
每一年,全球各地的软件工程师们都会在各种平台上开源各种各样的项目,这里面不乏一些设计优雅,实现精巧,又解决实际问题的优质开源项目。在互联网上寻找这样的项目,宛如在浩如烟海的沙漠中寻宝一般,充满了乐趣。最近忽然非常想分享一下自己私藏的开源项目宝库里那些暂时还不广为人知,或者已经成为过气网红的那些宝藏项目们。安利不会太过深入实现细节,一来我们中的绝大多数都没有时间,没有精力也没有动机真正地参与这些宝藏项目的开发工作;二来我也对很多项目的实现细节不甚了解 :-)
那么,今天聚光灯的主角是 Ray,出身自系统领域内堪称豪门的 UC Berkeley RISELab 的分布式框架。
在介绍 Ray 之前,先介绍一下 RISELab 的辉煌历史。RISELab 是 AMPLab 的继任者,AMPLab 设计了非常多工业界至今仍在大规模使用的系统,比如最广为人知的 Apache Mesos 和 Apache Spark。作为 AMPLab 的继任者,RISELab 跟 AMPLab 有着相似但不相同的愿景。AMPLab 为工业界贡献了(离线)集群计算框架的事实标准之一 Spark,而 RISELab 与 AMPLab 更多关注在离线计算领域不同,它的愿景是在线的实时计算领域。
Stoica described why the RISELab plans to build systems to power a wide range of applications: “… In the same way that Hadoop and Spark opened up the Big Data space to developers, we want the systems we build in the RISELab to help a wide range of software developers build innovative real-time applications.”
而 Ray 则是承载这一愿景的一个重要项目。
State-of-art 框架们仍未开垦的处女地
以 Spark 为代表的传统批处理的离线计算框架,尽管一直以来有各路神仙,在各个方面,对它进行各种各样的优化,但是为批处理优化的架构设计它在面向实时流的场景时力有不逮。这也是 Apache Flink 等流处理框架能够在 Spark 珠玉在前的情况下成功出道的关键原因。目前的计算框架基本都是与某种计算模式相绑定的,比如 Spark 与批处理息息相关,Flink 与流处理息息相关,而它们并不能真正地,原生地支持流和批两个场景。所以也就有了蚂蚁金服的徒离前辈下面的观点:
我们之所以选择 Ray 是因为除了它以外,其他的计算引擎大多已经和某一种计算模式绑定了,比如 Spark 推出的时候目标就是代替 Hadoop 做批计算,虽然它也可以跑流计算,但是 Spark 是拿批来模拟流;Flink 推出的时候是为了代替 Storm 做更好的流计算,虽然它也可以跑批计算,但是是拿流来模拟批,而在模拟的过程中都会有一定的缺陷或先天不足。因为这些计算引擎本身就是为了一种特定的计算模式设计的,它们天然做不到融合。
Ray 是什么
虽然说是史海钩沉系列,但 Ray 是一个十足年轻的开源项目。Ray 的正式出现是在 RISELab 的论文 Ray: A Distributed Framework for Emerging AI Applications 中,论文是在 17 年发布的。Ray 是一个分布式的计算框架,它面向的是大规模机器学习和强化学习场景。Talk is cheap,现在给你看看代码 :-)
>>> import ray
>>> ray.init()
{'node_ip_address': '192.168.5.199', 'redis_address': '192.168.5.199:31329', 'object_store_address': '/tmp/ray/session_2020-01-21_15-09-20_281043_19831/sockets/plasma_store', 'raylet_socket_name': '/tmp/ray/session_2020-01-21_15-09-20_281043_19831/sockets/raylet', 'webui_url': None, 'session_dir': '/tmp/ray/session_2020-01-21_15-09-20_281043_19831'}
>>> @ray.remote
... def f(x):
... return x * x
>>> futures = [f.remote(i) for i in range(4)]
>>> print(ray.get(futures))
[0, 1, 4, 9]
虽然 Ray 与 TensorFlow 一样,也是面向机器学习场景的框架,但是我们一般称呼它是分布式的计算框架。因为 Ray 核心部分只是提供了分布式计算的能力。虽然如此,Ray 提供的分布式计算能力非常强大,且精巧。如上述代码所示,我们将 f(x) 加上了 @ray.remote 的注解,随后利用 f.remote 进行调用。虽然看上去它与原生的 Python 函数并无二致,但是,它可以在除本机外的其他 Ray 集群中的节点中执行。所以 Ray 是在几乎不提高用户代码复杂性的情况下,实现了分布式计算的能力。这样的函数,在 Ray 的设计中被称作 Task。
同时,Ray 也支持把 Python Class 声明为 Actor 来在远程执行:
import ray
ray.init()
@ray.remote
class Counter(object):
def __init__(self):
self.n = 0
def increment(self):
self.n += 1
def read(self):
return self.n
counters = [Counter.remote() for i in range(4)]
[c.increment.remote() for c in counters]
futures = [c.read.remote() for c in counters]
print(ray.get(futures))
除了轻量级的 API 之外,Ray 的主要特性包括:高吞吐但低延迟的调度能力;支持任务的动态构建。这与实现息息相关,在稍后的章节再进行介绍。总而言之,对用户而言,Ray 可以被当做插上了分布式计算翅膀的 Python 加强版(这么说也不太合适,因为 Ray 目前也有 Java Worker 的支持,不过为了方便理解,可以先姑且这么认为)。
但是,只有如此底层的能力,没有上层成熟的生态,是难以与成熟的框架相抗衡的。因此,Ray 面向强化学习场景,基于分布式计算的能力支持,实现了上层的算法库 RLLib。

比如,如果你想发起一次倒立摆的训练:
from ray import tune
from ray.rllib.agents.ppo import PPOTrainer
tune.run(PPOTrainer, config={"env": "CartPole-v0"})
除此之外,Ray 还有一个大规模超参数搜索的支持:Tune(这不是砸我饭碗么)。Ray 提供的分布式计算能力,是天生非常适合超参数搜索这样的业务场景的。在机器学习中,超参数是在开始学习过程之前需要用户(算法工程师)给定取值的参数,而不是在训练阶段学习到的参数。比如在深度学习中,Batch Size,Learning Rate(如果有的话),Dropout(如果有的话)等等,就是超参数。超参数的取值在一定程度上对模型有着一定的影响。Tune 就利用 Ray 的能力,支持并行的超参数搜索。
Ray 的架构设计
在 Ray 的论文中有对其架构的介绍,虽然演化到如今已经有了一定的不同,但可以借鉴来了解一下。
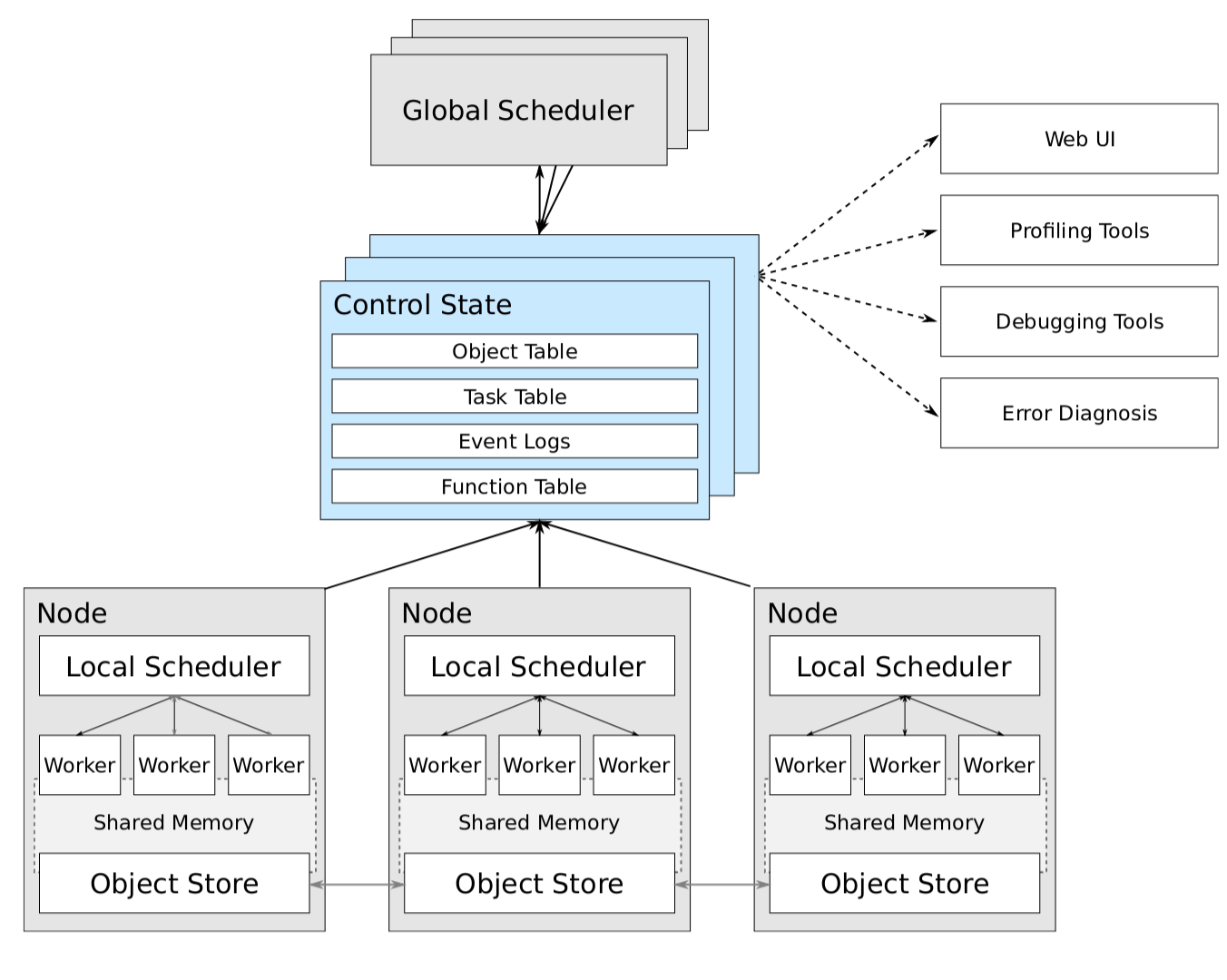
Ray 的节点需要运行两个进程,一个是 RayLet 进程,一个是 Plasma Store(对应图中的 Object Store)进程。其中 RayLet 进程中维护着一个 Node Manager,和一个 Object Manager。Ray 提供了 Python 的 API,而 RayLet 是用 C++ 实现的。其中的 Node Manager 充当了论文中 Local Scheduler 的角色,主要负责管理 Node 下的 Worker,调度在 Node 上的任务,管理任务间的依赖顺序等。而其中的 Object Manager,主要提供了从其他的 Object Manager Pull/Push Object 的能力。
Plasma Store 进程,是一个共享内存的对象存储进程。原本 Plasma 是 Ray 下的,而目前已经是 Apache Arrow 的一部分了。之前介绍 Ray 在执行带有 remote 注解的函数时并不会立刻运行,而是会将其作为任务分发,而返回也会被存入 Object Store 中。这里的 Object Store 就是 Plasma[4]。
而论文中的 Control State,在实现中被叫做 GCS,是基于 Redis 的存储。而 GCS 是运行在一类特殊的节点上的。这类特殊的节点被称作 Head Node。它不仅会运行 GCS,还会运行对其他节点的 Monitor 进程等。
Ray 提交任务的方式与 Spark 非常类似,需要利用 Driver 来提交任务,而任务会在 Worker 上进行执行。Ray 支持的任务分为两类,分别是任务(Task)和 Actor 方法(ActorMethod)。其中任务就是之前的例子中的被打上了 remote 注解的函数。而 Actor 方法是被打上了 remote 注解的类(或叫做 Actor)的成员方法和构造方法。两者的区别在于任务都是无状态的,而 Actor 会保有自己的状态,因此所有的 Actor 方法需要在 Actor 所在的节点才能执行。
我为什么看好 Ray
最早听到 Ray 这个项目,是在 RISELab 的论文中。后来在跟旷视科技的一位前辈的交流中,他的言语中透露出了很多对 Ray 的欣赏之意。好奇心驱使下,我大致学习了下 Ray 的架构和部分设计理念,确实非常有独到之处。Ray 的 API 设计非常轻量级,其学习成本之低让人印象深刻(虽然 Debug 也是真的挺难的)。后来了解了 Ray 背后的 Plasma,Plasma 背后的 Arrow,感觉都是非常踏实的工作。而且细看它的架构,真的有种来自学术界的优雅在里面。
Ray 的高校出身,也让人更放心。相比于公司开源,我一直认为学校开源有着得天独厚的优势。虽然没有公司真正的场景熏陶,但是学校里的项目没有太严苛的 KPI 要求,维护起来也更加积极一点。
优秀的系统领域的开源项目,不在工业界落地,是说不过去的。Ray 在蚂蚁金服就得到了大规模的应用。蚂蚁金服在国内组织了 Ray Forward,其中有不少经验之谈。前文中提到的徒离前辈就在负责蚂蚁金服在线学习在 Ray 上的工作,曾经有机会跟他交流过一次,提到了很多诸如 Plasma Queue 等等非常有意思的,社区还没有实现的特性。
这在一方面,说明的 Ray 的潜力,它得到了来自大厂的认可,但是也透露出了很多问题。目前,也只有大厂,有能力,有精力,采用 Ray。它的生态实在难说成熟。社区中,可堪一用的上层库只有强化学习库 RLLib 和超参数搜索库 Tune。最近虽然有了新的 RaySGD,但还非常早期。像蚂蚁这样的公司,一定是在其上进行了非常多的开发和完善工作。开源社区与公司之前的关系,是一个太过宏大的命题,这里就不多讨论了。Ray 的生态,是制约它发展的一个很大的问题。但看到这个问题其实很简单,但是解决起来真的挺困难的。因为没有生态,就没有足够的采用,没有足够的采用,就没有更好的生态。这算是开源领域的经典问题了(
但是,随着各路来自商业公司的贡献力量的加入,我个人是相信 Ray 会得到越来越多的关注的。是金子总会发光,作为 Ray 吹很期待那一天。
License
- This article is licensed under CC BY-NC-SA 3.0.
- Please contact me for commercial use.