
引言
众所周知,GOMAXPROCS 是 Golang 提供的非常重要的一个环境变量设定。通过设定 GOMAXPROCS,用户可以调整 Runtime Scheduler 中 Processor(简称P)的数量。由于每个系统线程,必须要绑定 P 才能真正地进行执行。所以 P 的数量会很大程度上影响 Golang Runtime 的并发表现。GOMAXPROCS 在目前版本(1.12)的默认值是 CPU 核数,而以 Docker 为代表的容器虚拟化技术,会通过 cgroup 等技术对 CPU 资源进行隔离。以 Kubernetes 为代表的基于容器虚拟化实现的资源管理系统,也支持这样的特性。这类技术对 CPU 的隔离限制,是否能够影响到 Golang 中的 GOMAXPROCS,进而影响到 Golang Runtime 的并发表现呢?这是一个值得探索的话题,本文从 Docker 和 Kubernetes 对 CPU 资源的限制出发,利用实验的方式验证了这一问题,并且给出了一些个人看法。
背景
Goroutines 是 Golang 最吸引人的特性之一,它是 stackful coroutines 的一种实现。为了支持这一特性,Golang 需要一个运行时,在 Goroutines 和系统线程之间进行调度,这也就是 go-scheduler 的作用。go-scheduler 引入了三个抽象,分别是 Processor,Machine(简称 M) 和 Goroutine(简称 G)。其中 G 就是用户创建的 goroutines,而 M 则是系统线程,是负责真正执行 goroutines 的系统线程。 Processor 是类似于 CPU 核心的概念,其用来控制并发的 M 数量。
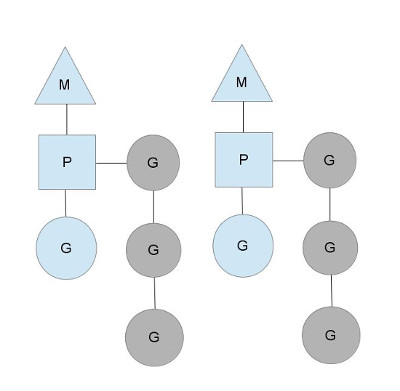
当 M 需要执行 G 的时候,它需要寻找到一个空闲的 P,只有跟一个 P 绑定后,M 才能被执行。通过这样的方式,go-scheduler 保证了在同一时间内,最多只有 P 个系统线程在真正地执行。P 的数量在默认情况下,会被设定为 CPU 的数量。而 M 虽然需要跟 P 绑定执行,但数量上并不与 P 相等。这是因为 M 会因为系统调用或者其他事情被阻塞,因此随着程序的执行,M 的数量可能增长,而 P 在没有用户干预的情况下,则会保持不变。
// runtime/proc.go
// The bootstrap sequence is:
//
// call osinit
// call schedinit
// make & queue new G
// call runtime·mstart
//
// The new G calls runtime·main.
func schedinit() {
...
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
...
}
// runtime/os_linux.go
func osinit() {
ncpu = getproccount()
}
// runtime/os_linux.go
func getproccount() int32 {
// This buffer is huge (8 kB) but we are on the system stack
// and there should be plenty of space (64 kB).
// Also this is a leaf, so we're not holding up the memory for long.
// See golang.org/issue/11823.
// The suggested behavior here is to keep trying with ever-larger
// buffers, but we don't have a dynamic memory allocator at the
// moment, so that's a bit tricky and seems like overkill.
const maxCPUs = 64 * 1024
var buf [maxCPUs / 8]byte
r := sched_getaffinity(0, unsafe.Sizeof(buf), &buf[0])
if r < 0 {
return 1
}
n := int32(0)
for _, v := range buf[:r] {
for v != 0 {
n += int32(v & 1)
v >>= 1
}
}
if n == 0 {
n = 1
}
return n
}
上述代码,就是 go-scheduler 确定 P 数量的逻辑。在 Linux 上,它会利用系统调用 sched_getaffinity 来获得系统的 CPU 核数。在了解了 Golang 的行为之后,接下来我们可以在 Kubernetes 和 Docker 上,通过实验来观察一下它的表现和影响,再分析一下原因。
测试环境
CPU
由于实验是利用 XPS-13 笔记本进行的,所以 CPU 只有四核,其具体的配置如下:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 2
Core(s) per socket: 2
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 142
Model name: Intel(R) Core(TM) i7-7560U CPU @ 2.40GHz
Stepping: 9
CPU MHz: 1011.469
CPU max MHz: 3800.0000
CPU min MHz: 400.0000
BogoMIPS: 4800.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 4096K
NUMA node0 CPU(s): 0-3
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp md_clear flush_l1d
测试代码
Runtime 提供了两个函数可以获得 GOMAXPROCS 的值,分别是 runtime.NumCPU 和 runtime.GOMAXPROCS。因此,在实验中可以利用这两个函数来查看未经过修改的 GOMAXPROCS:
package main
import (
"fmt"
"runtime"
)
func main() {
fmt.Printf("NumCPU: %d, GOMAXPROCS: %d\n", runtime.NumCPU(), runtime.GOMAXPROCS(-1))
}
为了实验的方便,首先已经将其构建成了 Docker 镜像 gaocegege/get-maxprocs:v1.0.0。
实验结果
Kubernetes
首先,利用 Kubernetes Job,先运行一个没有任何 CPU 限制的任务:
apiVersion: batch/v1
kind: Job
metadata:
name: get-gomaxprocs
spec:
template:
spec:
containers:
- name: get
image: gaocegege/get-maxprocs:v1.0.0
restartPolicy: Never
backoffLimit: 4
随后,再逐渐给 CPU 加上资源利用的请求限制,查看结果,得到如下结果:
| Requests | Limits | NumCPU | GOMAXPROCS |
|---|---|---|---|
| 10m | 100m | 4 | 4 |
| 10m | 1000m | 4 | 4 |
| 100m | 1000m | 4 | 4 |
| 100m | 2000m | 4 | 4 |
根据结果可以看到,Kubernetes 在 CPU 上的限制并不能影响 GOMAXPROCS。
Docker
| Arguments | NumCPU | GOMAXPROCS |
|---|---|---|
| –cpus=1 | 4 | 4 |
| –cpus=2 | 4 | 4 |
| –cpu-shares=1024 | 4 | 4 |
| –cpuset-cpus 0 | 1 | 1 |
| –cpuset-cpus 0,1 | 2 | 2 |
性能测试
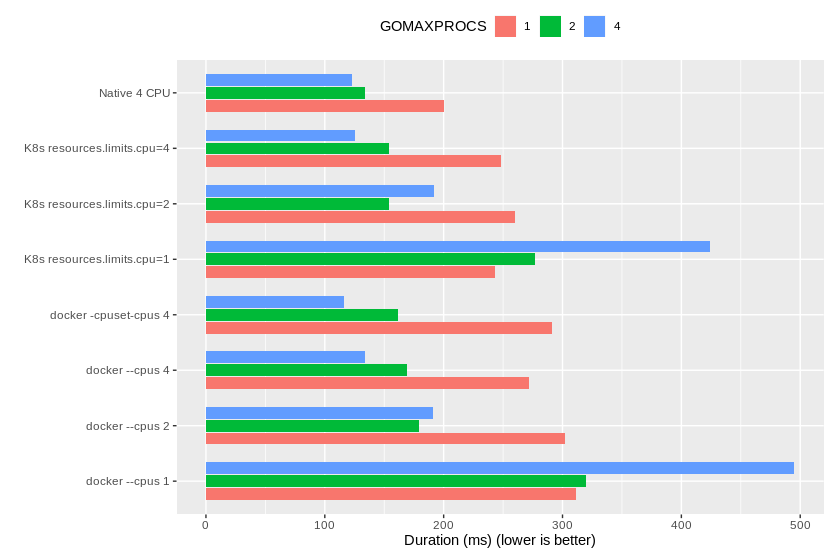
既然不少隔离 CPU 的方式无法限制 Go 运行时对 CPU 数量的判定,那这一问题是否会影响运行的性能,是一个值得分析的问题。利用了上游社区提供的 CPU bound 的 Benchmark concprime,对不同的限制手段和 GOMAXPROCS 取值进行了详细的性能测试,得到了如下结果。
结果分析
Kubernetes 与 docker --cpus 一样,都是利用 CFS Bandwith Control 来对 CPU 进行资源使用的限制的。以使用 Docker 运行时的 Kubernetes 为例,当用户利用 .spec.containers[].resources.limit.cpu 来限制 CPU 的 hard limit 时,其背后的行为是向 Docker 容器中加入了 HostConfig.CpuPeriod 和 HostConfig.CpuQuota。最后两个 cpu,cpuacctcgroup 下的值 cpu.cfs_period_us 和 cpu.cfs_quota_us 被修改。
CFS Bandwith Control 原本是为了解决 CPU Share 不能做 hard limit 的问题的,但它同样造成了新的问题,系统调用 sched_getaffinity 并不感知它对进程的限制。这也使得运行在 Kubernetes 中的 Go 程序的运行时始终会认为自己可以使用宿主机上的所有 CPU,进而创建了相同数量的 P。而当其 GOMAXPROCS 被手动地设置为限制后的值后,其在 CPU 密集的任务上的表现得到了很大程度的提高。
目前 Golang 上游并无好的方式来规避这一问题,而 Uber 提出了一种 Workaround uber-go/automaxprocs。利用这一个包,可以在运行时根据 cgroup 或者 runtime 来修改 GOMAXPROCS,来选择一个合适的取值,值得一试。
参考文献
License
- This article is licensed under CC BY-NC-SA 3.0.
- Please contact me for commercial use.