
最近假期有时间,跟几个做 Agent 的朋友聊天,他们都提到了一个共同的问题:负责决策规划的主 agent 需要维护一个状态机来追踪环境状态和行为。这个状态机通常是文本格式,记录各种状态、事件和转移规则,主 agent 根据 subagent 的输出来更新它并做决策。
现实中经常出现两个问题。首先,主 agent 一旦发现 subagent 的输出不符合预期,就容易自己出手去执行,结果导致人格漂移,自己代入到 subagent 的角色里去了,忘了自己应该做什么——这可能是指令依从的问题。其次,主 agent 经常会丢失之前的状态记忆,导致状态机的状态不准确——这可能是上下文窗口不足的问题。
于是我自然而然想到,能不能通过后训练,让模型学会一个状态机的形式化描述。主 agent 其实是整个架构的瓶颈——所有决策都要它来做,所有的信息流都是同步的,subagent 的输出全部要喂给它,它的输出又要喂给其他 subagent,根本没法 streaming。这样一来效率就很低。
要是能训练一个小模型,比如 3B、7B,专门去学怎么描述和更新状态机,那主 agent 就能专注于决策规划,不用老是想着接管 subagent 的工作。而且作为系统的性能瓶颈,主 agent 本身用小模型推理也会快很多。
决定场景后,我开始研究是 SFT 还是 RLHF。因为之前没有过经验,我发现自己很难判断哪个更适合这个任务。而且这个场景还涉及到要预先定义一个状态机的形式化描述,这个描述本身就很复杂,可能需要一些专业知识来设计。问题对于第一次训练的我来说有点过于复杂。于是我决定先换个问题,先从一个更简单的任务开始,来体验一下后训练的过程。
Vibe coding agent
于是我随便选了一个 idea,花了一个小时的时间,vibe coding 了一个辅助 A 股投资的 agent。这个 agent 的功能很简单,就是根据用户输入的股票代码,返回该股票的基本信息、历史价格,以及一些技术指标。具体的 tool 就像下面这样:
# 工具使用指南
## 可用工具概览
### 🔍 股票搜索工具
**search_stock_by_name(stock_name)** - A股名称搜索
- 用途:根据A股股票名称搜索股票代码
- 何时使用:用户只提供A股公司名称,不知道代码时
- 示例:`search_stock_by_name("茅台")` → 找到 600519
### 📋 基础信息工具
**get_stock_info(stock_code)** - A股基本信息
- 用途:查询A股股票的公司信息、上市信息、主营业务等
- 何时使用:用户首次询问某只A股股票时,或需要了解公司背景时
- 示例:`get_stock_info("600519")` → 获取贵州茅台的基本信息
### 📊 实时行情工具
**get_realtime_quote(stock_code)** - A股实时行情
- 用途:获取A股股票当前的实时价格、涨跌幅、成交量等
- 何时使用:用户问A股"现在多少钱"、"今天涨了吗"等
- 示例:`get_realtime_quote("600519")` → 获取茅台当前价格(人民币)
- 返回:当前价、涨跌额、涨跌幅、今开、最高、最低、昨收、成交量、成交额、换手率、市盈率、市净率
...
### 📈 历史数据工具
**get_kline_data(stock_code, k_type="日线", start_date="")** - A股K线
- 用途:获取A股历史K线数据,用于分析趋势
- 何时使用:需要查看A股历史走势、画K线图时
- 参数:
- k_type: "日线"、"周线"、"月线"
- start_date: "2024-01-01" 格式
- 示例:`get_kline_data("600519", "日线", "2024-01-01")`
...
### 📐 技术指标工具
**calculate_ma(stock_code, periods="5,10,20,60", start_date="")**
- 用途:计算移动平均线(MA5, MA10, MA20, MA60)
- 何时使用:技术分析,查看均线支撑/压力位
- 示例:`calculate_ma("600519", "5,10,20,60")`
**calculate_macd(stock_code, short_period=12, long_period=26, signal_period=9)**
- 用途:计算MACD指标,判断趋势强度和买卖点
- 何时使用:需要确认趋势转折点时
- 示例:`calculate_macd("600519")`
**calculate_bollinger_bands(stock_code, period=20, num_std=2, start_date="")**
- 用途:计算布林带指标,判断股票的波动性和支撑/压力位
- 何时使用:判断价格可能的涨跌幅,找支撑压力位
- 示例:`calculate_bollinger_bands("600519", 20, 2)`
**analyze_volume_trend(stock_code, period=20, start_date="")**
- 用途:分析股票的成交量趋势,判断价量关系和市场参与度
- 何时使用:确认趋势真实性,判断主力资金进出
- 示例:`analyze_volume_trend("600519", 20)`
...

Vibe coding 这个 agent 的过程也非常有趣,因为涉及到多轮的交互和工具调用,虽然只是个单 agent 的实现,但是调试起来也特别麻烦。模型中间哪一轮出了问题,都会导致最后的输出不正确。
这个也是为什么 multi-turn RL 难训练的原因之一,最后的奖励 credit 到底是哪一轮对话贡献最大,或者说是哪一轮工具调用贡献最大,都是很难判断的。跟望哥交流他提到微软有个工作是每个 step 都能够有一个稠密的 reward 来指导训练,而不像现在这种 sparse reward 的情况,只有最后的结果是对的或者错的,导致训练非常困难,我挺上去感觉确实是很好的思路。
回到这个 agent 的实现,为了解决调试难的问题,我开始找有没有用来做调试的工具,结果发现了岛娘在月之暗面开源的 MoonPalace:
- 简单易用,启动后将 base_url 替换为 http://localhost:9988 即可开始调试;
- 捕获完整请求,包括网络错误时的“事故现场”;
- 通过 request_id、chatcmpl_id 快速检索、查看请求信息;
- 一键导出 BadCase 结构化上报数据,帮助 Kimi 完善模型能力;
这个工具非常适合调试 agent 的问题,因为它能够捕获完整的请求信息,包括模型的输入输出、工具调用的参数和结果,以及网络错误等情况。通过 request_id 和 chatcmpl_id,我可以快速定位到哪一轮对话出了问题,查看具体的请求信息,分析模型的行为。但是比较可惜,岛娘说没有动力支持更多模型。虽然它应该是兼容 OpenAI API 的,但我也没继续尝试了。
我觉得目前还非常缺乏一个帮助开发者 troubleshoot agent 的工具,尤其是对于 multi-turn 的 agent 来说,调试起来非常麻烦。我们需要一个类似于 GDB 的 debugger,能够让我们在每一轮对话中查看模型的输入输出、工具调用的参数和结果,以及记忆状态等信息,同时能够决定 hang 在哪一轮对话,修改模型的输入输出,来帮助我们更好地理解模型的行为和调试问题。
期间我又去试了试 litellm,但它更像是一个网关,不是为了调试 agent 设计的,登录它的 dashboard 还需要一个 postgres 数据库,感觉有点重了。
于是我就又为了调试这个 agent,vibe coding 了一个简单的 debugger。这个 debugger 只花了半小时左右的时间,它能够把每次的请求信息存到 sqlite 数据库里,OpenAI 的 chat completion API 的请求和响应都被记录下来,可以根据时间查询。
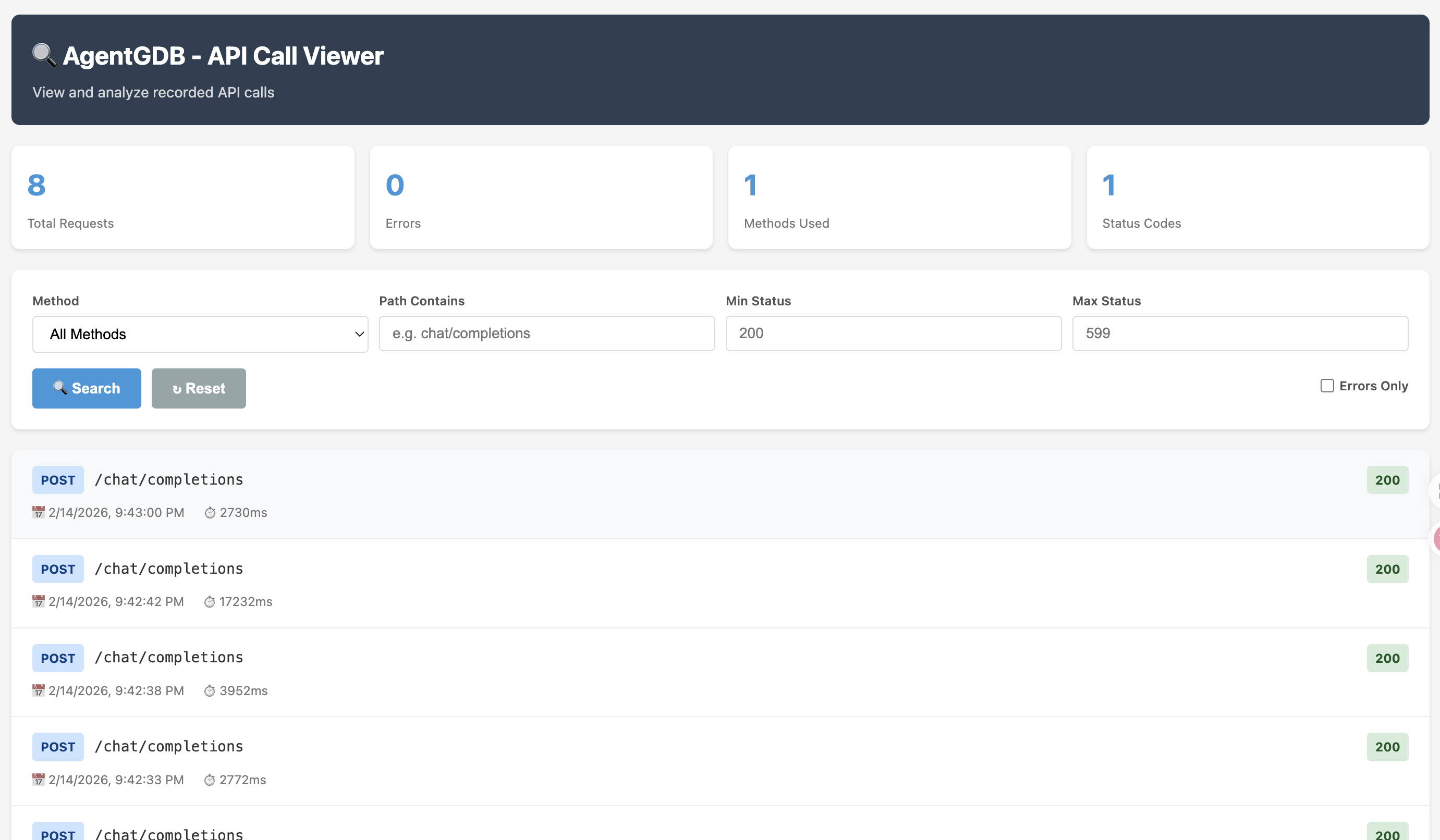
Vibe coding 有一种魔力,让你快速地把一个想法实现出来,虽然可能不够完美,但能够满足 90% 的需求。会让人沉浸于不停构建新东西的快感中,完全不想停下来去做其他的事情。而且遇到了问题,就又想去 vibe coding 一个工具来解决问题,这样就形成了循环。
SFT
这个 agent 最开始是直接 ReAct 来实现的,用 deepseek-chat 工作的非常好,完成率能够在 80% 以上。用户输入一个股票代码,agent 就会调用工具来获取信息,然后返回给用户。换了 7B 小模型之后,完成率掉到了 60% 左右。尤其是在需要区分港股和 A 股的场景下,模型经常会搞混,导致调用了错误的工具。
后训练的机会就来了。我想先 SFT 试试看。作为 Infra 哥,我第一件事就是先去看了 verl 和 slime 这两个后训练的框架。望哥在 Seed 有参与过 verl 的工作,我在搞 agent 的时候也一直在请教他。slime 本身是我们在腾讯交流蛮多的前同事 Zilin Zhu 参与设计和开发的,还挺有缘份。
至今还没研究很明白这两个框架的区别和适用场景,但我看到 verl 做 SFT 不需要依赖 Ray,直接 torchrun 就够了,而 slime 做 sft 需要 ray,我就想先试试 verl。虽然我觉得 Ray 挺有趣的,20 年就写文章讲过它,但它本身也是个挺复杂的系统,万一遇到了什么问题,会更加麻烦。
接下来就是计算一下需要什么样的显卡来训练。7B 的模型,本身 16 位参数占 14GB,梯度 14GB,优化器存动量、方差、参数 32 位,7B * 4 * 3 = 84GB,一共 112GB 左右。FSDP 可以通过分片的方式降低显存需求,比如说分成两片,也就是每张卡 56GB。同时 FSDP 还可以 CPU offload,参数和梯度不用的时候 offload 到 CPU。并且还有 gradient checkpointing,反向传播时不保存中间激活值,需要重新计算前向传播来节省显存。所以 GPT 告诉我两张 24GB 的卡就够了。
我最开始找了一个双 L4 的机器,结果跑不起来。我因为一直就怀疑显存太少,所以换了一个四卡 L4 的机器,可以运行。但是我后来才发现最开始我 gradient checkpointing 没开,所以双卡能不能跑起来我也不确定了。
对于训练的数据库,我是用 deepseek 生成了 1000 条左右。每条数据包含用户输入的股票代码、模型调用工具的日志(包括调用了哪个工具,传了什么参数,得到了什么结果),以及模型最终返回给用户的输出。训练完之后惊喜地发现,tool use 的水平提高了,但是模型中间的推理变弱了。还是回到区分 A 股和港股这个问题上,模型虽然学会了调用正确的工具,但在推理过程中经常卡在某个环节要确认好多次。比如要来回确认是不是港股,确认后拿到工具返回,就又当成 A 股,还要下次再分析推理确认一次。
我以为是我训练数据构造的有问题,我又 SMOTE 过采样了一下,生成了相对强调推理的 500 条训练数据,从头开始训练。结果推理能力好像强一点了,但是使用工具的能力又不行了。有一篇最近的文章 解释说推理和工具使用的梯度方向不一致,联合训练会互相干扰。
我不确定是不是这个原因,我自己还是感觉构造的数据质量比较低影响了。也可能是我的测试数据构造的太少。
RL
后面我开始尝试 RL,用 GRPO 的方式来训练。verl 来运行 grpo 的训练倒是很简单,只是超参数配了有 50 多个。不过大部分参数都可以从 examples 或者 recipe 里直接抄。
值得注意的是 verl 有很多关于 fsdp 的参数设置,其中又是需要区分是 actor 还是 ref model 的。比如 actor_rollout_ref.actor.fsdp_config.param_offload 和 actor_rollout_ref.actor.fsdp_config.optimizer_offload 这两个参数,还有类似的 actor_rollout_ref.ref.fsdp_config.param_offload 和 actor_rollout_ref.ref.fsdp_config.optimizer_offload,如果资源不够的话,这些参数都需要设置成 True 来开启 CPU offload 来节省显存。但是如果相对充足,那就可以把 actor 的 offload 关掉来提升训练效率,因为 actor 是需要频繁更新参数的,而 ref model 可以开着减少显存占用。
大部分 examples 和 recipe 里都是这样做的,如果要调整的话尽量看一下不要错误地把 actor 和 ref 的参数搞混了,我有一次就把 actor offload 打开了,结果训练效率非常低,后来才发现这个问题。
第一次训练的时候发现 reward_std 很低,frac_reward_zero_std 很高,说明几乎所有回答质量相同,模型不学习。我又开始研究怎么样生成好的数据。修改后好了一点,但是组内数据的方差还是不够大。于是我去请教 GPT 老师,它教给了我很多方法。
比如 NGRPO(虚拟满分样本),在计算组内统计量时,添加一个虚拟的满分样本作为参照点。这样可以强行拉大 reward 的方差,能把训练继续下去。还有 WDB-GRPO(加权动态基线),移除标准差归一化(Dr.GRPO)等等。
最后我决定实现一下 NGRPO,因为它相对来说比较简单。AI 老师帮我写了代码,我又对照着 nangongrui-ngr/NGRPO 这个开源的 verl NGRPO 实现检查了一遍,发现 AI 老师写的是又快又好。
后面的训练效果也确实好了很多,训练好的模型在测试集上的表现提高到了 85%,跟 deepseek-chat 的表现差不多了,而它只是个 7B 小模型。
到这里就差不多了,放假几天根本没有停下来,完全沉浸在这个炼丹实验中,虽然这个实验还很初级,数据构造也比较粗糙,但至少让我对后训练的过程有了一个完整的体验。
最近对什么事情都有点提不起兴趣,也是趁这个机会让自己忙碌起来,记录一下这段时间的断断续续的探索。verl 和 slime 这样的框架真的挺不错的,让 RL 这个门槛挺高的事情变得相对容易了很多,配合 GPT 老师的指导,能够让人快速地开始一些实验。最近我看到 Thinking Machines 的产品 tinker,也是希望降低后训练的门槛,还是蛮有趣的。
Tinker lets you focus on what matters in LLM fine-tuning – your data and algorithms – while we handle the heavy lifting of distributed training.
You write a simple loop that runs on your CPU-only machine, including the data or environment and the loss function. We figure out how to make the training work on a bunch of GPUs, doing the exact computation you specified, efficiently. To change the model you’re working with, you only need to change a single string in your code.
License
- This article is licensed under CC BY-NC-SA 3.0.
- Please contact me for commercial use.