
2024.12.24: 本文部分评论可见 Hacker News
Original post: My binary vector search is better than your FP32 vectors
在向量搜索领域出现了一项有趣的发展:二进制向量搜索。这种方法通过显著减少内存消耗,取得了30倍的减少。然而,关于它对准确性的影响引发了争议。然而通过实验我们发现,使用二进制向量搜索和特定的优化技术,可以保持与原始向量相似的准确性。为了阐明这个问题,我们展示了一系列实验来演示这种方法的效果和影响。
二进制向量搜索
二进制向量是一种向量的表示方式,其中向量中的每个元素被编码为二进制值,通常为0或1。这种编码方案将原始向量(可能包含实值或高维数据)转换为二进制格式。
二进制向量只需要占用一个 bit 来存储每个元素,而原始的 float32 向量需要每个元素占用 4 个字节。这意味着使用二进制向量可以将内存使用量减少多达 32 倍。此外,内存需求的减少还可以显著增加二进制向量操作的每秒请求数(RPS)。
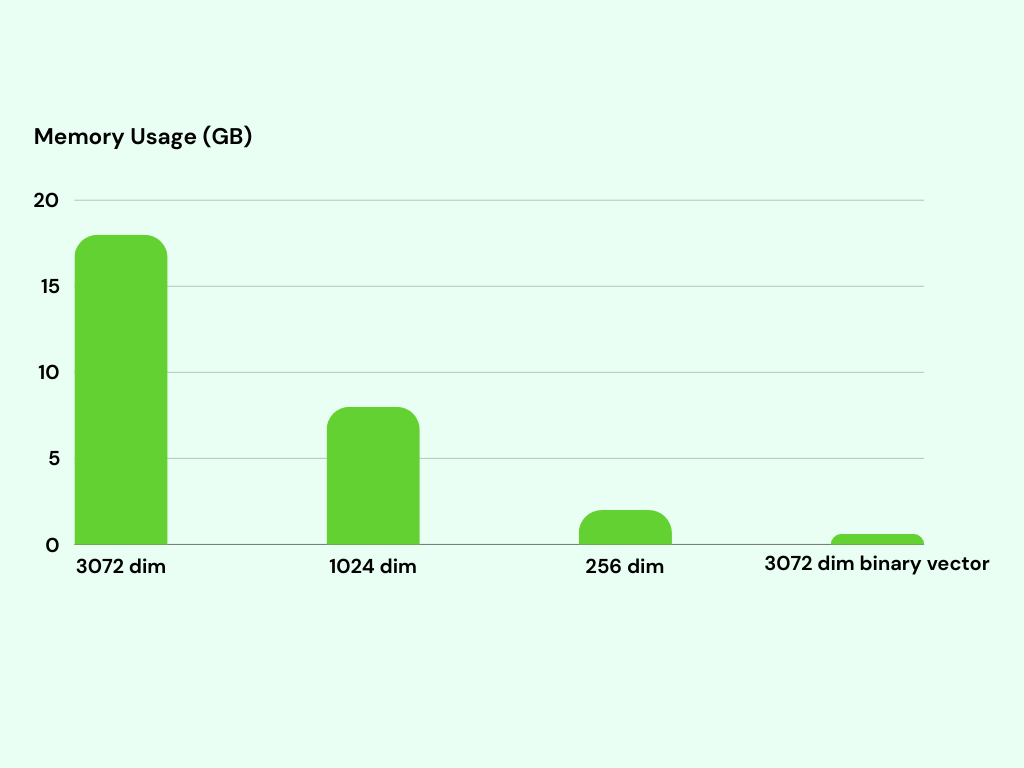
举个例子,考虑这样一个情况:我们有 100 万个向量,每个向量在 3072 维空间中由 float32 值表示。如果我们使用原始的 float32 向量,存储所有向量需要约 20GB 的内存。而如果我们使用二进制向量,仅需约 600MB 的内存即可存储所有 100 万个向量。
按照直觉来说,二值化会导致准确性显著降低,因为二进制向量丢失了许多原始信息。令人惊讶的是,我们的实验结果显示,准确性的降低并不像预期的那样大。尽管二进制向量失去了一些具体细节,但它们仍然能够捕捉到重要的模式和相似性,从而保持了相当的准确性。
实验
为了评估与原始向量方法相比的性能指标,我们使用了 dbpedia-entities-openai3-text-embedding-3-large-3072-1M 数据集进行基准测试。该基准测试是在Google Cloud虚拟机(VM)上进行的,该虚拟机规格为 n2-standard-8,包括 8 个虚拟 CPU 和 32GB 内存。我们使用了 pgvecto.rs v0.2.1 作为向量数据库。
在将一百万个向量插入数据库表后,我们为原始的 float32 向量和二进制向量都建立了索引。
CREATE TABLE openai3072 (
id bigserial PRIMARY KEY,
text_embedding_3_large_3072_embedding vector(3072),
text_embedding_3_large_3072_bvector bvector(3072)
);
CREATE INDEX openai_vector_index on openai3072 using vectors(text_embedding_3_large_3072_embedding vector_l2_ops);
CREATE INDEX openai_vector_index_bvector ON public.openai3072 USING vectors (text_embedding_3_large_3072_bvector bvector_l2_ops);
在建立索引之后,我们进行了向量搜索查询以评估性能。这些查询使用不同的限制进行执行,表示要检索的搜索结果数量(限制为 5、10、50、100)。
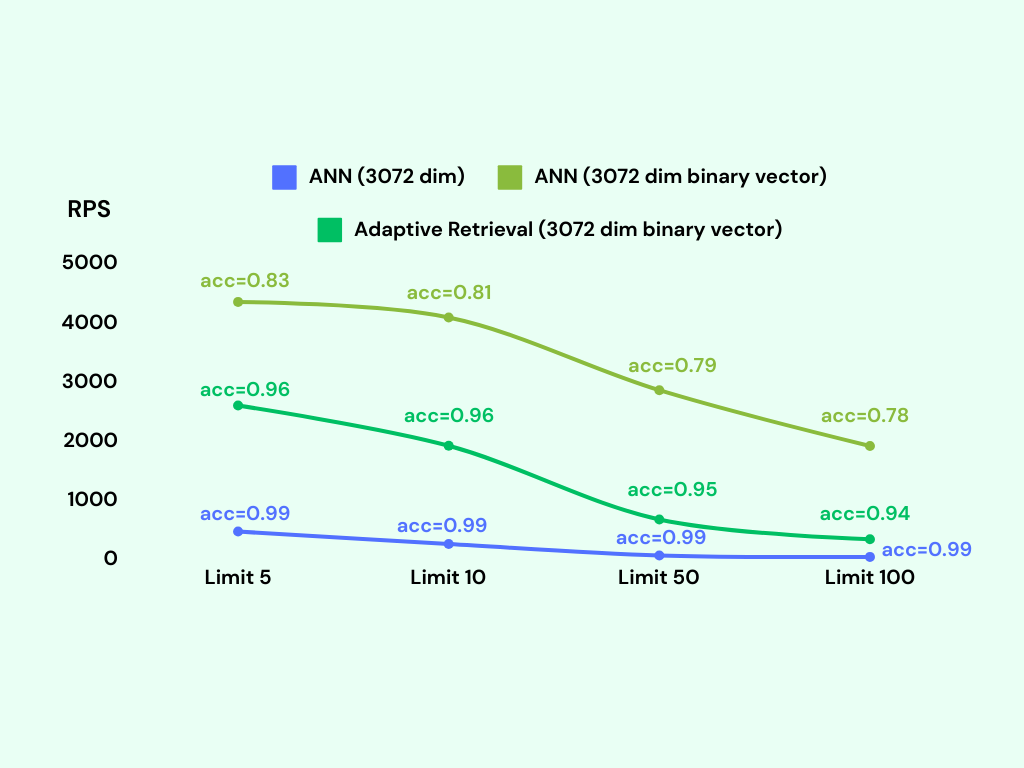
我们观察到,二进制向量搜索的每秒请求数(RPS)约为 3000,而原始向量搜索的 RPS 仅约为 300。RPS 指标表示系统每秒能够处理的请求或查询数量。较高的 RPS 值意味着更高的吞吐量和更快的响应时间。然而,与原始向量搜索相比,二进制向量搜索的准确性降低到约 80%。在某些情况下,这可能被视为不可接受,特别是在需要高准确性的关键情况下。
优化:Adaptive Retrieval
幸运的是,我们有一种简单而有效的方法,称为自适应检索(adaptive retrieval),我们从 Matryoshka Representation Learning 中学到了这个方法,可以提高准确性。
虽然名字听起来很复杂,但自适应检索的思想很简单。假设我们想找到最佳的 100 个候选项,我们可以按照以下步骤进行操作:
- 通过查询二进制向量索引从 1 百万个嵌入中检索出一个较大的集合(例如 200 个候选项)。这是一个快速的操作。
- 使用 KNN 查询对候选项重新排序,以获取排名前 100 的候选项。请注意,我们使用 KNN 而不是 ANN 进行重新排序。在需要处理较小集合并进行准确相似性搜索的场景中,KNN 很适用,因此在这种情况下对候选项进行重新排序是一个很好的选择。
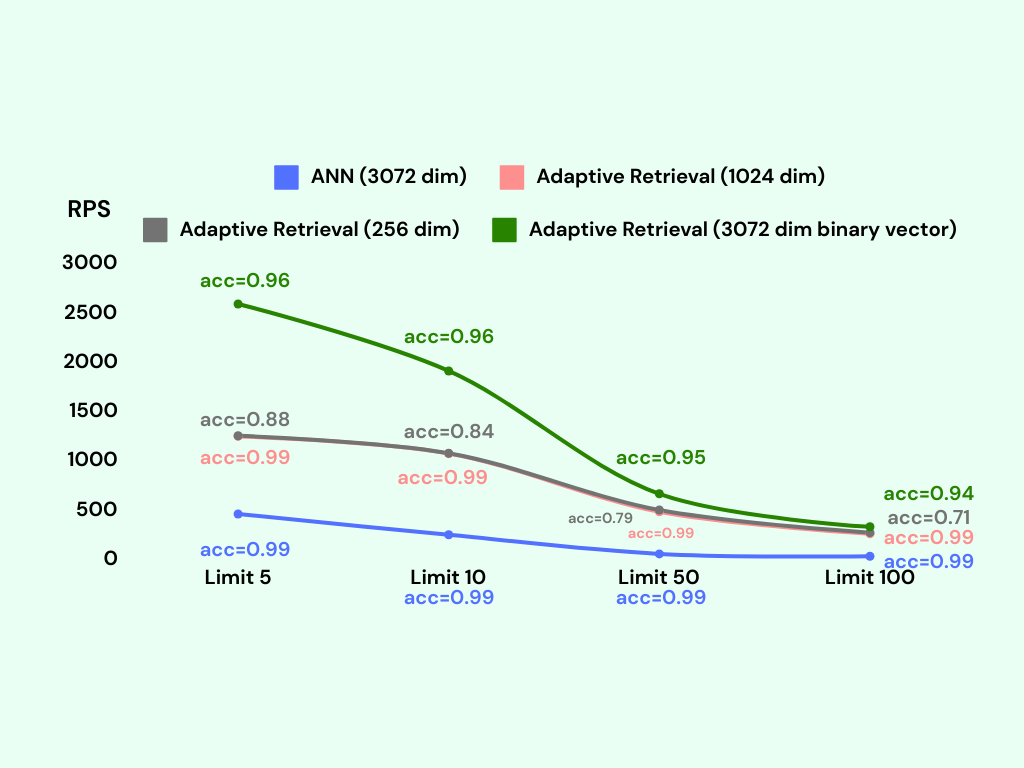
结合二进制向量搜索的效率和 KNN 重新排序的准确性,我们可以在检索过程中既实现速度又提高准确性。通过引入这个重新排序步骤,我们可以显著提高准确性,潜在地达到高达 95% 的准确率。此外,系统仍然保持着高的每秒请求数(RPS),大约为 1700。此外,尽管这些改进,索引的内存使用仍然显著较小,约为原始向量表示的 30 倍。
以下是我们在 PostgreSQL 中实现 Adaptive Retrieval 的 SQL 函数:
CREATE OR REPLACE FUNCTION match_documents_adaptive(
query_embedding vector(3072),
match_count int
)
RETURNS SETOF openai3072
LANGUAGE SQL
AS $$
-- Step 1: Query binary vector index to retrieve match_count * 2 candidates
WITH shortlist AS (
SELECT *
FROM openai3072
ORDER BY text_embedding_3_large_3072_bvector <-> binarize(query_embedding)
LIMIT match_count * 2
)
-- Step 2: Rerank the candidates using a KNN query to retrieve the top candidates
SELECT *
FROM shortlist
ORDER BY text_embedding_3_large_3072_embedding <-> query_embedding
LIMIT match_count;
$$;
与 Shortened vectors 的比较
OpenAI 最新的 embedding 模型 text-embedding-3-large 具有一项功能,允许用户截断向量直接使用。

该模型默认生成 3072 维的嵌入向量。但是可以安全地从序列的末尾删除一些数字,仍然能够保持文本的有效表示。例如,可以将嵌入向量缩短为 1024 维。这个功能可以节省内存并加快请求速度,就像二进制向量一样。
然而根据我们的实验,结论很明确:二进制向量明显优于缩短向量。
我们进行了类似的基准测试来与二进制向量进行比较。我们使用相同的数据集和机器类型创建了两个索引,但维度不同。一个索引有 256 维,另一个索引有 1024 维。
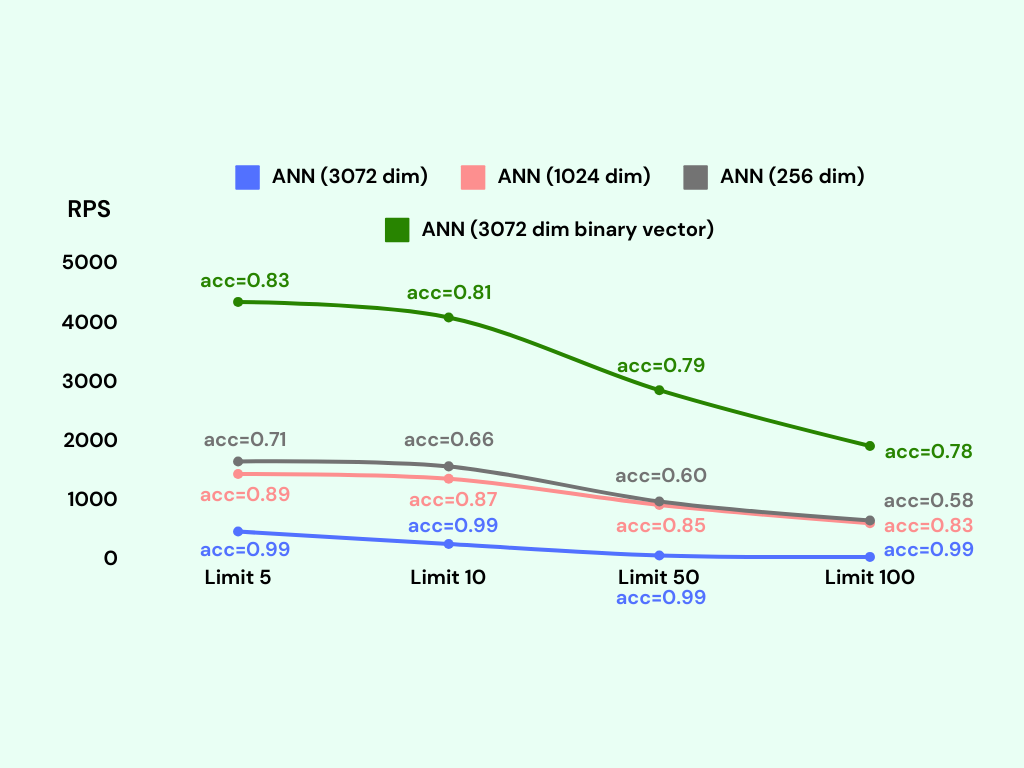
1024 维索引在每秒 1000 个请求(RPS)的情况下实现了约 85% 的准确率。另一方面,256 维索引在每秒 1200 个请求(RPS)的情况下准确率约为 60%。
1024 维索引需要约 8GB 的内存,而256 维索引则使用约 2GB 的内存。相比之下,二进制向量方法在每秒 3000 个请求(RPS)的情况下实现了约 80% 的准确率,其内存使用量约为 600MB。
我们使用较低维度的索引实现了自适应检索。在请求速率(RPS)和准确率方面,二进制向量索引仍然优于 256 维索引,并且内存使用量更低。另一方面,自适应检索配合 1024 维索引实现了更高的准确率(99%);然而,它的请求速率相对较低,并且与其他索引相比,内存使用量增加了 12 倍。
结论
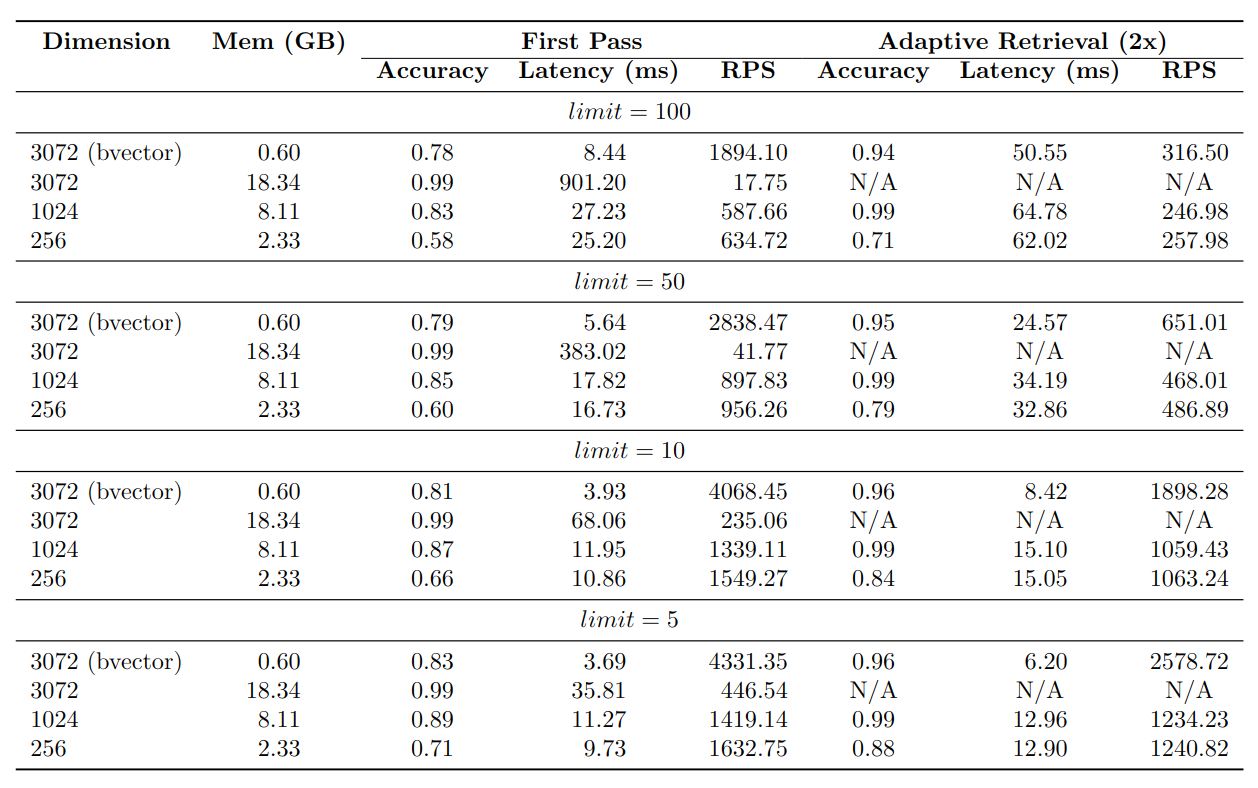
通过利用自适应检索技术,二进制向量可以在显著减少 30 倍的内存使用量的同时保持高水平的准确性。我们在表格中展示了基准指标以展示结果。需要注意的是,这些结果是特定于 OpenAI text-embedding-3-large 模型的
License
- This article is licensed under CC BY-NC-SA 3.0.
- Please contact me for commercial use.