
在 2023 年的时候,我们实现了一个大型语言模型(LLM)的无服务器推理平台产品 ModelZ。我们还通过 OpenModelZ 开源了一些核心组件。在 Kubernetes 上部署 LLMs 与传统的机器学习模型部署相比有一些新的变化和挑战。虽然我们现在的重点已经转移到基于 PostgreSQL 的向量数据库 VectorChord,但我们希望分享我们在构建产品时的经验,希望对社区中的其他人有所帮助。
本文将涵盖以下主题:
- 动机
- 系统的目标和非目标
- 架构和权衡
- 容器加载和缓存
- 负载均衡
- 调度和自动扩展
- 与其他实现方式的比较
动机
回到 2023 年,受到 OpenAI 的 ChatGPT 的成功的启发。我们认为开源的 LLMs 是 AI 的未来,由此产生了非常多的部署需求。而满足这一需求最直观的方式是提供一个平台,开发者可以在上面部署他们的 LLMs,并通过一个简单的 API 来访问。或者你可以说,我们想要构建一个 serverless LLM 推理服务。
用户上传模型文件。当请求到来时,模型推理服务会被运行,然后返回结果。这样的服务可以在需要时自动扩展,而不需要用户关心底层的基础设施。值得一提的是,这样的产品形态与 Together.AI 或 Fireworks 有所不同。它们的计费单位是 Token,而我们的计费单位是 GPU 时间。因此更像是 Modal、Replicate 和已经 sunset 的 Banana.dev。
现在看来,这个产品形态是有一些问题的。以 Token 为计费单位的产品能够通过超卖等方式来提高利润,而以 GPU 时间为计费单位的产品则需要更多的成本。或许 LLM as a service 而非 LLM inference as a service 的产品有更好的商业模式。但与本文的主题无关,就不再讨论。
使用流程
在介绍技术细节之前,我们先来看看用户使用产品的流程。用户可以选定一个模型,并以此创建推理服务。在使用之前,需要设定一些用于自动扩缩容的参数,如:
min-replicas:最小的副本数。max-replicas:最大的副本数。target-qps:每个副本的理想并发请求数。scale-to-zero-duration:空闲多久后扩缩容到 0。startup-duration:等待部署启动的时间。
随后用户会得到一个与 OpenAI API 兼容的 endpoint,可以通过这个 endpoint 来访问推理服务。
架构
我们遵循了一个中心化的设计,在控制面中有多个组件,下图展示了这些组件之间的关系。
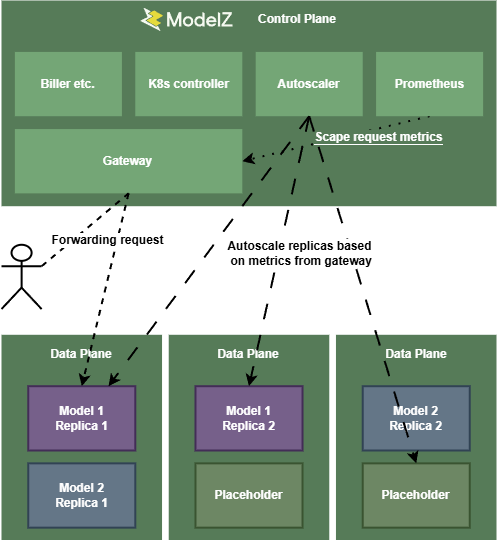
Gateway 是用户请求的入口,它会将请求转发给对应的推理服务。Kubernetes Controller 负责管理推理服务的生命周期,根据用户选择的不同框架和模型创建对应的 Deployment,与此同时,可能会设置一些环境变量配合其他组件对冷启动进行加速,后续会详细介绍。Autoscaler 负责根据用户设置的扩缩容策略与当前的负载情况来调整副本数。
架构是简洁的,SkyPilot Serve 与我们当初的设计有很多相似之处。但是仅仅如此是不够的,我们还需要考虑一些细节问题。
冷启动
最突出的问题是如何加速冷启动。这也是 LLM 为代表的新型模型部署的一个共性问题。在传统的模型部署中,模型的加载时间是可以接受的,但是在 LLM 的场景下,模型参数从 10B-500B 不等,DeepSeek v3 更是将模型推到了 670B 的规模。在运行时,推理服务需要首先加载模型参数,过大的模型参数会导致加载时间过长,用户体验不佳。因此,我们需要一些方法来加速这个过程。
在冷启动的过程中,通常主要的延迟来源是镜像的加载和模型参数的加载两方面。镜像被 Kubelet 从镜像仓库拉取到本地,然后被加载到容器中。模型则是从远程存储下载到本地,然后加载到 GPU 中。一般而言模型和镜像不再采取上一代 AI 工程化中常见的打包在一起的做法,而是分开存储。因此为了简化问题,我们可以将这两个问题分开来讨论。
模型加载
模型的加载是一个 I/O 密集型的任务。通常模型会存储在一个远程的存储中,如 Huggingface Hub。模型首先从远程存储下载到本地的硬盘中,然后再加载到 GPU 中。
在这个过程中,需要尽可能避免任何的 cast 操作,以免增加内存的使用,这通常发生在没有使用正确的精度的情况下(参考 huggingface/transformers#28476)。
分析整个过程,我们可以将其大致分为两个阶段:下载和加载。一个直观的优化是维护单个集群内模型的缓存,在避免重复下载的同时,加速集群内缓存的分发。我们观察到,大部分的模型都在 Huggingface Hub 上进行存储和分发。因此,我们可以通过在集群内部署一个 Hub 的缓存来加速模型的下载。这样,模型只需要下载一次,就可以在集群内部共享。而且这一实现最好是透明的,用户无需关心这一过程,也无需修改代码。
通常来说,用户会使用如下代码来加载模型:
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-7B-Instruct", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
在这个过程中,transformers 实际上会调用 huggingface_hub client lib 来完成模型下载的过程。在之前版本的 huggingface_hub 中,我们可以设置一个环境变量 HF_ENDPOINT 来指定 Hub 的地址。我们可以通过设置这个环境变量来指向集群内的缓存服务器。这样 transformers 会将所有对 Huggingface Hub 的请求转发到集群内的缓存服务器上。
缓存服务的逻辑也非常简单,将模型下载以外的请求全部转发到 Huggingface Hub 的服务器 https://huggingface.co 上,而对于模型下载请求,先检查本地是否有缓存,如果没有则从 Huggingface Hub 下载,然后再转发给用户。
缓存的目录结构可以参考 Huggingface Hub 的目录结构,是 Key-Value 的形式:
ls $HOME/.cache/huggingface/cache-server/
103bad8a83037abcdb9d24f2b21eba8792b33a5d
193490b58ef62739077262e833bf091c66c29488058681ac25cf7df3d8190974
19da7aaa4b880e59d56843f1fcb4dd9b599c28a1d9d9af7c1143057c8ffae9f1
1a02ee8abc93e840ffbcb2d68b66ccbcb74b3ab3
1a189f0be69d6106a48548e7626207dddd7042a418dbf372cefd05e0cdba61b6
1b134cded8eb78b184aefb8805b6b572f36fa77b255c483665dda931fa0130c5
2c2130b544c0c5a72d5d00da071ba130a9800fb2
452ff48e07a68bcebea2a57423332ca5fd5c5126
...
其中的文件名是 Huggingface Hub 的请求 Header 中的 X-Linked-Etag 或 ETag 的值,这个值是 Huggingface Hub 返回的一个唯一标识符,用于标识模型的版本。这样,我们就可以通过这个值来判断是否需要重新下载模型。
curl --location --head 'http://HF_ENDPOINT/runwayml/stable-diffusion-v1-5/resolve/39593d5650112b4cc580433f6b0435385882d819/safety_checker/model.safetensors'
HTTP/1.1 200 OK
Accept-Ranges: bytes
Access-Control-Allow-Origin: https://huggingface.co
Access-Control-Expose-Headers: X-Repo-Commit,X-Request-Id,X-Error-Code,X-Error-Message,ETag,Link
Content-Length: 1127
Content-Type: text/plain; charset=utf-8
Date: Fri, 03 Mar 2023 06:58:34 GMT
Server: nginx
Strict-Transport-Security: max-age=31536000; includeSubDomains
Vary: Origin, Accept
X-Linked-Etag: "9d6a233ff6fd5ccb9f76fd99618d73369c52dd3d8222376384d0e601911089e8"
X-Linked-Size: 1215981830
X-Powered-By: huggingface-moon
X-Repo-Commit: 39593d5650112b4cc580433f6b0435385882d819
X-Request-Id: Root=1-64019a9a-2a1c8df34f329c2167b71ce2
其中还有不少工程的细节问题,比如如何利用一致性哈希等方式保证缓存的一致性,但大致的原理就是如此。在目前的 huggingface_hub 的版本中,这一环境变量已经被移除,但仍然有类似的方式。这一优化与其他优化都不冲突,可以同时使用。在模型的下载的 benchmark 过程中,这一优化已经可以打满内网带宽。
下载可以通过缓存来优化,而加载可以通过 stream 的方式来优化。tensorizor 和 runai model streamer 能够从本地或者远程的对象存储中以流式的方式将 safetensors 格式的 tensors 加载到 GPU 显存里。在当时我们并没有使用这一优化,但它理论上可以显著提升加载速度,因为在加载的过程中通常无法打满硬盘的读带宽。
这样的优化未来会成为模型推理的标准配置,因为随着 LLM 被越来越多的人使用,削峰填谷的能力会变得越来越重要。一个 8B 的模型在 safetensors load 的过程会花费 50s,而在 stream 的过程中只需要 15s。
镜像加载
在模型之前,镜像的加载也是一个重要的问题。由于包含了 CUDA 和 PyTorch 等框架的原因,镜像的大小通常会超过 10GB。在 Kubernetes 中,有非常多的方式来加速镜像的加载。我们使用了 GCP image steaming 来加速镜像的加载。因为这是闭源的实现,我们不清楚其具体的实现细节,但是经过测试与 Drgaonfly 等开源的实现相比,它的性能略好。
关于这一问题,Modal 有一个很好的技术分享:Fast, lazy container loading in modal.com by Jonathon Belotti。他们使用了 Lazy pulling 的方式,并且对 FUSE 进行了非常多的调优与优化。GCP image streaming 根据实际效果,可能是一个类似的实现。
蚂蚁金服的 Head of Conatiner Infra 王旭在 2020 年有一篇文章镜像格式二十年的螺旋进化之路,里面提到对 OCIv2 的一些构想,但是很可惜 OCI image spec 一直停留在 v1.x。关于它的讨论也越来越少。对于大多数传统应用而言镜像加载的时间并不是一个很大的问题,但是对于 LLM 这样的模型推理服务而言,是非常值得优化的。理想情况下,镜像应该被 Hybrid eager and lazy 的方式被加载。在容器启动的时候只需要部分必要的内容,开始进行模型的下载,在下载的过程中应该打满网络带宽。模型下载完成,在加载模型时或后,镜像可以继续下载,这样可以全程充分利用 IO 资源。
Autoscaling
我们采取了与 OpenFaaS 类似的系统设计以支持自动扩缩容的实现。
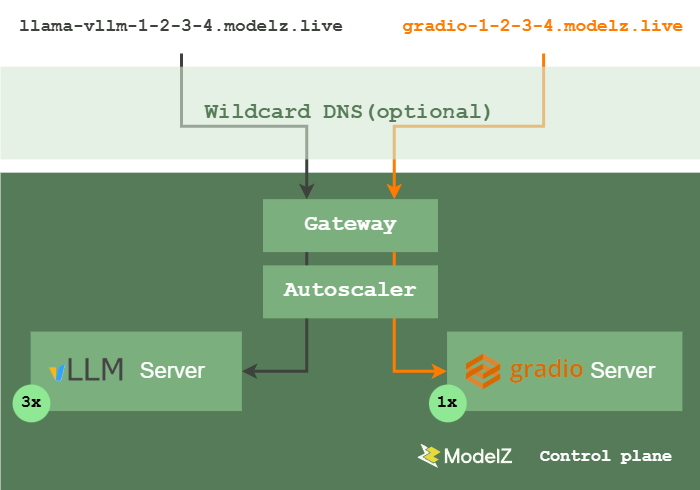
用户所有的请求会经过 Gateway,由于存在服务被缩容到 0 实例的情况,所以可能会存在没有对应服务的情况。在这种情况下,Gateway 会经由 Kubernetes controller 扩容服务。因此 Gateway 为了性能考虑,维护了一个集群内服务状态的缓存,以避免频繁地与 Kubernetes API server 交互。
除了从 0 到 1 的扩容工作由 Gateway 辅助完成,其他所有的扩缩容(从 1 到 多,从多到 1,从 1 到 0)工作都由 Autoscaler 负责。Autoscaler 会根据用户设置的参数和当前的负载情况来调整副本数。当前的负载情况,会由 Gateway 暴露的 Prometheus metrics 提供。
由于我们的系统基于公有云,因此除了推理服务的 Autoscaling,还会涉及到集群节点的 Autoscaling。不同的云服务商都提供了各自的 cluster autoscaler 实现,但通常而言 GPU 节点的扩缩容花费的时间在 1-5 分钟之间。这意味着如果我们在没有空闲节点的情况下需要扩容,可能会有 5 分钟的延迟。为了避免这一问题,我们使用了 cluster-proportional-autoscaler 来维护一个预留的 GPU 节点池。这也是架构图中的 placeholder 实例的来源。cluster-proportional-autoscaler 会根据集群的节点数量,来创建对应数量的 pod,并且对应关系是可配置的。比如在集群节点数小于 3 的时候,可以只创建 1 个 pod。在节点数小于 16 的时候,创建 2 个 pod 等。通过 taint 和抢占调度的设计,这些 pod 可以被当作 placeholder 来使用,占住 GPU 资源,避免扩容时的延迟。当有了新的推理服务需要部署时,这些 pod 会被抢占,让出资源。
在如此设计后,我们的集群是高度动态的,在节省成本的同时,也影响了镜像缓存的设计。被 cluster autoscaler 创建出的节点是没有任何镜像缓存的,因此在这些节点上部署服务时,需要重新下载所有镜像的所有层。为了解决这一问题,我们又引入了 kube-fledged 来进行节点的公共基础镜像预热。它允许用户定义一组镜像列表,它会负责在部分选定的节点上缓存这些镜像。这样,当有新的节点被创建时,kube-fledged 会自动将这些镜像缓存到新的节点上。但是它存在一个 bug,使得 cluster autoscaler 创建的新节点加入集群后不会触发预热,为此我们维护了自己的 fork。
Load Balancing
在 2023 年,还没有一个成熟的 LLM 的负载均衡方案。我们只是简单地使用 roundrobin 的方式在 Gateway 上进行负载均衡。因此 Gateway 既负责路由,又负责负载均衡。而 2024 年随着推理引擎上诸多 kvcache 优化的出现,对负载均衡也提出了新的挑战。
kvcache 使得对话场景下的 LLM 推理服务不再是无状态的。针对这一问题,目前有两种思路。首先是 kvcache 的 live migration。目前我看到的工作有 LMCache,它支持把 kvcache 通过 redis 等方式进行共享。类比传统的应用相当于分布式 session(会话)管理。用户相关的 kvcache 在多个实例间共享,这样就不需要复杂的负载均衡策略。
感谢 Yuandong Xie, Junyu Chen, Jingjing Zhou, Keming Yang 和 Zilong Cui 对本文的贡献。
License
- This article is licensed under CC BY-NC-SA 3.0.
- Please contact me for commercial use.