
什么是爬虫
首先scrapy是一个爬虫框架,而爬虫其实就是一个爬取互联网上的信息,并对这些信息做一些诸如持久化,结构化处理的程序。爬虫大致从功能来划分可以分为两种,一种是垂直爬虫,一种是水平爬虫。
所谓水平爬虫,大概就是搜索引擎用到的那种爬虫,其思想可以跟广度优先搜索类比下。就是爬取到一个页面,会顺着这个页面内包含的链接继续爬,之类的。而垂直爬虫,就是说这个爬虫只关心某个特定领域的内容,所以其爬取更具有针对性,而且通常是可以把爬取到的内容很好地结构化的。
scrapy是比较适合来写垂直爬虫的,因为它对垂直爬虫的情况进行了优化,比如说rule等等功能,对于写垂直爬虫而言,是非常便利的存在。如果要写搜索引擎那种需要水平爬虫的东西,我觉得就不太适合用scrapy来做了,可以考虑nutch之类的。
scrapy爬虫框架
介绍完爬虫的概念,来看看最基本的爬虫。最最基本的爬虫,是由这样几个过程组成:首先就是确定初始爬取的url,然后就是针对这些url进行爬取,最后再处理爬取到的结果,如果需要继续爬取,那就根据爬取结果中新得到的url展开新一轮的爬取。大概是这样一个过程。而scrapy抽象了爬虫的爬取过程,把过程分离成了几个独立的模块进行处理,如下图所示。整个框架一共可以分为四个模块,还有一个引擎。对于写爬虫的人而言,spider模块和item pipeline是比较经常接触的模块。
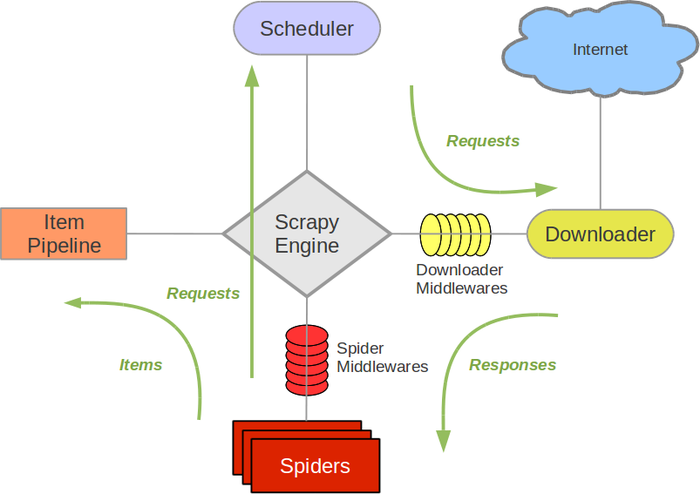
spider模块,就是指定开始爬取的url,并且对爬取下来的数据进行处理,处理下来得到的结果,可能是需要继续爬取的url,也可能是已经爬取得到的结构化的数据。两者都会发给引擎,由引擎去针对不同类型的结果,分发给不同的模块进行处理。
item pipeline模块,就是从引擎接收来自spider已经从爬取到的response处理好的结构化的数据,然后对于结构化的数据去进行下一步的处理。这种处理包括清洗,持久化存储之类的。
scheduler,从一个写爬虫的人的角度来看,就是一个调度需要爬取的url的队列。它接收来自引擎的请求,然后对请求进行队列化,然后再通过引擎传递给downloader。
downloader,是下载器,它的职责就是接收来自scheduler的请求,然后根据相应的url去得到response,然后通过引擎传给spider进行处理。
值得一提的是,似乎scrapy所有的操作都是异步的,使用了twisted来实现非阻塞的IO操作。
一个简单的爬虫
import scrapy
class StackOverflowSpider(scrapy.Spider):
name = 'stackoverflow'
start_urls = ['http://stackoverflow.com/questions?sort=votes']
def parse(self, response):
for href in response.css('.question-summary h3 a::attr(href)'):
full_url = response.urljoin(href.extract())
yield scrapy.Request(full_url, callback=self.parse_question)
def parse_question(self, response):
yield {
'title': response.css('h1 a::text').extract()[0],
'votes': response.css('.question .vote-count-post::text').extract()[0],
'body': response.css('.question .post-text').extract()[0],
'tags': response.css('.question .post-tag::text').extract(),
'link': response.url,
}
这是一个简单的爬虫,其职责是爬取stackoverflow上得票最高的问题的标题,得票数,等等信息。parse函数是一个被重载的函数,会在爬虫被启动的时候由spider调用这个函数,来生成最初的请求。而请求需要指定url与回调函数。因为scrapy是异步的,所以在请求还没有被响应的时候,不会被阻塞,只有当请求的数据已经准备好的时候,会回调之前作为参数传递进去的回调函数。回调函数固定具有一个参数,response,是请求得到的响应。
通过这样一个爬虫,就可以得到stackoverflow得票最高的一部分问题的信息。值得注意的是,关于请求的生成,是可以在回调函数里去做的。比如说,在parse_question中,如果你想继续爬取页面中的某些链接,可以继续用yield Reuqest(url, callback)的方式生成新的请求。因为所有的回调函数都是一个生成器函数,所以不仅可以处理数据,也可以生成新的请求。