
7 月 9 日,GOTC 2021 全球开源技术峰会上海站与 WAIC 世界人工智能大会共同举办。在会议上,基于最近一年在公有云上支持 AI 场景客户的经验,进行了题为“公有云上构建云原生 AI 平台的探索与实践”的技术分享,介绍了 AI 类业务在公有云上的现状以及相应的技术选型和面临的问题。最后通过分析开源社区和业界的趋势,与听众分享了我们对于未来全弹性的 AI 基础设施的展望。接下来就回顾一下此次分享中的主要观点。
背景与现状
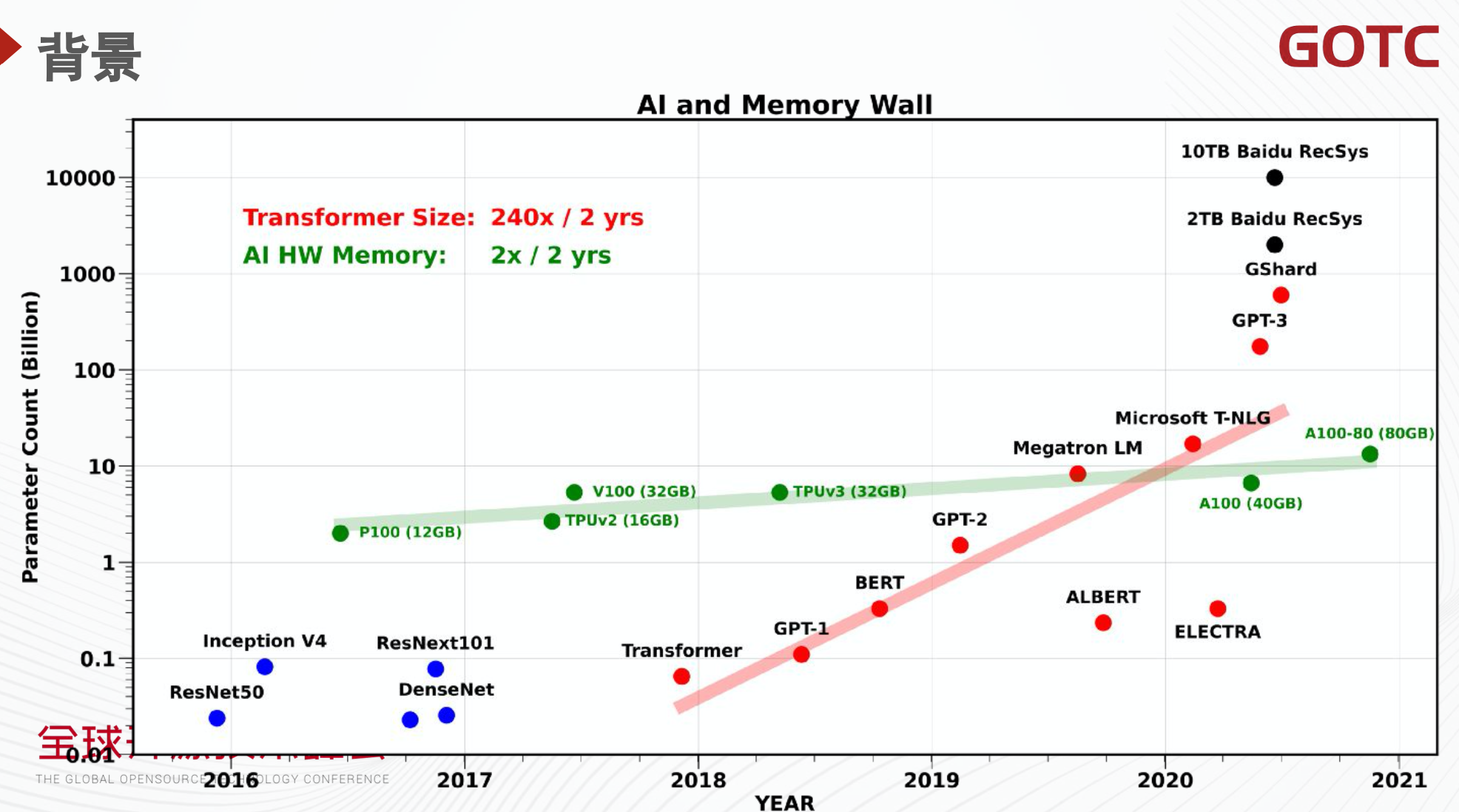
深度学习发展至今,新的模型结构层出不穷。自 2018 年 GPT-1、Bert 相继问世,模型结构的参数量呈指数级增长。目前 Transformer 等结构不仅在自然语言处理领域发光发热,在计算机视觉等领域,也呈野火燎原之势。由此可见,未来对于算力和显存的需求会越发强烈。而以 Nvidia 为代表的硬件厂商提供的硬件性能却并不能与之同步提高。上图展示了两者之间的鸿沟,红色线条是模型参数规模的变化趋势,目前正在以每年 120 倍的速度提升。而绿色线条代表的显存容量每年提高的速度只有 2 倍。
因此,无论是在计算机视觉、自然语言处理等领域,还是互联网行业落地广泛的搜索广告推荐领域,分布式训练都成为了主流训练方式。

与之相对应的,深度学习框架也呈百花齐放的态势。传统的框架如 TensorFlow、PyTorch、Keras 仍然十分流行。而一些新的框架也逐渐出现,比如微软的 DeepSpeed、百度的 Paddle 等。

总结来说,目前 AI 在工业界的各个领域都有了广泛的落地。传统的搜索广告推荐领域自不必说,在视觉与自然语言处理领域,基于深度学习的方法已经成为了 state-of-art。在游戏、机器人等领域,强化学习也在慢慢走向生产。为了满足业务对复杂模型的需求,新的硬件和框架层出不穷。当然,还有一个非常明显的趋势,不少 AI 类业务正在上公有云,希望借助公有云的弹性计算能力降低算力成本,提高效率。
在公有云上的 AI 落地

接下来,我们介绍一下在服务公有云上的客户时关于云原生 AI 的一些观察。
基于公有云的云原生 AI 目前正在逐渐落地,其中既包括稀疏类的搜索/广告/推荐业务,也包括稠密类的计算机视觉等业务。互联网领域的推荐场景落地相对较多。也正是由于搜索/广告/推荐业务场景复杂,端到端延迟要求低,因此改造的成本相对较高,所以大多数业务,尤其是离线训练过程,仍然不能很好地利用云的弹性能力。 与此同时从深度学习框架的角度看,目前绝大多数的业务仍然在使用 TensorFlow。这与之前的观察有一定的相关性。搜索/广告/推荐业务中 TensorFlow 仍然占据了绝对的市场。但是目前 PyTorch 的使用也越来越多,尤其是在计算机视觉、自然语言处理等领域。
落地实践
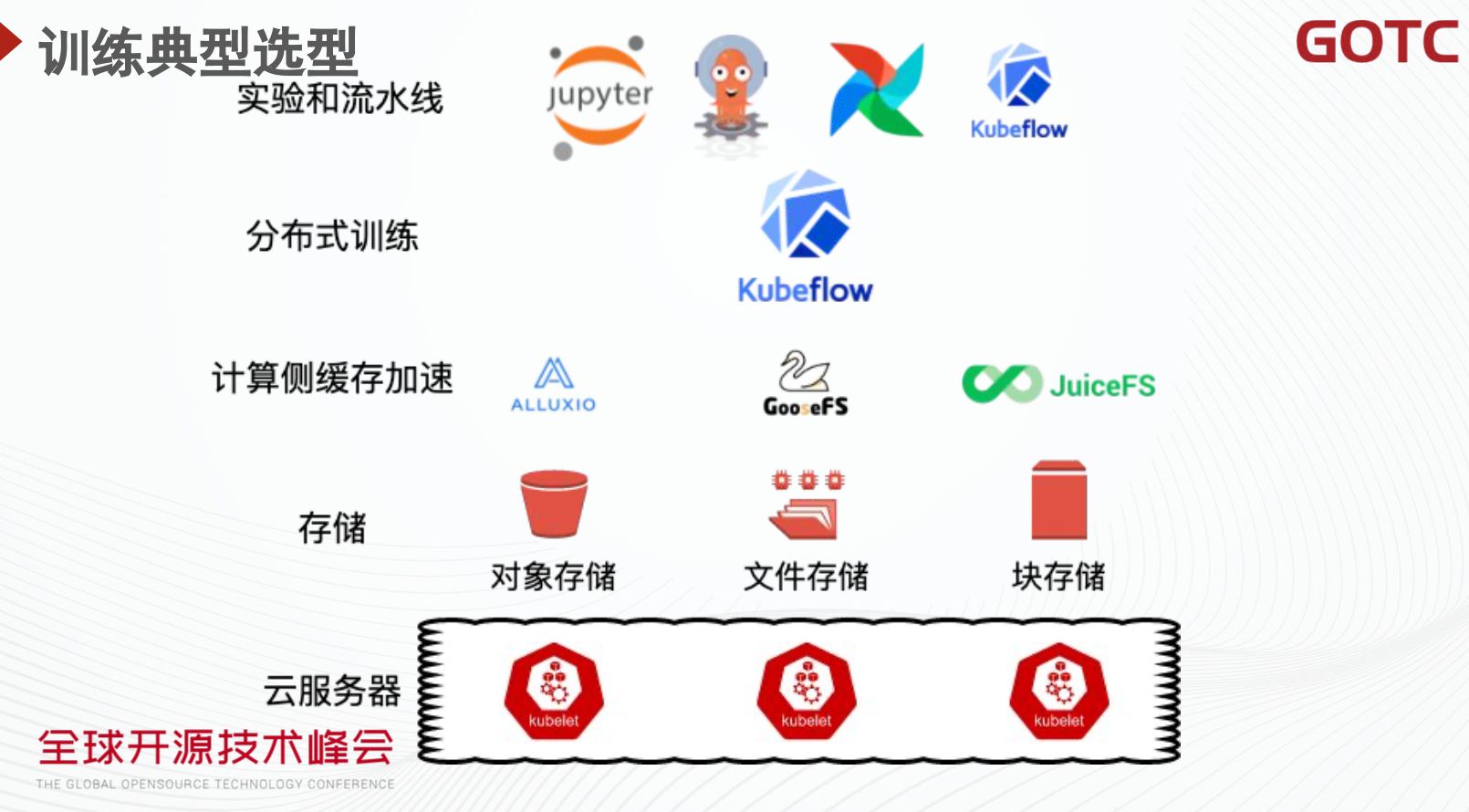
在介绍完公有云的 AI 云原生落地情况后,我们分享一下在公有云上运行 AI 类业务的典型选型。首先是训练相关的技术栈。首先,在最底层的云服务器侧,一般而言是由云厂商提供的虚拟机或者裸金属机器。目前大部分业务都采用 Kubernetes 容器服务,所以一般计算侧会将服务器组成 Kubernetes 集群进行资源管理和调度。在其上,一般会依赖对象存储、文件存储或者块存储进行训练样本和模型的存储。一般而言在读写压力不太大的场景下,大多使用对象存储。相比于其他方式,对象存储支持分层压缩归档,性价比高。在读写压力比较大的场景,文件存储和块存储有更多的落地。
为了能够尽可能提高数据的吞吐,有时会利用一些计算侧的缓存进行加速。其中的选型包括 Alluxio 和腾讯云对象存储缓存加速产品 GooseFS 等。通过把远端的数据缓存在计算侧集群中,避免了远端拉取数据的开销,在某些场景下能够显著地提高训练速度。
构建在服务器和存储之上的是分布式训练的基础设施。目前 Kubeflow 被应用地最为广泛。通过 Kubeflow,用户可以轻松地创建出 TensorFlow、PyTorch、Horovod 等框架的分布式训练任务。并且 Kubeflow 可以很好地与 Kubernetes 的各种特性协同工作,能够支持 Volcano 等调度器。
尽管 Kubeflow 已经能够支持用户进行模型的训练和评估,但是直接使用 Kubeflow 仍然具有一些问题。不同的数据依赖可能在不同的数据系统中,因此数据处理的逻辑可能非常复杂。为了简化算法工程师的使用流程,提高用户体验,一般在上层会构建一个流水线系统,用来将机器学习流程中的各个环节进行组合连接。同时会提供方便的可编程环境,帮助算法工程师更快地实现业务。在这一环节中,一般来说可选的系统包括 Jupyter、Argo Workflow、Airflow、Kubeflow 等。从用户的角度看,算法工程师只需要关心最上层的实验环境和流水线系统。而其下的各层 Infra 则由基础设施团队和公有云提供。这样的分层能够降低不同角色的工程师的心智负担,提高效率。
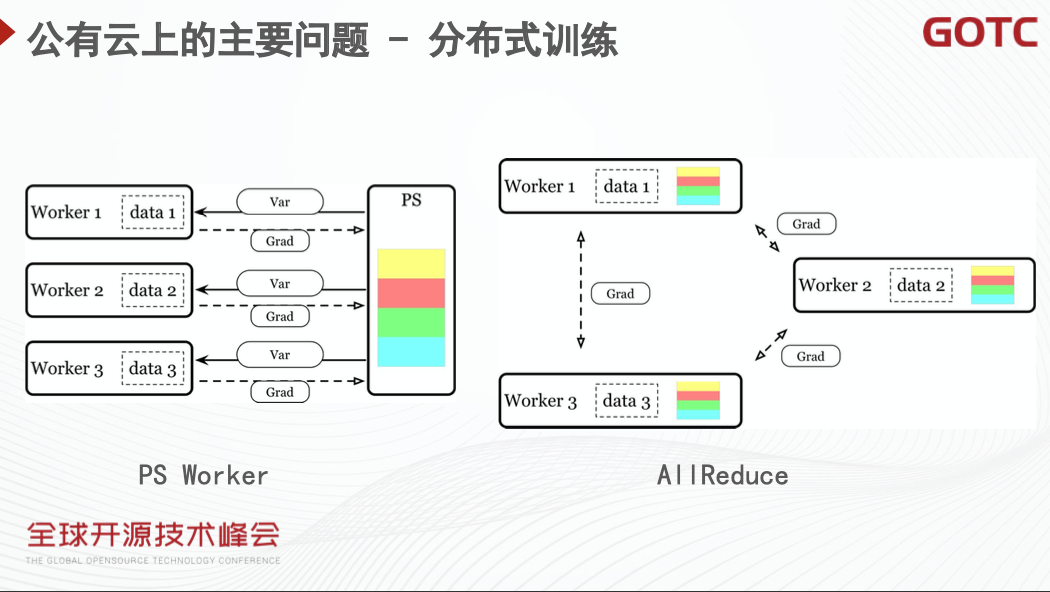
接下来,我们就以分布式训练为例,介绍选型中可能遇到的问题,以及解决办法。在分布式训练中,按照参数更新的方式不同,可以分为 Parameter Server(以下简称为 PS)Worker 的模式和 AllReduce 的模式。在 PS 模式下,一共有两个角色参与训练,分别是 PS 和 Worker。其中 Worker 负责主要的计算,计算好的梯度会发送给对应的 PS,PS 更新对应的参数,随后发回给 Worker。在 AllReduce 模式中,每个 Worker 中有全量的模型,不同 Worker 接受不同的数据,相互之间传递梯度,进行梯度的更新与同步。

无论上述的哪种训练方式,都存在一些问题。首先是在模型参数较多的情况下,梯度或参数通信时的网络带宽需求很高,网络会成为训练过程中的瓶颈。这一问题在稠密类模型的训练中尤为明显。其次,在一个运行深度学习任务的集群上,往往运行着多个深度学习任务。不同的任务都需要访问存储,这时存储带宽也可能成为瓶颈。总结起来,在网络和存储上,都有可能遇到带宽不足的问题。
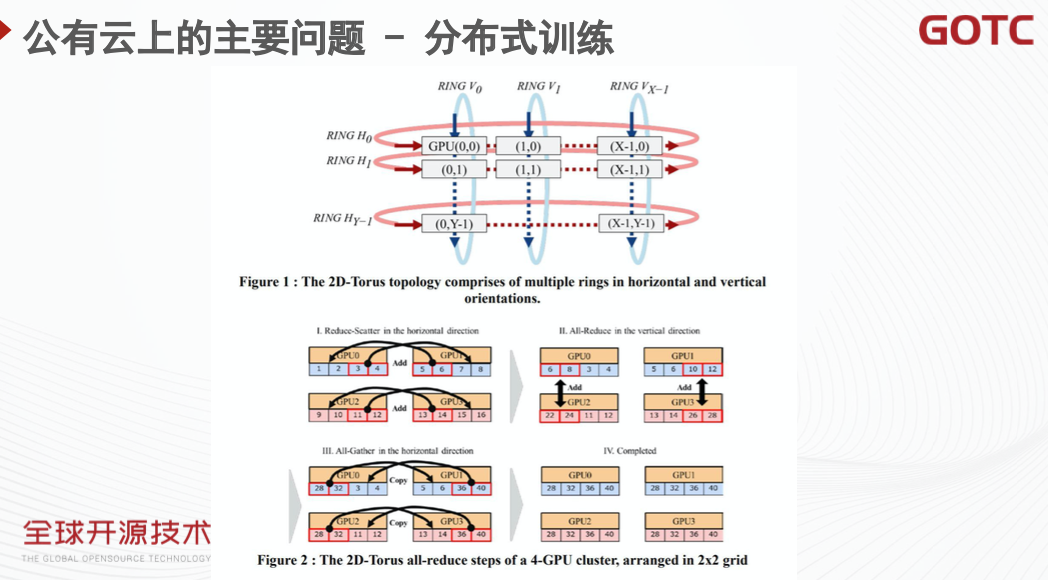
在公有云上,通常云服务器不提供 RDMA 网卡,内网带宽通常在 20-50Gbps 左右。在这样的环境下,为了能够降低梯度同步带来的带宽压力,一般会需要进行梯度压缩等优化。梯度压缩可以降低单次同步的梯度大小,与此同时,也可以替换 AllReduce 的实现,选择对低带宽环境更为友好的实现,如 2DReduce 等。这些工作在腾讯云的 Ti-Horovod 中都有对应实现。它在低带宽的情况下会有比原生的 Horovod 更好的表现。
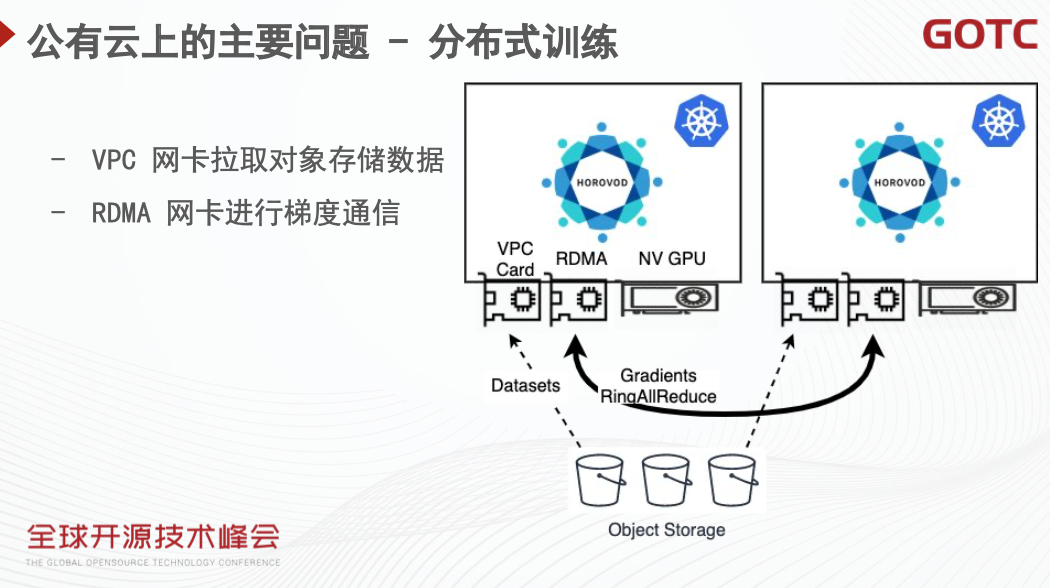
而如果在裸金属等服务器上进行训练,则可以利用 RDMA 网卡进行梯度的加速。在这样的训练环境中,存在一张 VPC 网卡,用于与对象存储等云产品交互;一张 RoCE 网卡以及一个显卡。因此需要进行一定的改造,来支持通过 VPC 网卡进行训练样本的拉取,而梯度同步更新则通过 RDMA 网卡进行。
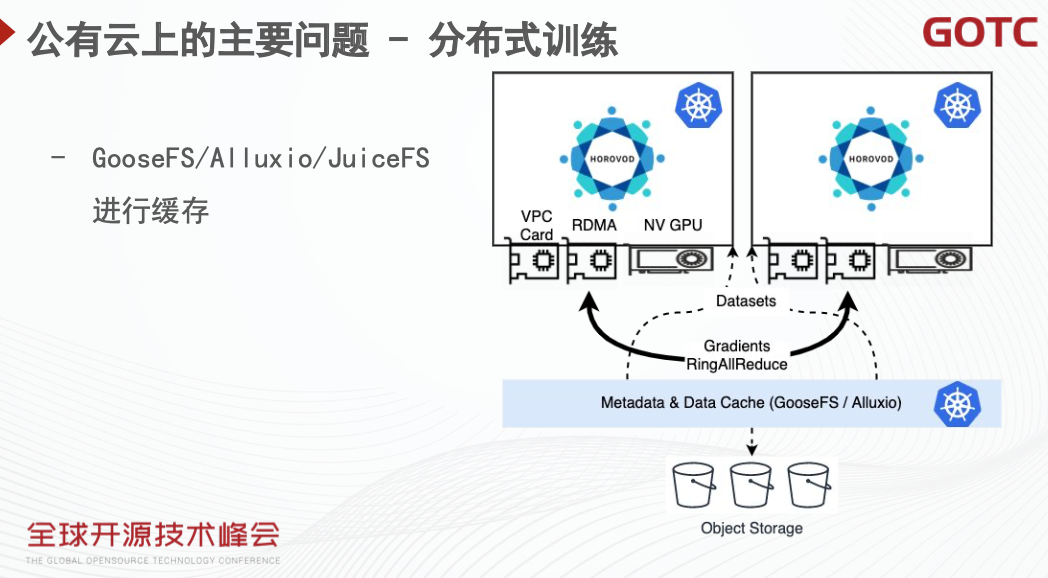
而这样的方式,会有比较高的概率遇到之前所说的存储带宽的问题。梯度的同步通过高带宽的 RDMA 进行了加速,相对应地存储上就更有可能成为瓶颈。为了解决这一问题,在公有云上可以利用计算侧的缓存产品,如腾讯云的 GooseFS,或者开源的 Allxuio 等方案,将数据缓存在集群内,避免在训练时在线拉取对象存储中的数据,避免存储带来的瓶颈问题。
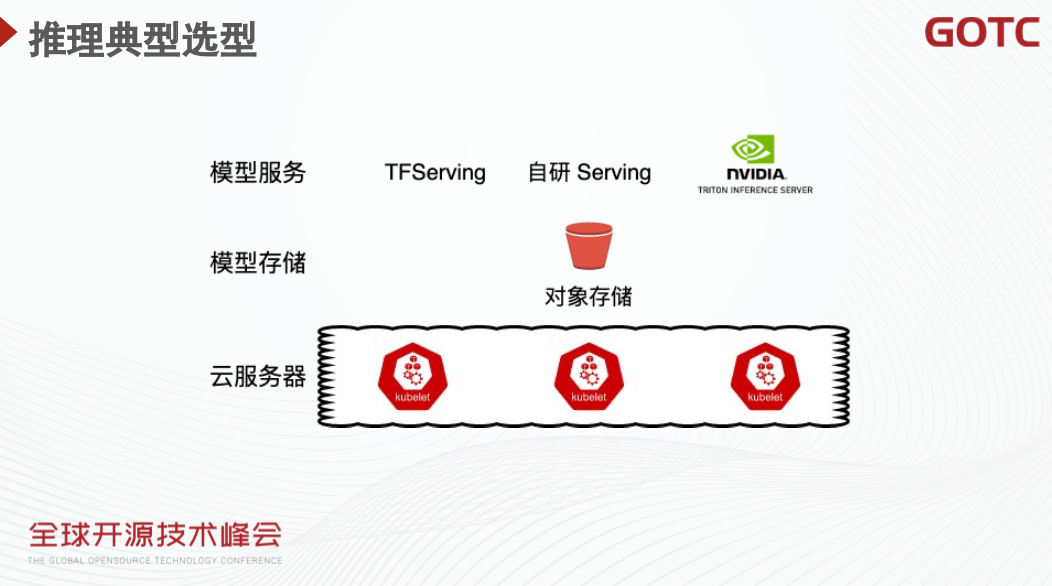
在推理场景下,架构相对更为简单。最底层依然是云服务器组成的 Kubernetes 集群,模型一般而言会存储在对象存储中,模型服务则会通过 TFServing、Triton Inference Server 或者自研服务框架的方式对外提供服务。
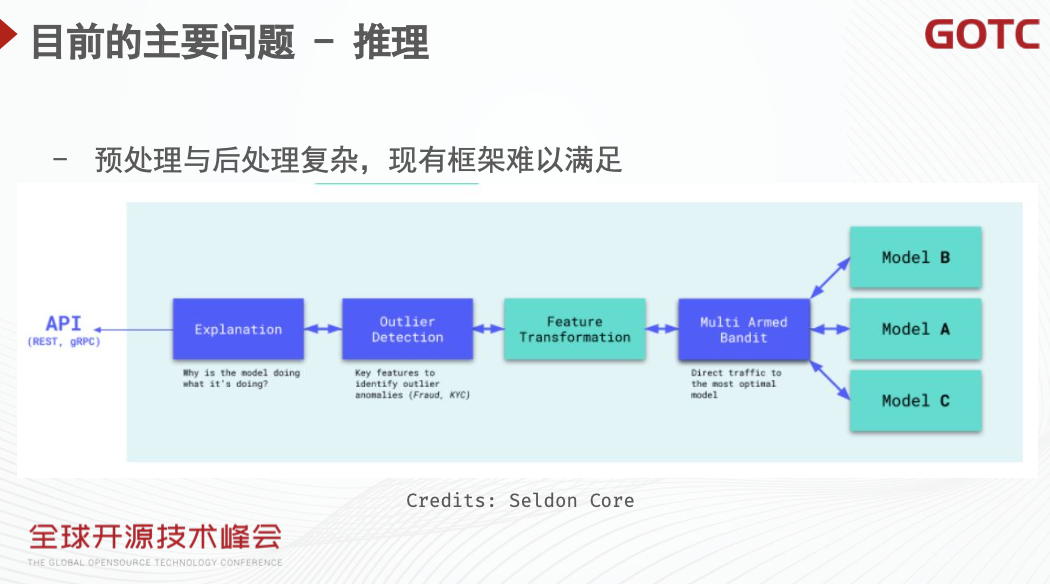
由于部分业务的端到端流程相对复杂,有繁复的前处理和后处理环节。如果使用 TFServing 或者 Triton Inference Server来实现,逻辑会尤为复杂。与此同时,模型服务会与内部的基础设施有耦合,需要对接内部的网关等服务。因此自研服务框架的需求也相对旺盛。尽管 TFServing 和 Triton Inference Server 在开源领域广受关注,但是目前仍有相当规模的业务使用自研服务框架。
未来展望
AI 业务在上公有云的过程中,有各种各样的问题。在通信、存储侧的带宽瓶颈自不必说。除此之外,深度学习往往依赖 Nvidia 的诸多底层库,以及 Python 的各类依赖。在集成环境中,Jupyter 占用的 GPU 显存以及计算的利用率过低等。
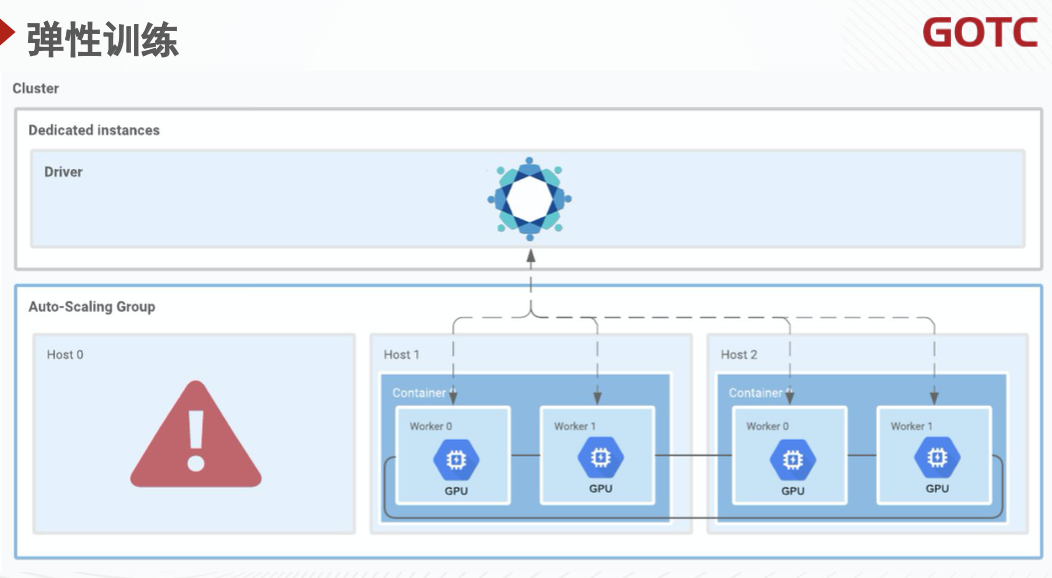
基础架构的演进也一定会朝着解决这些问题的方向前进。我们认为,未来的 AI 基础设施一定是全弹性的。在训练场景下,原本的训练方式需要将参与训练的各个角色的配置固定下来。比如由 5 个 Worker 参与的分布式训练任务,在训练过程中需要保证有且仅有 5 个 Worker 参与。这使得资源的配置只能静态地指定,在集群资源情况发生变化时无法动态地调整参与训练的 Worker 数量。
目前,能看到有越来越多的深度学习框架正在支持弹性训练。以 Horovod 为例,它引入了 Driver 的概念,管理 Worker 的生命周期。当有任何一个 Worker 出现问题时,Driver 会捕获到异常并且根据配置重新建立环,让训练继续下去。在这一过程中,训练不会中断。这使得训练任务可以在集群负载低,有空闲 GPU 的时候扩容,在集群负载高的时候缩容。这样的架构能够结合公有云的弹性实例等能力,在提高容错性的同时,降低训练的成本。
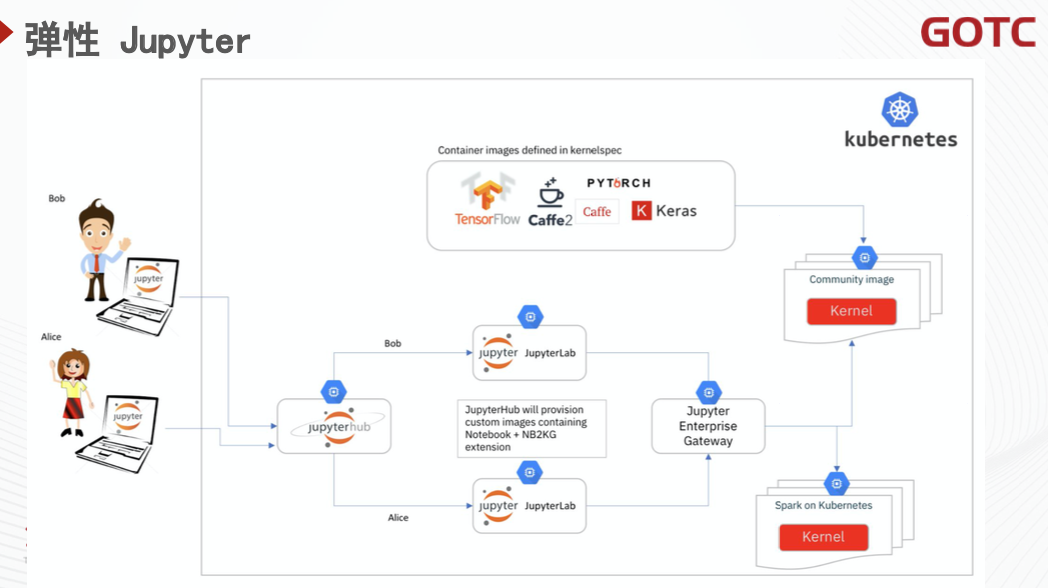
与之相似的,还有弹性的 Jupyter 能力。在 Jupyter 原本的实现中,每个 Kernel 都是与 Notebook 运行在一起的,这也就意味着它需要长期占有一张完整的 GPU 卡,这同样使得 GPU 的利用率得不到提升。Jupyter 在卡的使用上如果能够做到按需申请使用,也一定会进一步地提高集群的资源利用率,降本增效。
总结

最后,我们总结本次分享的主要观点。目前公有云的内网带宽仍然是制约 AI 业务上云的一个主要问题。我们针对不同的场景有不同的方法可以缓解它,也有包括裸金属在内的 RDMA 方案可供选择。相信在未来随着公有云网络带宽的逐步提升,这将不再成为问题。
其次,工业界目前仍然缺乏 AI 基础设施的事实标准。目前有非常多的开源 AI 基础设施项目,其中 Kubeflow 是落地最多的,凭借着与 Kubernetes 的深度集成,与公司内部现有的基础设施能够更好地协同工作,有一定的优势。不过整体而言,目前这一领域仍然缺乏事实标准。各个系统之间的差异非常大。这也是目前这一领域最大的问题之一,各个公司的 AI 基础设施都各有特色,难以像集群调度领域 Kubernetes 一样,在社区形成合力,共同推动行业进步。
最后,全弹性的架构是我们认为的下一步演进方向。目前在 AI 业务中还不能很好地利用弹性能力,而这是云计算带给我们最大的红利。只有依托真正的弹性架构,应用才能生于云上,长在云上,服务于企业降本增效的终极目标。
License
- This article is licensed under CC BY-NC-SA 3.0.
- Please contact me for commercial use.