网格搜索是指在所有候选的参数选择中,通过循环遍历尝试每一种可能性,表现最好的参数就是最终的结果。网格搜索算法思路及实现方式都很简单,但经过笛卡尔积组合后会扩大搜索空间,并且在存在某种不重要的超参数的情况下,网格搜索会浪费大量的时间及空间做无用功,因此它只适用于超参数数量小的情况。
针对网格搜索的不足,Bengio 等人提出了随机搜索方法。随机搜索首先为每类超参数定义一个边缘分布,通常取均匀分布,然后在这些参数上采样进行搜索。
随机搜索虽然有随机因素导致搜索结果可能特别差,但是也可能效果特别好。总体来说效率比网格搜索更高,但是不保证一定能找到比较好的超参数。
贝叶斯优化是一个经典的黑盒优化算法,其利用了无限维的高斯过程来模拟黑盒的超参数搜索的目标函数形式,限于篇幅,不再赘述,其大致原理是利用之前探索的结果,探索更有可能的新的参数选择。
除此之外,学术界还有许多其他的超参数搜索算法,如 HyperBand 等。
模型结构搜索
模型结构搜索是目前学术界的研究热点之一。目前阶段,神经网络的结构设计需要特定领域的算法科学家进行人工的分析与建模,而模型结构搜索希望通过强化学习或者进化算法的方式,自动地寻找到最优的模型结构。
目前比较有影响力的工作有 ENAS,Auto-Keras,DARTS,ProxylessNAS 等。目前的 NAS 都会采用某种意义上的参数共享,来加速模型搜索的过程,进而缓解其对算力的巨大要求。
自动机器学习系统
超参数搜索与模型结构搜索,一定程度上,是可通用的算法。因此目前也有许多自动机器学习系统,帮助算法科学家们更方便地进行自动机器学习。其中 Google Vizier 对超参数搜索问题进行了非常好的抽象,并且基于此实现了谷歌内部的超参数搜索系统。
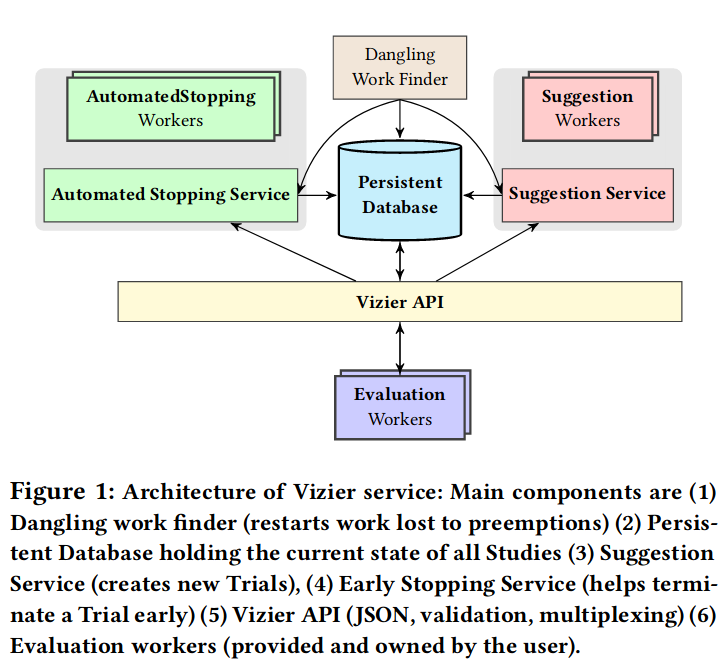
受这一工作启发,工业界有许多开源实现,其中最具代表性的是 advisor。
auto-keras 是一个专门用来进行模型结构搜索的库。它提供了模型结构搜索的基准实现,其中包括随机搜索,网格搜索,贪心算法和贝叶斯优化等。与此同时,它允许用户自行定义新的模型结构搜索算法,并且集成在 auto-keras 中。
除此之外,nni 是由微软亚研院开源的自动机器学习工具。它是既支持模型结构搜索,也支持超参数搜索的工具。它为模型结构搜索实现了一个统一的接口,相比于其他的工具,具有更好的易用性。
katib 的设计与实现
虽然目前已经有了许多可以帮助算法工程师们快速进行参数搜索的工具,但目前的工具,大多会引入额外的组件。这样的实现会增加运维的负担。katib 旨在实现一个云原生的超参数搜索与模型结构搜索系统,复用 Kubernetes 对 GPU 等资源的管理能力,同时保证系统的可扩展性。云原生的实现使得维护这一系统的工作对运维工程师更加友好。
目前的设计
为了实现 katib 云原生的架构目标,新的版本引入了两个 CRD:Experiment 和 Trial。Experiment 定义类似于 Google Vizier 中的 Study,在 katib v1alpha1 中,它的名字是 StudyJob。它存储了超参数搜索或者模型结构搜索的搜索空间,以及 Trial 训练任务的模板,和优化的目标值等内容。Trial 是 Experiment 在确定了搜索空间中的一组参数取值后,进行的模型训练任务。它包含训练任务实例,以及训练的指标等。当 Trial 的状态为 Completed 时,就意味着这一组参数被验证了,而且对应的训练指标被收集起来了。
而 Job 是 Kubernetes 上的一个训练实例,它是用来验证一个 Trial 中的参数的。Job 可以是 TensorFlow 模型训练任务 TFJob,也可以是 PyTorch 训练任务 PyTorchJob,也可以是以 Kubernetes batchv1/job 运行的任意框架的训练代码。
Suggestion 是在 Experiment 中定义的搜索空间中寻找一组参数取值的算法。寻找到的参数取值会交给 Trial 去运行。目前 kaitb 支持:
- random search
- grid search
- hyperband
- bayesian optimization
- NAS based on reinforcement learning
- NAS based on EnvelopeNets
Case Study:随机超参数搜索任务
接下来,我们以一次超参数搜索任务为例,从用户的角度看下 katib 的使用流程。
对于用户而言,他/她只需要创建出 Experiment 即可进行超参数搜索训练:
apiVersion: "kubeflow.org/v1alpha2"
kind: Experiment
metadata:
namespace: kubeflow
name: random-experiment
spec:
parallelTrialCount: 3
maxTrialCount: 12
maxFailedTrialCount: 3
objective:
type: maximize
goal: 0.99
objectiveMetricName: Validation-accuracy
additionalMetricNames:
- accuracy
algorithm:
algorithmName: random
trialTemplate:
goTemplate:
rawTemplate: |-
apiVersion: batch/v1
kind: Job
metadata:
name:
namespace:
spec:
template:
spec:
containers:
- name:
image: katib/mxnet-mnist-example
command:
- "python"
- "/mxnet/example/image-classification/train_mnist.py"
- "--batch-size=64"
- "="
restartPolicy: Never
parameters:
- name: --lr
parameterType: double
feasibleSpace:
min: "0.01"
max: "0.03"
- name: --num-layers
parameterType: int
feasibleSpace:
min: "2"
max: "5"
- name: --optimizer
parameterType: categorical
feasibleSpace:
list:
- sgd
- adam
- ftrl
这一个配置包含了完成一个超参数训练需要的所有信息,其中包括需要优化的目标指标,需要用到的搜索算法,Trial 的训练代码,以及搜索空间等。下面我们将会一个个介绍。
parallelTrialCount: 3
maxTrialCount: 12
maxFailedTrialCount: 3
首先是关于并行相关的配置。其中的 parallelTrialCount 是定义了允许的并行数,在这个例子中,用户允许同一时间内有 3 个运行的 Trial。maxTrialCount 是最大的 Trial 数量,在例子中为 12,也就是在 12 个 Trial 运行完后,Experiment 就被标记为完成。maxFailedTrialCount 是最大允许失败的次数,在这一例子中,用户可以容忍 3 个 Trial 是训练失败的。
objective:
type: maximize
goal: 0.99
objectiveMetricName: Validation-accuracy
additionalMetricNames:
- accuracy
objective 这一部分是对训练目标的定义。在这一例子中,用户定义了训练的目标是准确率,训练目标是最大化准确率,当准确率到达 0.99 时,超参数训练任务可以被认为已经完成。
algorithm:
algorithmName: random
trialTemplate:
goTemplate:
rawTemplate: |-
apiVersion: batch/v1
kind: Job
metadata:
name:
namespace:
spec:
template:
spec:
containers:
- name:
image: katib/mxnet-mnist-example
command:
- "python"
- "/mxnet/example/image-classification/train_mnist.py"
- "--batch-size=64"
- "="
restartPolicy: Never
algorithm 一项定义了超参数搜索的算法,这里用户希望使用随机搜索。而后面的 trialTemplate 则是定义了 Trial 进行训练时需要的代码。在这一例子中,用户使用了 batch/v1 Job 类型进行训练,使用的框架是 MXNet。在其中我们可以看到一个模板的定义 .HyperParameters,这一定义会在确定了参数取值后被解释执行,生成完整的训练代码定义。
parameters:
- name: --lr
parameterType: double
feasibleSpace:
min: "0.01"
max: "0.03"
- name: --num-layers
parameterType: int
feasibleSpace:
min: "2"
max: "5"
- name: --optimizer
parameterType: categorical
feasibleSpace:
list:
- sgd
- adam
- ftrl
最后,用户定义了需要搜索的参数空间。在这个例子中,用户一共定义了三个需要搜索的参数,分别是 --lr,--num-layers 和 --optimizer。其中第一个参数,--lr,也就是 Learning Rate 的搜索空间是一个范围,是从 0.01 到 0.03 的浮点数范围。而第二个参数的搜索空间是从 2 到 5 的整形数空间,也就是有 2,3,4,5 四个选择。第三个参数的搜索空间是一个列表,有三个选择,分别是 sgd,adam 和 ftrl。
用户在 Kubernetes 中创建了这一 Experiment 之后,Experiment 会根据用户的定义创建出对应的 Trials:
NAME STATUS AGE
random-experiment-9lclwqcl Running 72s
random-experiment-lvsf826b Running 72s
random-experiment-wkp9ctq5 Running 72s
在每一个 Trial 中,配置如下:
apiVersion: kubeflow.org/v1alpha2
kind: Trial
metadata:
creationTimestamp: "2019-08-06T06:48:13Z"
generation: 1
labels:
experiment: random-experiment
name: random-experiment-9lclwqcl
namespace: kubeflow
ownerReferences:
- apiVersion: kubeflow.org/v1alpha2
blockOwnerDeletion: true
controller: true
kind: Experiment
name: random-experiment
uid: 24b93200-b55a-4610-a42d-c2fb23cb2a61
resourceVersion: "19502"
selfLink: /apis/kubeflow.org/v1alpha2/namespaces/kubeflow/trials/random-experiment-9lclwqcl
uid: 788778ef-013d-4653-bf9d-750a30abb1c6
spec:
metricsCollectorSpec: |-
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: random-experiment-9lclwqcl
namespace: kubeflow
spec:
schedule: "*/1 * * * *"
successfulJobsHistoryLimit: 0
failedJobsHistoryLimit: 1
concurrencyPolicy: Forbid
jobTemplate:
spec:
backoffLimit: 0
template:
spec:
serviceAccountName: metrics-collector
containers:
- name: random-experiment-9lclwqcl
image: gcr.io/kubeflow-images-public/katib/v1alpha2/metrics-collector
imagePullPolicy: IfNotPresent
command: ["./metricscollector"]
args:
- "-e"
- "random-experiment"
- "-t"
- "random-experiment-9lclwqcl"
- "-k"
- "Job"
- "-n"
- "kubeflow"
- "-m"
- "katib-manager.kubeflow:6789"
- "-mn"
- "Validation-accuracy;accuracy"
restartPolicy: Never
objective:
additionalMetricNames:
- accuracy
goal: 0.99
objectiveMetricName: Validation-accuracy
type: maximize
parameterAssignments:
- name: --lr
value: "0.016681020412579572"
- name: --num-layers
value: "3"
- name: --optimizer
value: sgd
runSpec: |-
apiVersion: batch/v1
kind: Job
metadata:
name: random-experiment-9lclwqcl
namespace: kubeflow
spec:
template:
spec:
containers:
- name: random-experiment-9lclwqcl
image: katib/mxnet-mnist-example
command:
- "python"
- "/mxnet/example/image-classification/train_mnist.py"
- "--batch-size=64"
- "--lr=0.016681020412579572"
- "--num-layers=3"
- "--optimizer=sgd"
restartPolicy: Never
其中的 metricsCollectorSpec 是一个 Job 的定义,这一 Job 是用来收集训练指标的,后面会详细介绍。接下来的 Objective 是跟 Experiment 中的 Objective 一致的。parameterAssignments 则是 Experiment 定义的搜索空间下的一组参数取值。其中 --lr 的取值是 0.016681020412579572,--num-layers 的取值是 3,--optimizer 的取值是 sgd。而 runSpec 的定义,是根据 parameterAssignments 以及 Experiment 中的 TrialTemplate 定义生成的,真正可以被运行的 Kubernetes 资源定义。在这一例子中,RunSpec 会被以 Kubernetes batchv1 Job 的方式,运行起来,其真实的配置如下:
apiVersion: batch/v1
kind: Job
metadata:
creationTimestamp: "2019-08-06T06:48:13Z"
labels:
controller-uid: 7acefe5f-1738-42ff-ae87-b7069a6d0ecd
job-name: random-experiment-9lclwqcl
name: random-experiment-9lclwqcl
namespace: kubeflow
ownerReferences:
- apiVersion: kubeflow.org/v1alpha2
blockOwnerDeletion: true
controller: true
kind: Trial
name: random-experiment-9lclwqcl
uid: 788778ef-013d-4653-bf9d-750a30abb1c6
resourceVersion: "19500"
selfLink: /apis/batch/v1/namespaces/kubeflow/jobs/random-experiment-9lclwqcl
uid: 7acefe5f-1738-42ff-ae87-b7069a6d0ecd
spec:
backoffLimit: 6
completions: 1
parallelism: 1
selector:
matchLabels:
controller-uid: 7acefe5f-1738-42ff-ae87-b7069a6d0ecd
template:
metadata:
creationTimestamp: null
labels:
controller-uid: 7acefe5f-1738-42ff-ae87-b7069a6d0ecd
job-name: random-experiment-9lclwqcl
spec:
containers:
- command:
- python
- /mxnet/example/image-classification/train_mnist.py
- --batch-size=64
- --lr=0.016681020412579572
- --num-layers=3
- --optimizer=sgd
image: katib/mxnet-mnist-example
imagePullPolicy: Always
name: random-experiment-9lclwqcl
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Never
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
这一 Job 是真正的训练代码,超参数已经通过命令行参数的方式传入到了代码中,而训练代码就可以直接利用提供的超参数进行模型训练。而这一训练任务的指标,会由之前在 metricsCollectorSpec 中定义的另一个 Job 完成,训练任务的 Job Name 会以命令行参数的方式传入 metricsCollector Job,metricsCollector Job 会利用 Kubernetes Client 获取训练任务的日志,并且从日志中处理得到训练的指标,并且通过 Katib Manager 存入 Katib DB。这些训练指标会在后续的超参数搜索算法(如贝叶斯优化)中被用来寻找新的参数取值。
处理流程
在了解 katib 的处理流程之前,先介绍下 katib 目前有哪些组件:
- Experiment Controller,提供对 Experiment CRD 的生命周期管理。
- Trial Controller,提供对 Trial CRD 的生命周期管理。
- Suggestions,以 Deployment 的方式部署,用 Service 方式暴露服务,提供超参数搜索服务。目前有随机搜索,网格搜索,贝叶斯优化等。
- Katib Manager,一个 GRPC server,提供了对 Katib DB 的操作接口,同时充当 Suggestion 与 Experiment 之间的代理。
- Katib DB,数据库。其中会储存 Trial 和 Experiment,以及 Trial 的训练指标。目前默认的数据库为 MySQL。
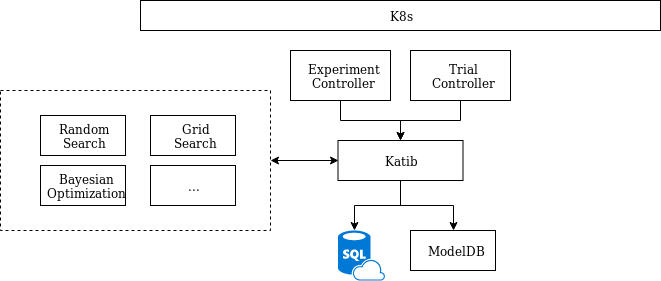
当一个 Experiment 被创建的时候,Experiment Controller 会先通过 Katib Manager 在 Katib DB 中创建一个 Experiment 对象,并且打上 Finalizer 表明这一对象使用了外部资源(数据库)。随后,Experiment Controller 会根据自身的状态和关于并行的定义,通过 Katib Manager 提供的 GRPC 接口,让 Manager 通过 Suggestion 提供的 GRPC 接口获取超参数取值,然后再转发给 Experiment Controller。在这个过程中,Katib Manager 是一个代理的角色,它代理了 Experiment Controller 对 Suggestion 的请求。拿到超参数取值后,Experiment Controller 会根据 TrialTemplate 和超参数的取值,构造出 Trial 的定义,然后在集群中创建它。
Trial 被创建后,与 Experiment Controller 的行为类似,Trial Controller 同样会通过 Katib Manager 在 Katib DB 中创建一个 Trial 对象。随后会构造出期望的 Job(如 batchv1 Job,TFJob,PyTorchJob 等)和 Metrics Collector Job,然后在集群上创建出来。这些 Job 运行结束后,Trial Controller 会更新 Trial 的状态,进而 Experiment Controller 会更新 Experiment 的状态。
然后 Experiment 会继续下一轮的迭代。之前的 Trial 已经被训练完成,而且训练的指标已经被收集起来了。Experiment 会根据配置,判断是否要再创建新的 Trial,如果需要则再重复之前的流程。
未来规划
目前 Katib v1alpha2 的架构还不是特别完善存在一些问题:
- Katib Manager 作为 Experiment Controller 和 Suggestion 之前的代理,有些多余。所有的请求需要利用 GRPC 先发到 Manager,再由 Manager 从 Katib DB 中获取相关信息后转发给 Suggestion。这样的设计使得数据库成为了主流程中的一个可能的瓶颈。
- Katib DB 中存在冗余的信息,Experiment 和 Trial 在 Kubernetes apiserver 后的 etcd 中有存储,而在 Katib DB 中又会维护一个 Copy,这可能会导致在 Experiment 和 Trial 在 etcd 和 Katib DB 的一致性问题。
- Suggestion 目前没有被较好地管理起来,目前的方式依赖用户手动维护 Suggestion 的 Deployment 和 Service,并且在扩展时,需要与 Katib Manager 交互,对用户来说并不友好。
- 模型结构搜索较弱。目前的架构,难以支持如 DARTS 等较新的模型结构搜索算法。同时 Suggestion 在目前版本中是 Long Running 的,而模型结构搜索的算法,有时只能为单一的 Experiment 服务。
- 训练指标收集的方式扩展性较差,而且存在权限问题。现行的方案需要创建一个新的 Job 专门负责收集日志得到训练指标。这一 Job 需要有权限通过 Kubernetes API 获取训练日志。不方便扩展到文件日志等其他方式。
为了解决这些问题,社区目前在做的工作包括:
- 利用 Sidecar 的模式,替代现行训练指标收集的方案。Sidecar 和训练容器在同一 Pod 中,利用与 Sidecar Container With a Logging Agent 类似的方式,获取并且处理日志。这一方式可以提供较好的扩展性,能够支持更多收集方式。
- 引入新的 CRD:Suggestion。重新设计 Suggestion 的 API,使得 Experiment 在获取 Suggestion 的超参数取值时,不需要通过 Katib Manager 这一代理。同时保证每一个 Suggestion 只服务一个 Experiment。
- 引入统一的数据存储接口,支持不同的数据库。
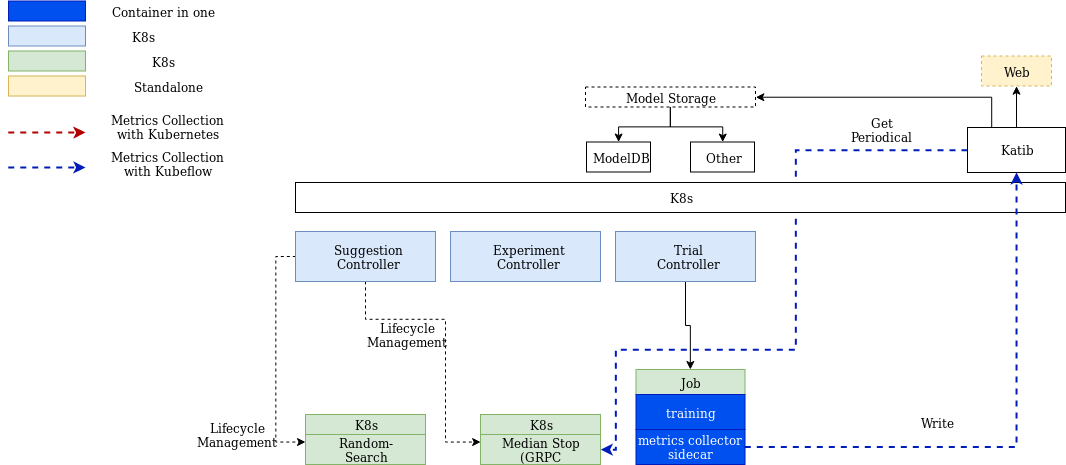
规划中的架构如图所示,目前这些工作还在继续,所以可能会有变动。在新的架构中,存在三个 CRD,Experiment,Trial 和 Suggestion。同时三个 Controller 不会依赖外部的数据库,不再会在数据库中维护 Experiment 和 Trial 的备份。只有训练指标会在 Metrics Collector Sidecar 中被收集后存入数据库中。这些指标的最终值,会被某些超参数搜索算法,如贝叶斯优化等,用于产生新的超参数取值。这些指标在训练过程中的中间值,会被 EarlyStopping 服务用于停止训练效果不佳的 Trial。
总结与分析
最后,总结一下与 advisor 和 NNI 的相似之处以及不同之处。Google Vizier 也在列,但由于 Vizier 并不是开源的产品,所以这里略过。
| katib | advisor | NNI | Google Vizier | |
|---|---|---|---|---|
| 并行的 Trial | 支持 | 支持 | 支持 | 支持 |
| 集群资源利用 | 支持 Kubernetes | 不支持 | 支持多种平台 | 支持 Google DataCenters |
| 分布式训练支持 | 支持 | 不支持(?) | 支持 | 支持 |
| 超参数搜索算法支持 | 目前较少 | 较多 | 较多 | 未知 |
| 算法的扩展性 | 较高 | 较高 | 较高 | 较高 |
| 早期停止策略支持 | 目前较差,依赖框架层面 | 目前较差,依赖框架层面 | 较好 | |
| 模型结构搜索支持 | 目前较差 | 无 | 较高 | 无 |
| 训练指标收集方式 | 目前支持 Pull-based,后续支持 Push-based 和 Pull-based | Pull-based | Push-based | 未知 |
| 对用户训练代码的侵入性 | 较低 | 较低 | 目前较高 | 未知 |
| 云原生 | Kubernetes Native (深度依赖 CRD) | 较低,支持 Kubernetes 部署 | 较低,支持在 Kubernetes 上运行训练 | 闭源产品 |
| 开源许可 | Apache 2.0 | Apache 2.0 | MIT | 闭源 |
katib,advisor 和 NNI 都支持并行地进行超参数搜索。katib 支持利用 Kubernetes 的集群资源进行超参数搜索,advisor 则不支持利用集群资源,NNI 支持不同的平台,如 Microsoft PAI,原生的 Kubernetes,支持 Kubeflow 的 Kubernetes 等。对于超参数算法的支持,katib 目前仅支持贝叶斯优化,HyperBand,随机搜索和网格搜索。而 advisor 和 NNI 都有更多的算法支持。这也是 katib 需要后续完善的一方面。katib,advisor 和 NNI 对算法的扩展性都不错。对于早期停止策略的支持,katib 和 advisor 都不是特别好,NNI 具有更完善的支持。对于模型结构搜索,NNI 支持最好,katib 次之,advisor 并无对应功能。
对于训练指标的收集,NNI 实现了一个 SDK,允许用户通过 SDK 汇报训练指标,属于 Push-based 的实现,具有一定的侵入性。katib 和 advisor 都希望通过 Pull-based 的实现,不修改用户代码,而是分析输出日志。但 katib 希望在未来实现两种不同的方式,提供更好的扩展性,同时将选择权交给用户。
对于用户代码的修改,涉及到两处功能:首先是训练指标的收集,系统需要获得训练过程的准确率等数据,指导后续的搜索。其次是超参数的注入。超参数需要被注入训练代码,支持探索性的训练。NNI 无论是超参数搜索还是模型结构搜索,都需要用户在代码中添加 comment 或者利用 SDK 的方式进行改动,具有一定的侵入性。但 NNI 具有一些 AST 级别的 Trick,使得这部分修改在没有 NNI 的情况下,也不会影响正常的执行。而 katib 和 advisor 都希望做到对用户代码的零侵入性。katib 目前在训练指标收集上可以通过日志收集的方式做到零侵入性。而在超参数注入的问题上,后续会探索利用与 NNI 类似的 AST 重写的方式,在运行时改写用户代码,而不再需要目前命令行参数的修改方式。
katib 是 Kubernetes Native 的系统,它的目标就是能够以 Kubernetes Native 的方式部署在 Kubernetes 上并且方便运维。所以 katib 能够尽可能以 CRD 等 Kubernetes 扩展功能的方式实现自身的逻辑。这样的理念使得它对 Kubernetes 和 Kubeflow 的用户非常友好。advisor 是一个独立的系统。NNI 也是一个相对独立的系统,只是它的训练任务可以运行在不同的平台上。
开源许可方面,katib 和 advisor 都是采取 Apache 2.0 许可,NNI 是在 MIT 许可下开源的。
总而言之,在 2019 年 8 月份的当下,如果是不考虑云原生的部署方式,或者目前对模型结构搜索具有更强的需求,同时用户不在意对代码添加注释这样的修改方式,应该考虑 NNI。而如果希望超参数搜索与模型结构搜索系统是云原生的,能够容忍现阶段模型结构搜索支持较差的现状,同时对用户代码零侵入性比较在意的话,可以考虑 katib。
katib 作为 Kubeflow 社区的项目,非常欢迎更多的贡献。感谢目前的贡献者的工作,也希望大家如果对 katib 感兴趣,可以积极参与社区贡献。如果有任何相关问题,可以与我联系。
参考文献
- Elshawi, Radwa, Mohamed Maher, and Sherif Sakr. “Automated Machine Learning: State-of-The-Art and Open Challenges.” arXiv preprint arXiv:1906.02287 (2019).
- Bergstra, James, and Yoshua Bengio. “Random search for hyper-parameter optimization.” Journal of Machine Learning Research 13.Feb (2012): 281-305.
- Pelikan, Martin, David E. Goldberg, and Erick Cantú-Paz. “BOA: The Bayesian optimization algorithm.” Proceedings of the 1st Annual Conference on Genetic and Evolutionary Computation-Volume 1. Morgan Kaufmann Publishers Inc., 1999.
- Hyperparameter tuning for machine learning models.
- Pham, Hieu, et al. “Efficient neural architecture search via parameter sharing.” arXiv preprint arXiv:1802.03268 (2018).
- Jin, Haifeng, Qingquan Song, and Xia Hu. “Efficient neural architecture search with network morphism.” arXiv preprint arXiv:1806.10282 (2018).
- Liu, Hanxiao, Karen Simonyan, and Yiming Yang. “Darts: Differentiable architecture search.” arXiv preprint arXiv:1806.09055 (2018).
- Cai, Han, Ligeng Zhu, and Song Han. “Proxylessnas: Direct neural architecture search on target task and hardware.” arXiv preprint arXiv:1812.00332 (2018).
关于作者
高策,才云科技软件工程师,Kubeflow 社区贡献者,主要维护 tf-operator,katib 等项目。
License
- This article is licensed under CC BY-NC-SA 3.0.
- Please contact me for commercial use.