
随着 LLM 的火爆,向量数据库也成为了一个热门的话题。只需要一些简单的 Python 代码,向量数据库就可以为你的 LLM 插上一个廉价但极有效的“外接大脑”。但是,我们真的需要一个(专门的)向量数据库吗?
LLM 为什么需要向量搜索?
首先,我来简单介绍一下 LLM 为什么需要用到向量搜索技术。向量搜索是一个非常有年头的问题了。给定一个对象,在一个集合中找到与它最相似的对象的过程,就是向量搜索。文本/图片等内容,都可以通过将其转换为向量的表示方式,进而将文本/图片的相似度问题转换为向量的相似度问题。
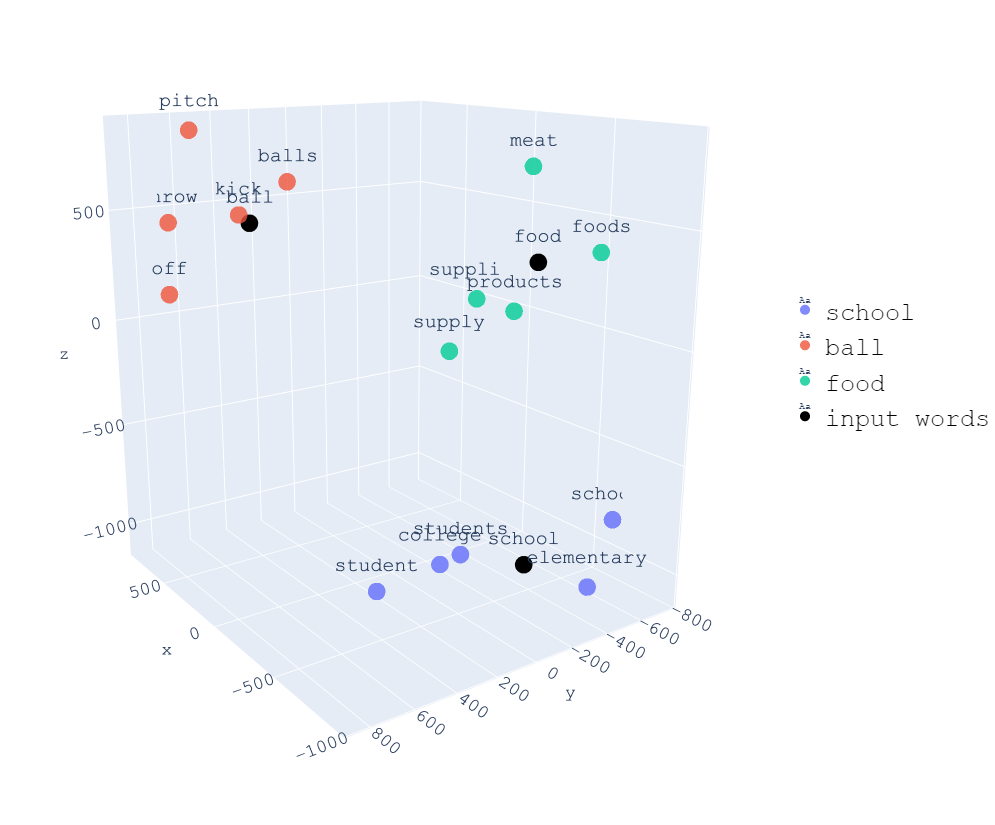
在上面的例子中,我们将不同的词语转换为一个三维的向量。因此我们可以在一个 3D 空间里直观的展示不同词语之间的相似度。例如,student 和 school 之间的相似度就比 student 和 food 之间的相似度更高。
回到 LLM 的场景里,模型的上下文(context)的长度限制是一个让人头疼的问题。比如 ChatGPT 3.5 的上下文长度限制在 4k tokens。LLM 最令人惊讶赞叹的能力之一就是 context-learning,这一限制很影响模型的使用体验。而向量搜索可以非常巧妙地绕过这一问题:
- 将超出上下文长度限制的文本划分成较短的 chunks,将不同的 chunks 转换为向量(embedding)。
- 在输入 prompt 到 LLM 之前,也将 prompt 转换为向量(embedding)。
- 将 prompt 向量进行搜索,寻找到最相似的 chunk 向量。
- 将最相似的 chunk 向量与 prompt 向量拼接,作为 LLM 的输入。
这样相当于我们给予了 LLM 一个外部的记忆,让它可以从这个记忆中搜索到最相关的信息。这个记忆就是向量搜索带来的能力。如果你想了解更多细节,可以阅读这篇文章和这篇文章,它们解释地更加清楚。
为什么向量数据库如此受欢迎?
在 LLM 中向量数据库成为了必不可少的部分,最重要的原因之一是易用性。在配合 OpenAI Embedding 模型(如 text-embedding-ada-002 等)后只需要十行左右的代码,就可以实现将 prompt query 转换成向量,随后进行向量搜索的整个过程:
def query(query, collection_name, top_k=20):
# Creates embedding vector from user query
embedded_query = openai.Embedding.create(
input=query,
model=EMBEDDING_MODEL,
)["data"][0]['embedding']
near_vector = {"vector": embedded_query}
# Queries input schema with vectorized user query
query_result = (
client.query
.get(collection_name)
.with_near_vector(near_vector)
.with_limit(top_k)
.do()
)
return query_result
向量搜索在其中主要起到了召回的作用。通俗来讲,召回就是在候选集中找到最相近的一些对象。在 LLM 中,候选集就是所有的 chunks,而最相近的对象就是与 prompt 最相似的 chunk。向量搜索在 LLM 推理的过程中,被当做了最主要的召回的实现。它实现简单,并且可以借助 OpenAI Embedding 模型来解决最麻烦的文本转换为向量的问题。剩下的就是独立且干净的向量搜索问题,目前的向量数据库都可以很好地完成搜索,因此整个流程特别顺畅。
向量数据库,顾名思义,是专门为了向量这一特殊的数据类型设计的数据库。向量的相似度计算,原本是 O(n^2) 复杂度的问题,因为要两两比较集合中所有的向量。因此工业界提出了近似近邻(ANN)的算法。利用 ANN 的算法,在向量数据库中通过预先计算的方式构建向量的索引,用空间换时间的思路,可以大大加快相似度计算的过程。这与传统的数据库的索引异曲同工。
因此,向量数据库不仅性能强,易用性又好,与 LLM 真的是绝配!(吗?)
通用数据库或许更好?
前面介绍了非常多向量数据库的优势与好处,那么,它存在什么问题呢?SingleStore 的博文珠玉在前,给出了一个很好的答案:
Vectors and vector search are a data type and query processing approach, not a foundation for a new way of processing data. Using a specialty vector database (SVDB) will lead to the usual problems we see (and solve) again and again with our customers who use multiple specialty systems: redundant data, excessive data movement, lack of agreement on data values among distributed components, extra labor expense for specialized skills, extra licensing costs, limited query language power, programmability and extensibility, limited tool integration, and poor data integrity and availability compared with a true DBMS.
向量和向量搜索是一种数据类型和查询处理方法,而不是处理数据的新方法的基础。使用专业向量数据库(SVDB)将导致我们在使用多个专用数据库的客户中一次又一次看到(并解决)的常见问题:冗余数据、过度的数据搬运、分布式组件之间的数据缺乏一致性、专业技能的额外劳动力成本、额外的许可成本、有限的查询语言能力、可编程性和可扩展性、有限的工具集成、以及与真正的DBMS相比较差的数据完整性和可用性。
其中有两个问题是我觉得比较重要的。首先是数据一致性的问题。在进行原型实验的阶段,向量数据库非常合适,易用性战胜一切。但是向量数据库是一个独立的,与其他数据存储(如 TP 数据库,AP 数据湖等)完全解耦的系统。因此数据需要在多个系统之间同步、流转、处理。
想象一下,如果你的数据已经存储在了 PostgresQL 等 OLTP 数据库中,使用独立的向量数据库进行向量搜索就需要将数据首先取出数据库,随后利用 OpenAI Embedding 等服务将其逐个转换成向量,然后再同步到专门的向量数据库中。这会增加非常多的复杂度。更复杂的地方在于,如果用户在 PostgresQL 中删除了某一条数据,但是向量数据库中没有删除,那么就会出现数据不一致的问题。这个问题在实际的生产环境中,可能是非常严重的。
-- Update the embedding column for the documents table
UPDATE documents SET embedding = openai_embedding(content) WHERE length(embedding) = 0;
-- Create an index on the embedding column
CREATE INDEX ON documents USING ivfflat (embedding vector_l2_ops) WITH (lists = 100);
-- Query the similar embeddings
SELECT * FROM documents ORDER BY embedding <-> openai_embedding('hello world') LIMIT 5;
而如果这一切都在一个通用的数据库中完成,用户的使用过程可能会比独立的向量数据库要更加简单。向量只是其中的一种数据类型,而不是一个独立的系统。这样一来,数据的一致性就不再是问题。
其次是查询语言的问题。向量数据库的查询语言通常是专门为向量搜索设计的,因此在其他的查询上可能会有很多限制。例如 metadata filtering 场景,用户需要根据某些 metadata 的字段进行过滤。部分向量数据库支持的过滤 operator 是有限的。
除此之外,metadata 支持的数据类型也非常有限,通常只包括 String, Number, List of Strings, Booleans。这对于复杂的 metadata 查询是不友好的。
而如果传统数据库能够支持向量这一数据类型,那么就不存在上面提到的问题。首先数据一致性的自不必说,生产环境中的 TP 或是 AP 数据库都是已有的基础设施。其次,查询语言的问题也不复存在,因为向量数据类型只是数据库中的一种数据类型,因此,向量数据类型的查询可以使用数据库原生的查询语言,例如 SQL。
更详细的解释
但是,只跟向量数据库的缺点进行比较,明显是不公平的。我可以轻松列出一些反驳的理由:
- 向量数据库的易用性非常好,用户可以轻松地使用向量数据库,而不需要关心底层的实现细节。
- 向量数据库的性能是传统数据库无法比拟的。整个数据库是专门为向量搜索设计的,因此在性能上有着天然的优势。
- 虽然 metadata filtering 的功能有限,但是向量数据库提供的能力已经可以满足大部分的业务场景了。
对于这些问题,阁下又该如何应对呢?接下来我以回答问题的方式来分享我的观点。
Q: 向量数据库的易用性非常好,用户可以轻松地使用向量数据库,而不需要关心底层的实现细节。
这个问题的答案是肯定的。向量数据库的易用性确实非常好,用户可以轻松地使用向量数据库,而不需要关心底层的实现细节。但这并不是向量数据库独有的。与传统数据库相比,向量数据库的易用性主要源于对特定领域的抽象。因为只需要关注向量这一个场景,因此可以为其专门设计概念,并且针对机器学习领域最常用的 Python 编程语言做更有针对性的优化和支持。
而这些并不是只有向量数据库独有的,而是聚焦在向量这一场景带来的收益。如果传统数据库也能够支持向量这一数据类型,那么同样可以提供类似的易用性。独立于数据库标准的接口之外,传统数据库也可以提供类似于各个向量数据库的 Python SDK,以及其他的工具集成,来满足绝大多数场景的需求。不仅如此,传统数据库还可以通过标准的 SQL 接口,满足更复杂的查询场景。
向量数据库另外一部分易用性源于分布式。大部分向量数据库的设计可以横向扩展节点,满足用户的数据量和 QPS 的需求。但是,这也并不是向量数据库独有的。传统数据库也可以通过分布式的方式来满足用户的需求。当然更重要的是,又有多少用户的数据量和 QPS 需要分布式的能力呢。而从另一个角度讲,如果向量的规模并不大,为什么还要引入一个新的数据库呢?
Q:向量数据库的性能是传统数据库无法比拟的。整个数据库是专门为向量搜索设计的,因此在性能上有着天然的优势。
关于性能,首先我们分析一下,LLM 场景下性能的瓶颈在哪里。下图是一个向量检索的朴素的 benchmark。在这个 benchmark 中,随机初始化了 256 维的 N 个向量,然后统计了在不同规模的 N 下,取 top-5 最近邻的查询时间。并且利用了两个不同的方式进行了测试:
- Numpy 进行“实时”计算,执行完全精确,非预先的最近邻计算。
- Hnswlib 使用 Hnswlib 预先计算近似的最近邻。
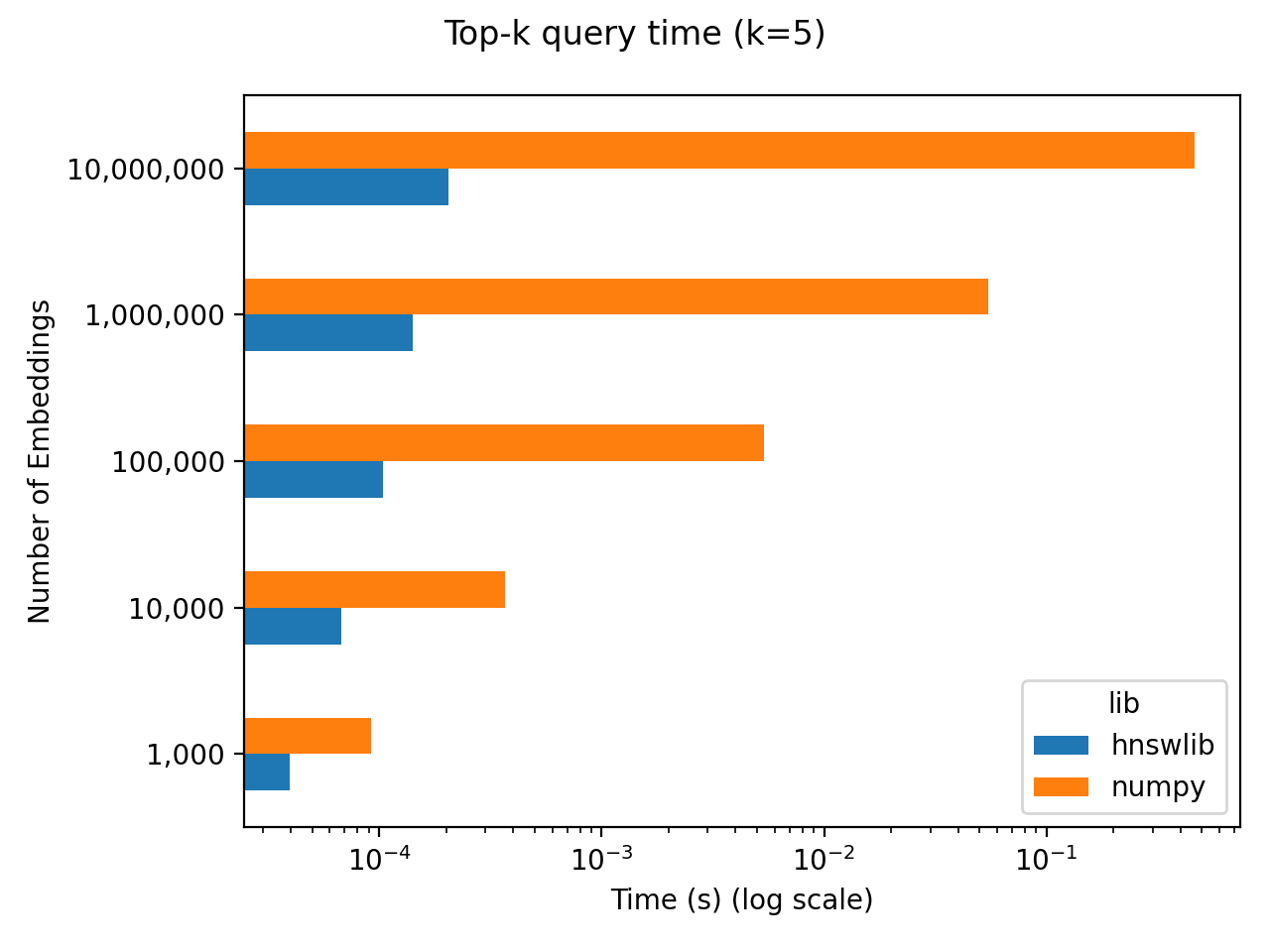
可以看到,在 1M 向量的规模下,numpy 实时计算的延迟大约在 50ms。我们以此为基准,对比完成向量搜索后,后续 LLM 推理花费的时间。7B 模型在 Nvidia A100(40GB) 上进行 300 个中文字符的推理大约需要 10s。所以哪怕是 numpy 实时精确计算 1M 个向量的相似度的查询时间,在整个端到端的 LLM 推理中,也只占了总延迟的 0.5%。所以在延迟上,向量数据库带来的收益在当下的 LLM 场景下被 LLM 本身的延迟所掩盖了。那么,我们再看看吞吐。LLM 的吞吐是远远低于向量数据库的。所以我也觉得向量数据库的吞吐并不是这个场景下的核心问题。
那么如果性能并不重要,什么问题会决定用户的选择呢?我认为是广义上的易用性。这不止包括使用的易用性,还包括运维的难易程度,一致性等数据库领域问题的解决方案。这些问题在传统数据库中已经有了非常成熟的解决方案,而向量数据库还处于起步阶段。
Q: 虽然 metadata filtering 的功能有限,但是向量数据库提供的能力已经可以满足大部分的业务场景了。
metadata filtering 不仅仅是支持的算子数量的问题,背后更重要的是数据的一致性问题。向量中的 metadata 本就是传统数据库中的数据,而向量本身是数据的索引。既然如此,为什么不直接将向量和 metadata 存储都存储在传统数据库中呢。
传统数据库的向量支持
既然我们认为向量只是传统数据库的一个新的数据类型,那么接下来我们就来看看,如何在传统数据库中支持向量数据类型。这里我们以 Postgres 为例。pgvector 是一个开源的 Postgres 插件,可以支持向量数据类型。pgvector 默认使用精确的计算方式,但是也支持建立 IVFFlat 索引,利用 IVFFlat 算法预先计算 ANN 的结果,牺牲计算的准确性换取性能。
pgvector 已经对向量做了非常好的支持,被 supabase 等产品使用。但是它支持的索引算法有限,只有最简单的 IVFFlat,也没有进行任何的量化或存储上的优化。并且 pgvector 的索引算法对磁盘并不友好,是为在内存中使用而设计的,在传统数据库生态中 DiskANN 等针对磁盘设计的向量索引算法也是非常有价值的。
而如果要扩展 pgvector,则困难重重。pgvector 是用 C 语言实现的,尽管已经开源两年,但目前只有 3 个贡献者。pgvector 的实现并不复杂,那么何不 rewrite it in Rust?

使用 Rust 重写 pgvector 能够让代码以更现代的方式组织,更容易扩展。Rust 的生态也非常丰富,faiss 等已经有了对应的 Rust binding。
pgvecto.rs 由此诞生。pgvecto.rs 目前已经支持了精确的向量查询操作和三个距离计算的算子。目前正在设计和实现 index 的支持。除了 IVFFlat 之外,我们也希望能够支持 DiskANN、SPTAG、ScaNN 等更多的索引算法,非常欢迎大家的贡献和反馈!
-- call the distance function through operators
-- square Euclidean distance
SELECT array[1, 2, 3] <-> array[3, 2, 1];
-- dot product distance
SELECT array[1, 2, 3] <#> array[3, 2, 1];
-- cosine distance
SELECT array[1, 2, 3] <=> array[3, 2, 1];
-- create table
CREATE TABLE items (id bigserial PRIMARY KEY, emb numeric[]);
-- insert values
INSERT INTO items (emb) VALUES (ARRAY[1,2,3]), (ARRAY[4,5,6]);
-- query the similar embeddings
SELECT * FROM items ORDER BY emb <-> ARRAY[3,2,1] LIMIT 5;
-- query the neighbors within a certain distance
SELECT * FROM items WHERE emb <-> ARRAY[3,2,1] < 5;
未来
随着 LLM 逐渐进入生产环境,对于基础设施的要求越来越高。向量数据库的出现,是基础设施的一个重要的补充。我们并不认为向量数据库与传统数据库会互相取代,而是会在不同的场景下发挥各自的优势。向量数据库的出现,也会促进传统数据库对向量数据类型的支持。我们希望 pgvecto.rs 能够成为 Postgres 生态中的一个重要的组成部分,为 Postgres 提供更好的向量支持。
License
- This article is licensed under CC BY-NC-SA 3.0.
- Please contact me for commercial use.