
谷歌的Chrome浏览器无疑是最好用的浏览器之一,Google Native Client是Chrome浏览器的一个Feature,它的目的是解决Javascript计算能力不强的问题,解决方法是通过在浏览器中运行原生的代码的方式来做到的。
在传统的前端实现中,基本只有HTML, CSS和Javascript三种语言(算是语言么)的事情,但是随着需求的复杂化,有些时候要求网页应用有着更好的计算性能。

上面的图展示了一些语言在执行从0到10000000的加法时的耗时。可能有点小,不清楚,但是结果是C表现最好,golang表现也还不错,这两种语言都是编译型的语言。而Javascript + V8的表现,其实也还好,毕竟比Python要好了(心疼),但是在一些应用场景下,还是不够的。举个例子,比如科学计算,或者游戏渲染,等等。如果能够在浏览器里运行C或者C++代码,那这个世界会不会更加美妙一点呢。
谷歌的论文Native Client: A Sandbox for Portable, Untrusted x86 Native Code就是希望能够在浏览器里跑C++代码,并使它可以跟Javascript做通信,甚至操纵DOM。但是如果是直接跑Native代码,那安全性就必然没有办法得到保证,ActiveX就是一个活生生的例子。ActiveX让Native代码可以接触到茫茫多的系统调用,于是在那一段ActiveX盛行的日子里,随便打开一个网页就会自动安装一些诸如3721助手之类奇奇怪怪的东西。因此,谷歌更加关注如何限制Native代码的威力,在保证计算性能的基础上,不让浏览器里的Native代码有能力Hack掉操作系统。
系统架构
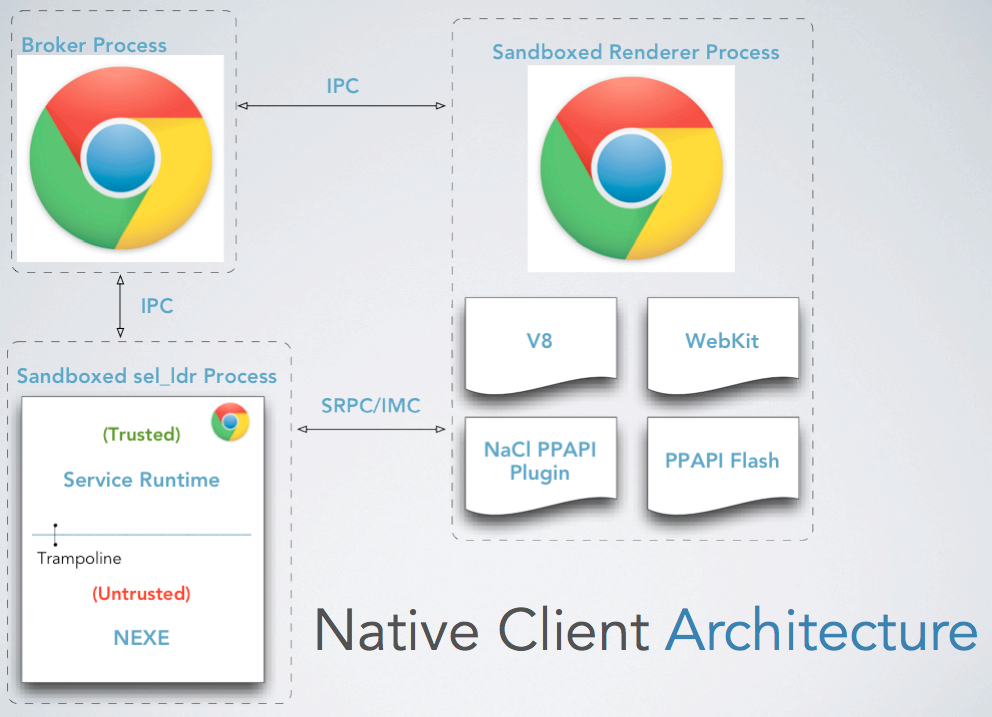
NaCl的系统架构如图,其实不算特别复杂。其中最主要的部分是左下角的那一个进程。跟它有关的概念有三个,分别是Service Runtime,NaCl Module,和IMC。其中NaCl Module就是指程序员写的想跑在浏览器里,跟Javascript进行交互的Native代码。而因为代码可能具备攻击性,因此需要用一个东西来把它包住,保证它不会危害到操作系统的安全。这个用来包住它的东西就是Service Runtime,在Service Runtime和NaCl Module之间是隔着一个沙箱的,这个沙箱被称作内层沙箱。而Service Runtime,是一个由Chrome发起的跟寻常的Renderer进程不一样的进程,它的代码被认为是可信的,它用来保证运行在其中的不可信代码,也就是NaCl Module不会直接地面对系统调用,包括对系统的内存进行保护等等。在Service Runtime的外层,还有一个沙箱,是类似ptrace的实现,用来做System Call Interception。
之前有提到,NaCl Module中的代码是可以跟浏览器中的Javascript代码进行通信的,通信的媒介就是IMC。IMC也是利用socket的概念,来进行双向的通信的。
除了这三个概念之外,其他东西就跟Native Client关系不大了。
实现分析
Native Client的目标很好很强大,那它具体是用了什么方法解决了安全问题的呢,那就要去看它的实现部分。
Inner Sandbox
首先要讲的是NaCl的内部沙箱,这也是最重要的一个安全举措。Inner Sandbox的作用是用软件的方式隔离不可信代码。在这方面都有哪些挑战呢,有以下四点:
- Data integrity: No loads or stores outside of data sandbox
- Reliable disassembly
- No Unsafe instructions
- Control flow integrity
其实内层沙箱并不是有一个真正的沙箱来保护代码,而是说在代码执行之前先对代码进行静态检查,在满足一些规则的时候才会被运行。
X86-32上的实现
Native Client使用了对反汇编指令的静态分析,来保证二进制遵循由Native Client制定的各项规则。

规则看上去基本上是看不懂的,不过这里要介绍一个相关的工作,那就是Software-based fault isolation(SFI)。
SFI的概念是在93年被提出来的,它指出,一个module的fault domain是它的代码段和数据段,因此一个不可信的module不能进行超出它的代码和数据段的读写。这样这个module无论有什么恶意代码,都不会伤害到其他的module。
实现SFI的方法是往原本的module中插入一些代码,来保证一些security properties的落实。

讲这两种方法,要涉及一个CPU的概念,那就是内存分段。在这里主要是对代码和数据的分段。早期8086处理器为了寻址1M的内存空间,把地址总线扩展到了20位。但是,一个尴尬的问题出现了,ALU的宽度只有16位,也就是说,ALU不能计算20位的地址。为了解决这个问题,分段机制被引入,登上了历史舞台。段寄存器里是16位基地址,把CPU拿到的地址加上段的基地址,才是真正的20位地址。而在后来,内存分段基本就没什么用了其实。而在SFI里,用到了代码段和数据段。其中两个段的段基地址是在两个寄存器里的。
两种方法中的第一种,是根据地址得到其段基地址,然后比对段基地址跟段寄存器里面的值,如果相等,说明其访问是在合法的段内的,而如果不同,那么就说明进行了跨段的访问,这样做是非法的。也就是说,第一种方法可以知道请求是否非法。
第二种方法,是一种更加高效,但是有些缺陷的实现。在第二个方法中,首先拿到一个地址,会清除它的段地址那些位,然后再把其设置为段寄存器里的值。
本文中的Inner Sandbox,就是基于其中的第二种方法来实现的。与此同时,NaCl使用了32字节对齐的方式,使得Address Sandbox的方式少了一个or指令,于是在大小上的overhead就会变小。
X86-64和ARM上的SFI
在Native Client的文章里,只介绍了X86-32架构的SFI实现,而对于X86-64和ARM中如何实现SFI,谷歌专门写了一篇新的论文,Adapting Software Fault Isolation to Contemporary CPU Architectures。其中关于nacljmp等等的实现方式都跟X86-32有不同,感兴趣的话也可以去看看。
Outer Sandbox
外层沙箱,是一个类似seccomp或者是ptrace的实现,跟docker的用法似乎差不多,就是限制了API的调用。没什么好讲的。
Service Runtime
Service Runtime部分的代码是可信的,而且它是跟前面的Inner Sandbox运行在一个内存空间里的。那这就涉及一个控制流跳转的问题。Inner Sandbox里的代码是不可信的,而Service Runtime是可信的代码,如果控制流可以随意转移,那明显是不安全的。
这里的实现非常巧妙,建议去读下论文,之前不允许Inner Sandbox操作段寄存器,就是因为段寄存器要被用来做这里的控制流转换。
Evaluation
沙箱主要的overhead有两个地方,一个地方是在大小上,如果编译出来的二进制很大,明显是不合适的。还有就是运行时的overhead。那NaCl最后通过SPEC2000,QUAKE等,说明了这两方面的overhead都可以让人接受。
吐槽
有个相似技术,或者说目的一样,但是是从操作系统不同的层次上提高了javascript的性能,那就是asm.js。asm.js是通过使用llvm,先讲c++代码编译成中间代码,然后把中间代码翻译成asm.js,asm.js是javascript的一个子集,相比于原生的javascript有着更高的执行效率。asm.js可以做到,只比Native app慢一倍,已经是一个非常有吸引力的数字了。
