
随着年龄的增加,能够留给自己的时间越来越少。大部分时间都贡献给了工作、家庭和其他各种各样的事务。能够静下心来阅读论文、书籍的机会变得越来越宝贵。这一系列希望能够介绍个人在阅读论文的过程[1]中比较令我印象深刻的论文。不知道能够坚持多少期,且看且珍惜 :-)
今天的文章是 Haystack。它是由 Facebook 发表在 OSDI’10 的一篇文章,主要介绍了 Facebook 的海量图片存储系统。chrislusf/seaweedfs 是对应的开源实现。
之所以选择这篇文章,缘起于 TKE 云原生 AI 团队在每个双周的周五进行的技术交流与讨论。在我熟悉的集群调度领域,近期没有看到亮眼的论文。因此挑选了一篇跟 AI 业务有关系的存储方向的论文。虽然 Haystack 的设计初衷是支持 Facebook 海量图片存储需求,但是在 CV 领域也被广泛地用于存储训练样本。
动机
首先我们来看一下,为什么 Facebook 要专门为了图片存储造一个新轮子。
在典型的用户访问图片数据的场景下的架构。当一个用户访问页面时,首先会向服务器发送 HTTP 请求,获得对应的响应。如果响应中包含着图片的 URL,则会通过新的 HTTP 请求拉取图片。一般而言,对于图片等资源的请求会经过 CDN。如果 CDN 缓存了对应的图片,则直接返回。如果没有则追溯到源服务器,将源图片资源拉取到本地,再返回给用户浏览器。
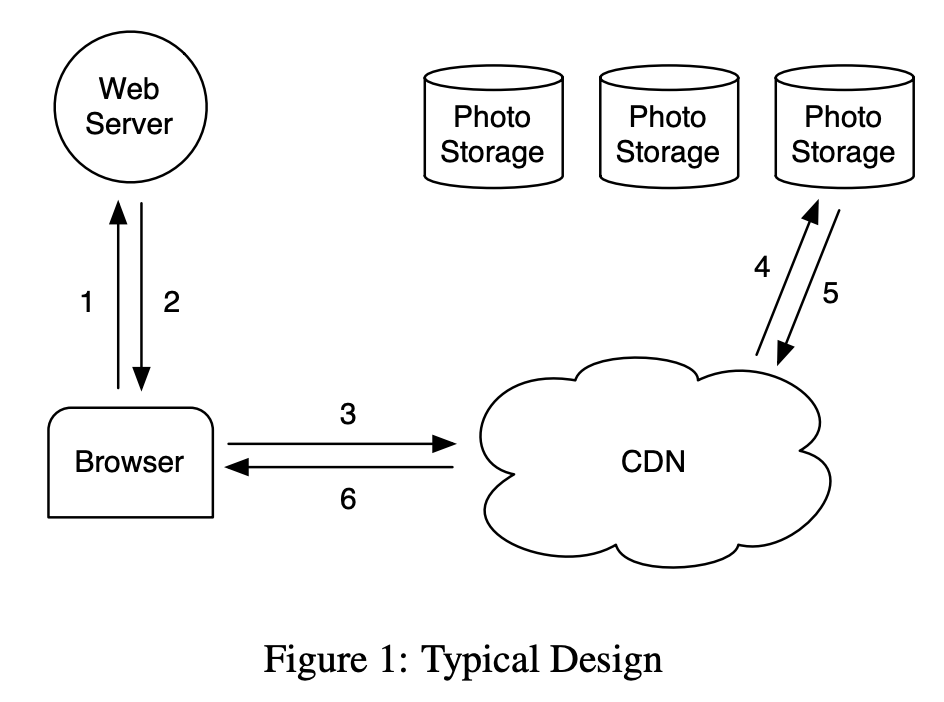
这里也简单介绍下 CDN 的原理。如果没有 CDN,访问一个页面的流程如下:
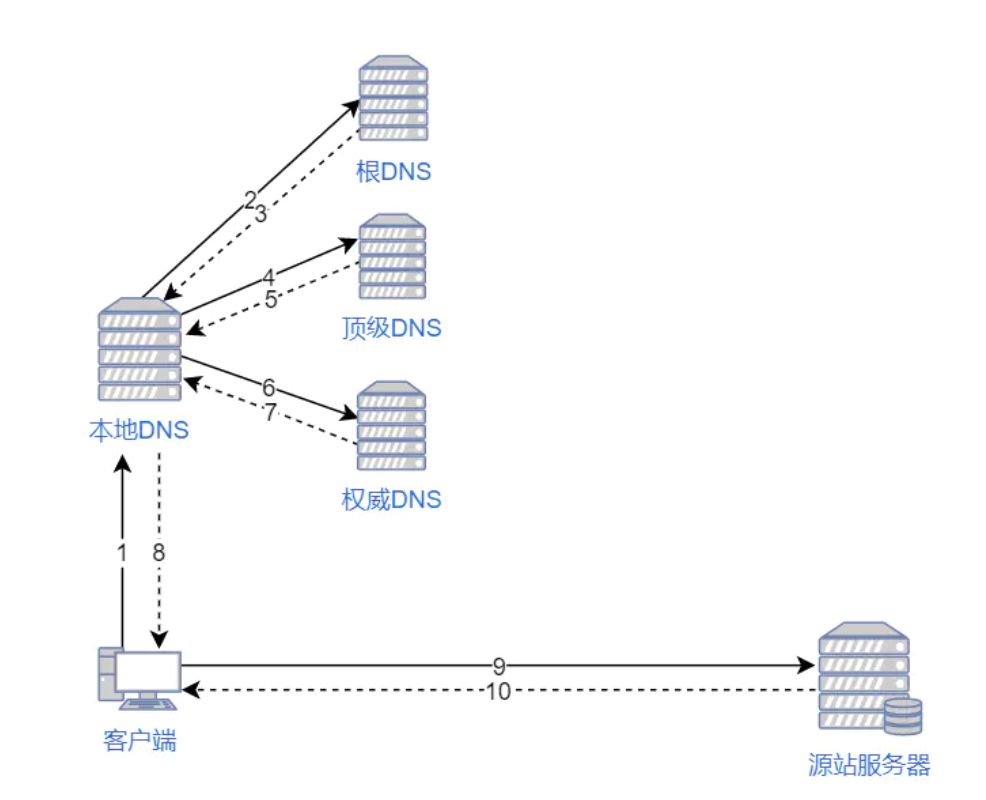
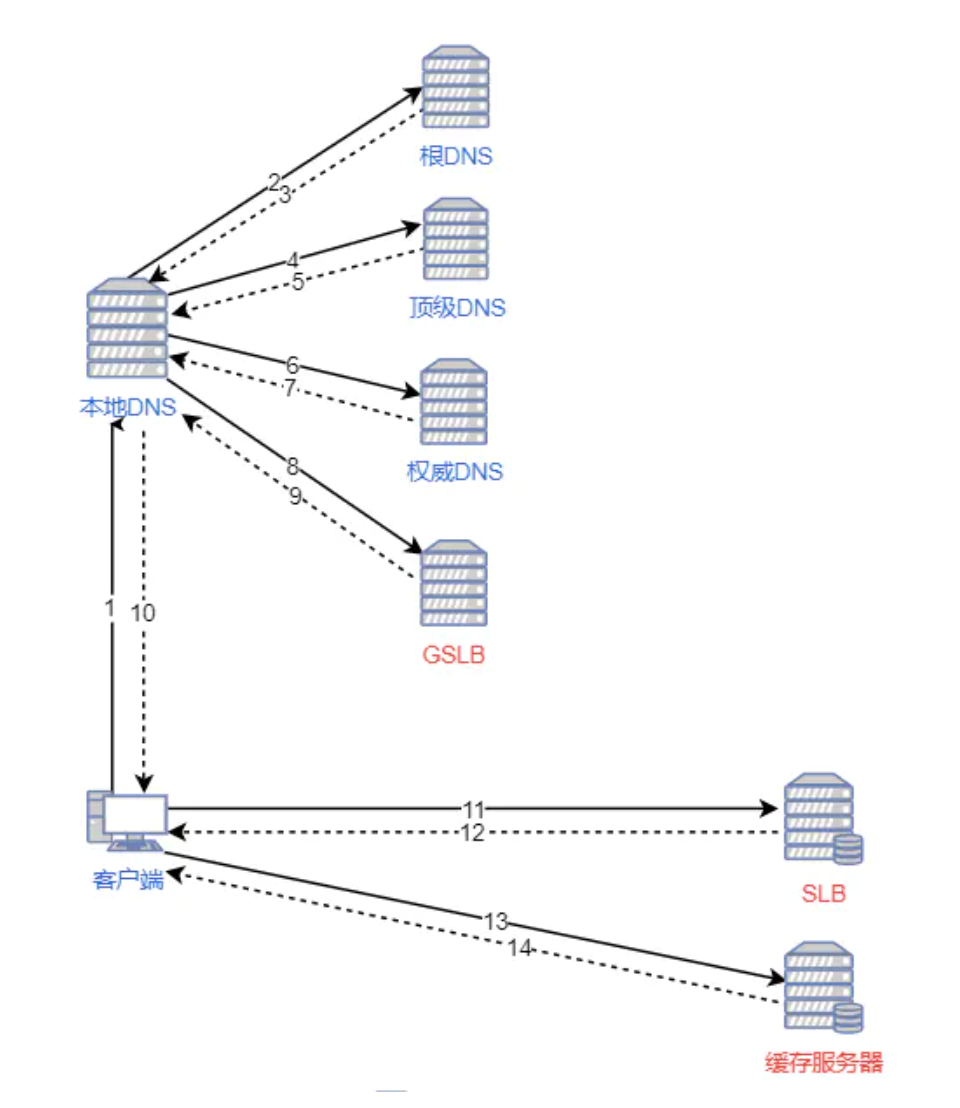
客户端会在本地 hosts 缓存、本地 DNS、根 DNS、顶级域 DNS、权威 DNS 不同层级依次尝试解析。最终解析的结果由本地 DNS 发送给客户端。而如果配合 CDN,需要借助 DNS 轮询时的 GSLB(Global Server Load Balance,全局服务负载均衡) 和 SLB(Server Load Balance,服务负载均衡) 来完成整个过程。GSLB 会根据本地 DNS 的 IP 判断客户端所在的位置,随后解析到距离客户端比较近的 SLB。SLB 会根据集群中负载情况,将请求重定向到对应的服务器上,处理请求。
但是,这样的设计不满足 Facebook 这样的社交网站的访问特点。CDN 能够很好地满足冷热数据明显的场景,热数据可以被缓存在 CDN 中以更快的速度进行分发。但是在社交媒体的场景下,数据的冷热不明显,经常有用户会访问很久之前的图片。因此,Facebook 采取了基于 NFS 的设计。
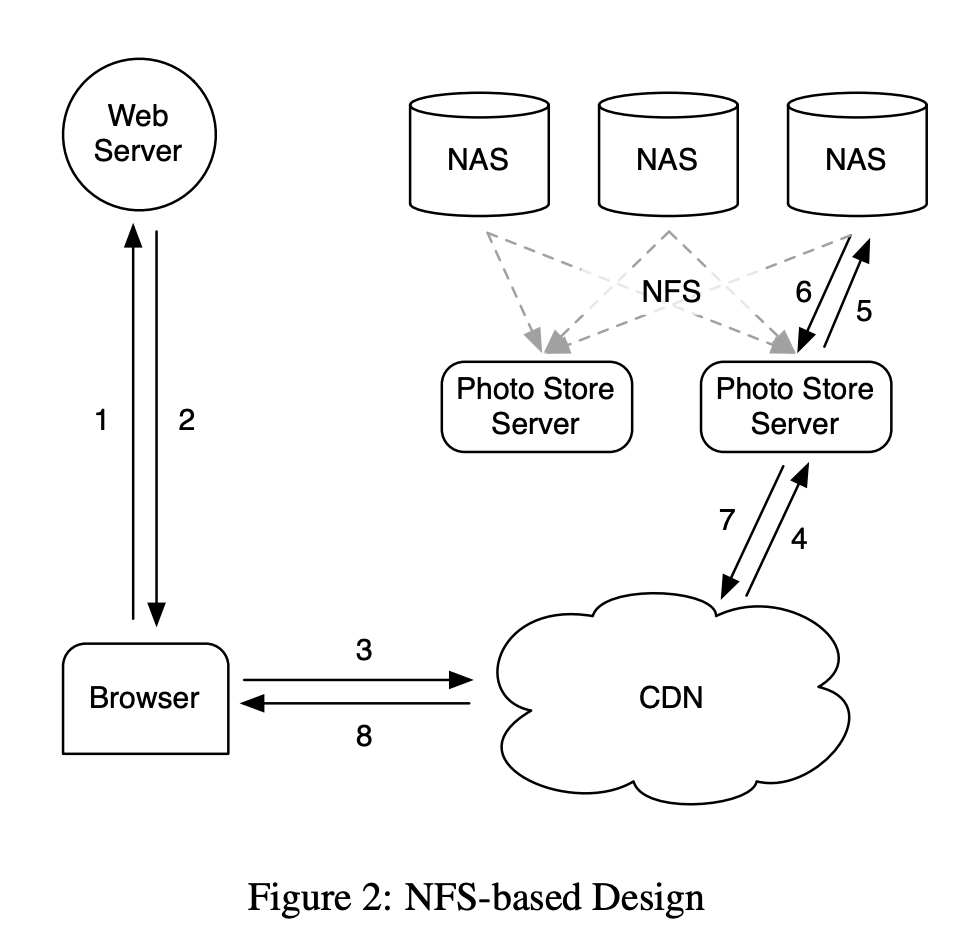
Facebook 引入了一个新的概念 Photo Store Server,图片被存储在其后的网络存储中。每个请求在击穿 CDN 后,会由 Photo Store Server 根据图片所在的卷和全路径,读出数据,返回给客户端。在最早的时候,Facebook 会把图片放在一个卷的目录内。每个目录内大约有数千个图片文件。这样会导致一次文件读有 10 次磁盘操作。将每个目录下的文件数量降低到几百个后,读操作会有 3 次磁盘操作。虽然访问操作的次数减少了很多,但是相比于理论最优情况的 1 次,还有较大差距。
Key Insight
为了能够尽可能降低单次读请求的硬盘访问次数,Facebook 通过实践得到了一个非常重要的观察:在传统的设计中,对于元数据的访问引入了非常多的硬盘操作。如果可以将 metadata 完全放在内存中,避免多次的磁盘访问,单个文件的读操作会有非常显著的性能提升。
系统设计
基于上述的观察,为了实现设计目标,Haystack 主要针对小文件的特性,对元数据和文件本身的存储都进行了重新的设计。在 Haystack 的设计中,一共有三个模块,分别是 Directory、Store 和 Cache。其中 Directory 主要负责对于元数据的管理,Store 是真正存储图片数据的组件。而 Cache 可以理解为是一个内部与 DNS 功能类似的缓存。之所以在有 CDN 之外要额外再引入一个内部 CDN,主要是出于扩展性的设计。在未来可能会放弃对于外部 CDN 的依赖,因此引入了 Cache。
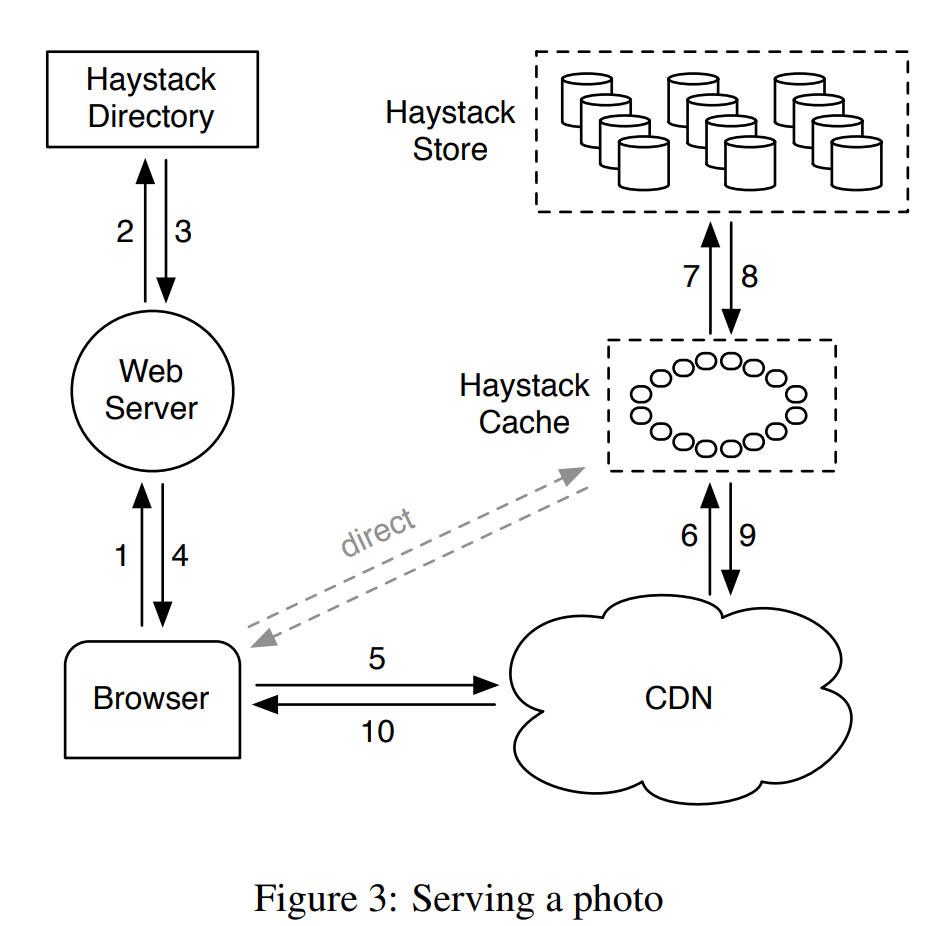
当客户端发起了一次读请求时,首先请求会通过 Directory 服务,获得请求资源的 URL。其格式如下:
<CDN>/<Cache>/<Machine ID>/<Logical Volume> <Photo ID>
这是一个分层次的 URL。首先请求被路由到 CDN 时,CDN 服务器会根据 CDN 和 Photo ID 等信息尝试寻找缓存,如果缓存失效,则会去除前面的 CDN 路径,将剩下的 URL 转发给 Cache。如果 Cache 也没有命中,则根据 Machine ID 路由到对应的 Store,根据 Logical Volume 和 Photo ID 从硬盘上读出来。
为了避免元数据带来的硬盘操作,Haystack Store 将小的图片文件进行了合并。Store 管理着多个 Physical Volume(以下称为 PV),每个 PV 可以被当作一个大文件,存储着数百万的图片。为了容错性,多个 PV 会组成一个 Logical Volume(以下称为 LV)。这一映射关系是由 Directory 负责管理的,因此只需要提供 LV 的 ID,以及对应图片在 PV 中的 offset 和 size,就可以定位到一个图片,而不需要多余的元数据操作。由于 PV 在一个 Store 上的数量并不多,因此它的 file descripters 可以长期保持打开的状态。同时 Store 会在内存里维护一个 PhotoID 到图片的 offset,size 的映射关系,通过这一关系可以把 PhotoID 直接转换为图片的位置。
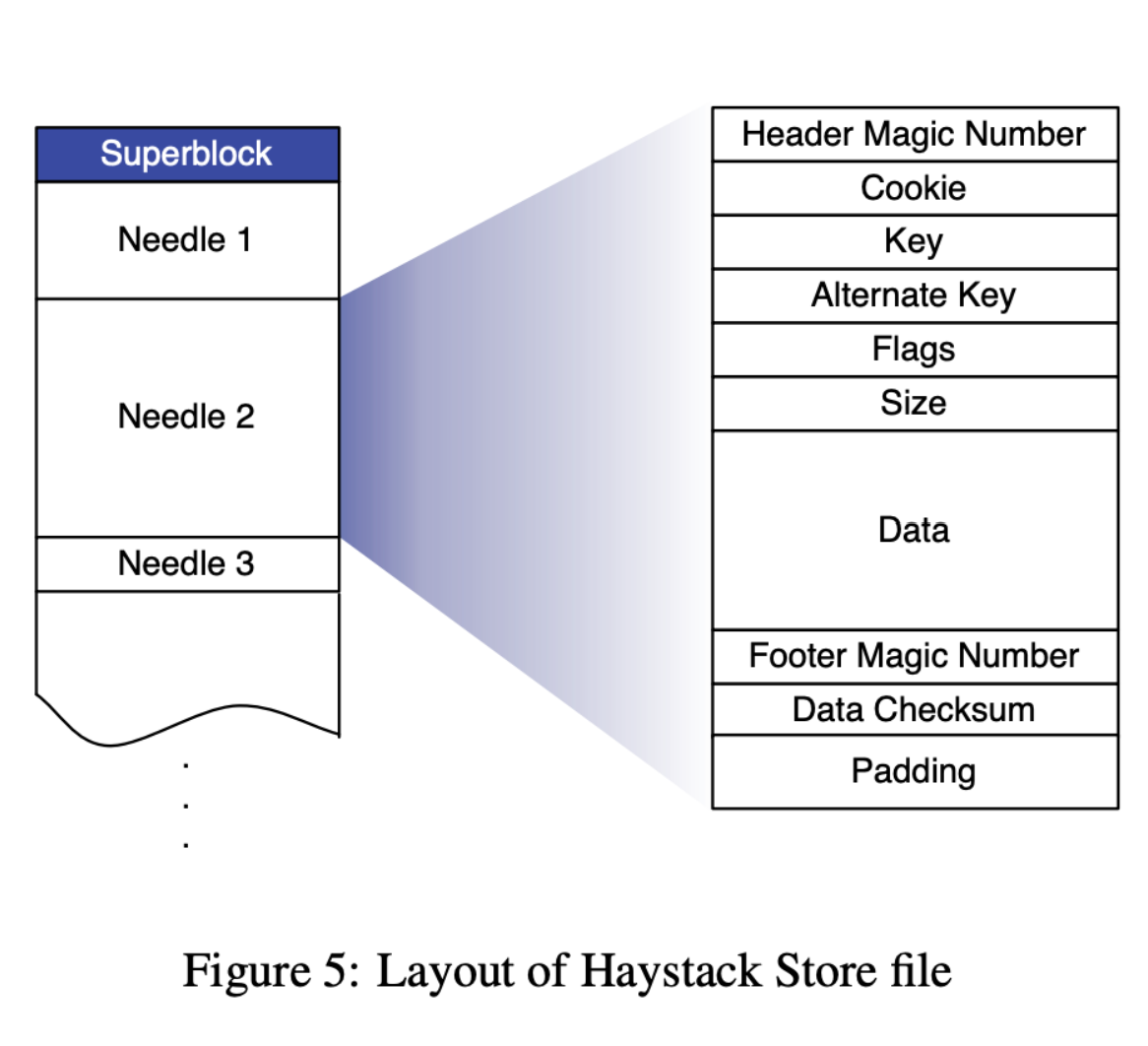
由于 Store 在内存里维护了一个从 PhotoID 到图片 offset 和 size 的 mapping,因此是有状态的。当 Store 被重启的时候,需要根据 PV 的情况,在内存里重建这一映射关系。为了加快这一过程,Haystack 还引入了一个索引文件 Index。对于每一个 PV 而言,Store 会维护一个 Index 文件。
在写图片的时候,Store 会同步地写到 PV 里,异步地在 Index 文件里 append 一个新的 Needle。在删除图片的时候,Store 只会同步地更改一下对应 Needle 的 flag,而 Index 则完全不更新。这样的异步设计使得写请求的延迟不会受到 Index 的影响,但是相应地也引入了 Index 与 PV 之间的不一致问题。不一致的问题主要是两种情况:
- 在 PV 里存在的某些图片在 Index 里没有被索引
- 在 PV 里被设置了删除 Flag 的图片在 Index 仍然可以被索引到
为了解决第一个问题,Store 会在重启的时候根据 Index 的最后一个 Needle,在 PV 中寻址找到,然后顺序地检查其后的 Needle 是否没有被索引。因此 Index 的最后一条记录是 Index 最后被写入的,在它之前的 Needle 一定都有对应的 Index,在它之后的 Needle 是我们需要关注的 Orphan Needle。这里预设了 Needle 索引的构建虽然是异步但是是有序的,这也很合理,毕竟 Haystack 的 PV 也非常依赖有序。
为了解决第二个问题,Store 会在读请求时检查读到的 Needle 对应的 flag,确定这一 Needle 是否是被删除了的。通过读请求时增加了些许的 overhead 来解决了这一问题。
开源实现
SeaweedFS 是 Haystack 的开源实现,但是目前的设计与 Haystack 也有不少出入。这里我们以 SeaweedFS 的早期版本 2e1ffa189b(以下成为 WeedFS) 作为参考,了解一下其设计与实现。
在 WeedFS 中,一共有三个组件:
- WeedClient:WeedFS 的客户端,主要通过与 WeedMaster 和 WeedVolume 组件的交互完成文件上传等操作。
- WeedMaster:对标 Haystack Directory,主要维护了图片 ID 到 Volume 的映射。
- WeedVolume:对标 Haystack Store,真正存储图片和索引的组件。
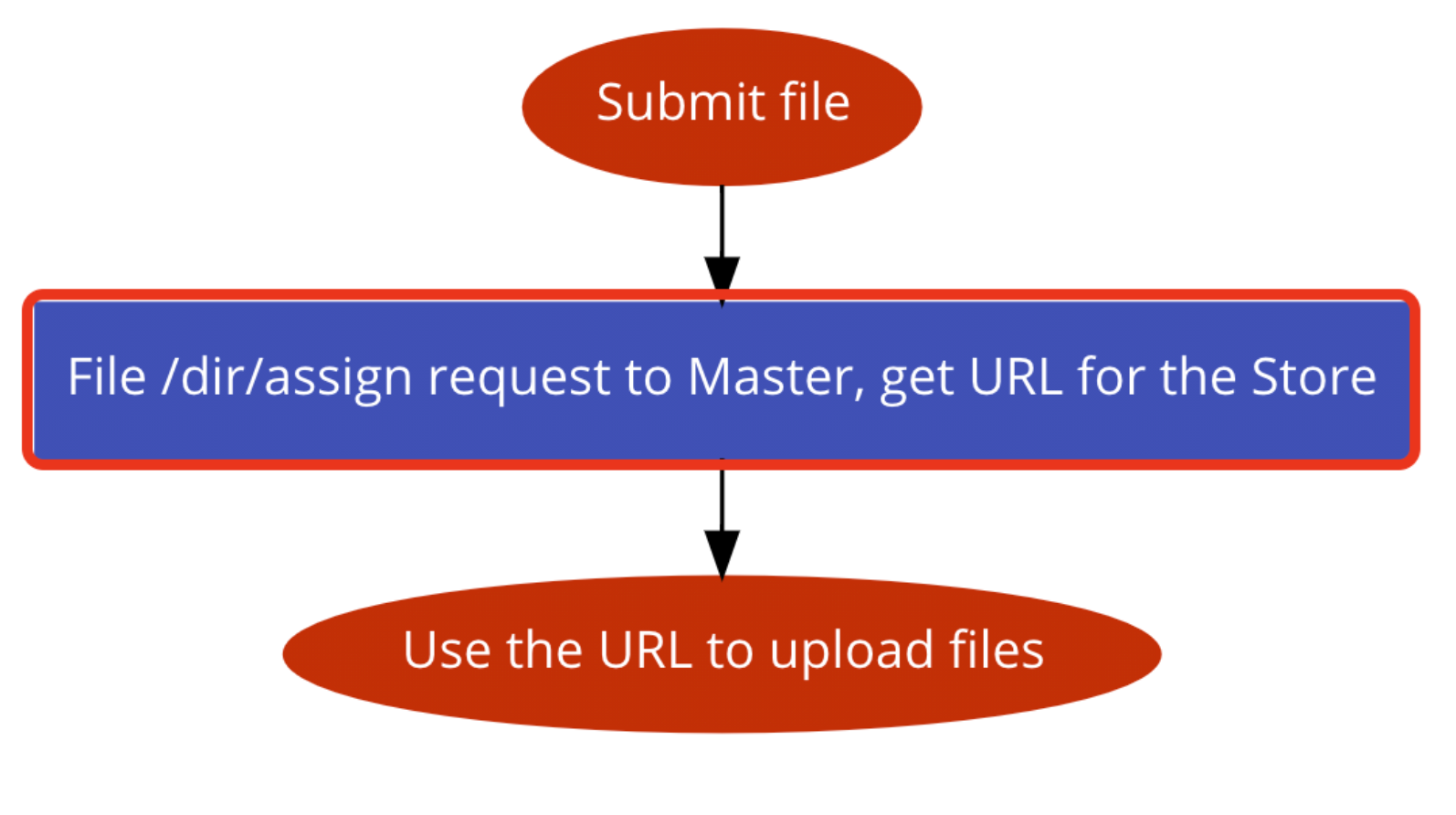
当用户通过 WeedClient 发起文件上传请求时,首先会通过请求 WeedMaster 的 /dir/assign 接口,确定应该上传到哪个 WeedVolume 上。WeedMaster 会返回一个 Weed Volume 的 URL。随后 WeedClient 会利用 URL 将文件上传到对应的 Volume 上。
// /dir/assign in WeedMaster
func dirAssignHandler(w http.ResponseWriter, r *http.Request) {
c:=r.FormValue("count")
fid, count, machine, err := mapper.PickForWrite(c)
if err == nil {
// Return the PublicURL to the client.
writeJson(w, r, map[string]string{"fid": fid, "url": machine.Url, "publicUrl":machine.PublicUrl, "count":strconv.Itoa(count)})
} else {
log.Println(err)
writeJson(w, r, map[string]string{"error": err.Error()})
}
}
而 WeedVolume 会根据请求,创建对应的 Needle,并且写到文件中。WeedVolume 维护了一个 VolumeID 到 Volume 的映射,而每个 Volume 维护了一个在内存中的 NeedleMap。通过这样的结构,WeedVolume 同样实现了尽可能少的元数据操作。不过与 Haystack 不太一样的地方在于,这一个版本的 WeedFS 还是通过同步的方式写 IndexFile。
type Store struct {
volumes map[uint64]*Volume
dir string
Port int
PublicUrl string
}
type Volume struct {
Id uint32
dir string
dataFile *os.File
nm *NeedleMap
accessLock sync.Mutex
}
type NeedleMap struct {
indexFile *os.File
m map[uint64]*NeedleValue //mapping needle key(uint64) to NeedleValue
bytes []byte
}
type NeedleValue struct {
Offset uint32 "Volume offset" //since aligned to 8 bytes, range is 4G*8=32G
Size uint32 "Size of the data portion"
}
结语
Haystack 的论文从行文到设计都非常值得学习。从一个非常具体的场景出发,现有的方案不能很好地满足需求。同时根据性能上的 Key Insight,设计了新的实现方式,尽可能地规避额外的开销。SeaweedFS 目前的代码也已经非常复杂了,可能后续会专门针对它进行一些学习和分析。
参考文献
License
- This article is licensed under CC BY-NC-SA 3.0.
- Please contact me for commercial use.