
2024.12.24: 本文部分评论可见 Hacker News
Original post: VectorChord: Store 400k Vectors for $1 in PostgreSQL
我们很高兴地宣布推出适用于 PostgreSQL 的新向量搜索扩展,它提供了一种非常经济高效的方法来管理大型向量。使用 VectorChord,您可以对 top 10 查询的 1 亿个 768 维向量实现 131 的 QPS 和 0.95 的精度。此设置每月仅需 250 美元,并且可以托管在一台机器上。
这意味着只需 1 美元即可存储 400k 个向量,从而大幅节省成本:与 Pinecone(存储优化实例)相比,向量数量多 6 倍,与 pgvector/pgvecto.rs 相比,价格相同,向量数量多 26 倍。
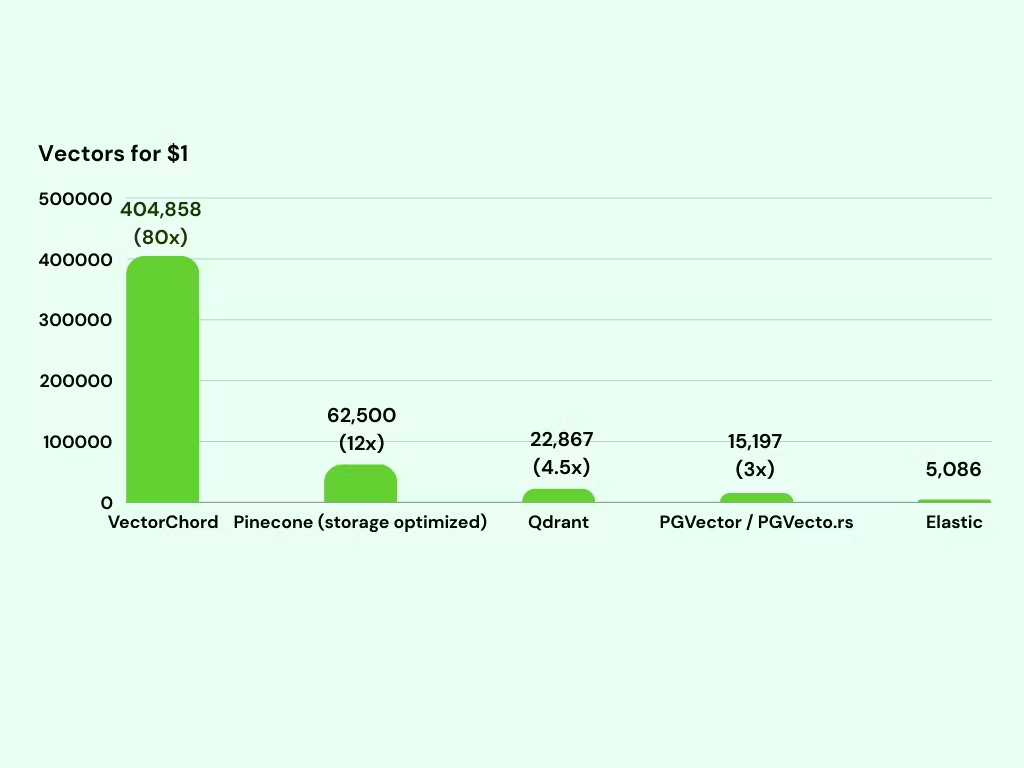
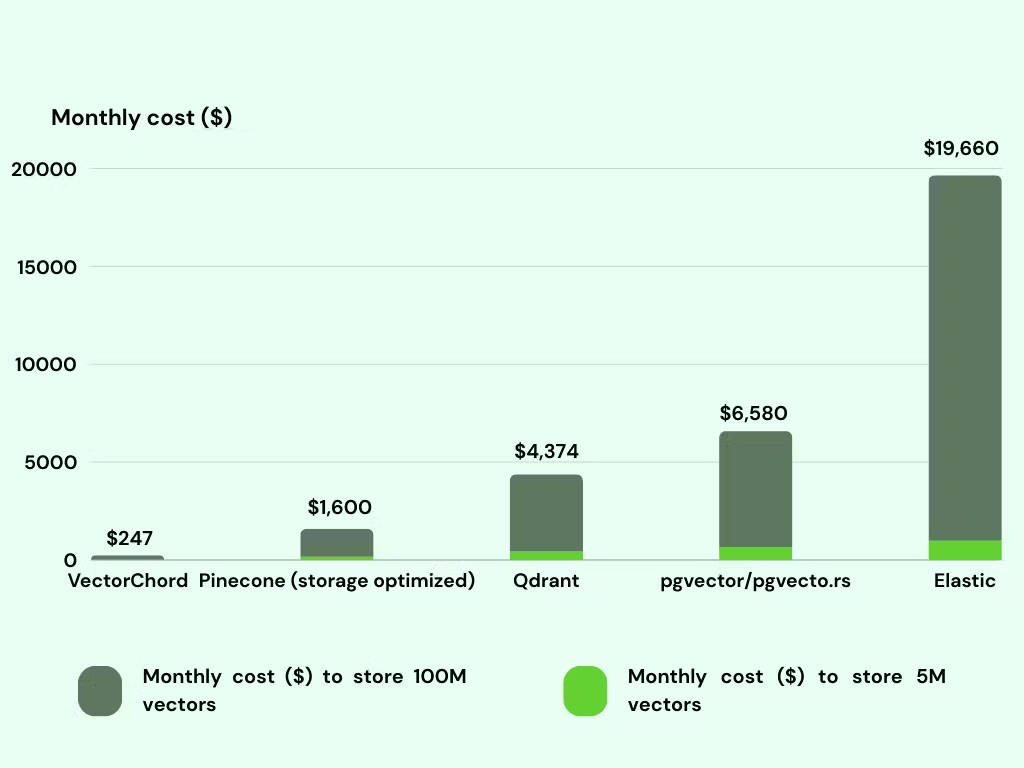
在基于 MyScale Benchmark 数据的向量存储月度成本比较中,突出展示了 VectorChord 如何成为一种经济实惠的选择,存储 1 亿个向量的价格仅为 247 美元。相比之下,尽管 Pinecone 的存储经过了优化,但每月成本为 1,600 美元,而 Qdrant 的价格为 4,374 美元。pgvector/pgvecto.rs 的成本要高得多,为 6,580 美元。
HNSW 的问题
作为 PGVecto.rs 的继任者,VectorChord 从其前身中获得了宝贵的见解。虽然许多矢量数据库或扩展(包括 PGVecto.rs)在处理约 100 万个数据集时表现良好,但它们在扩展到更大的规模时往往会遇到困难,例如从 1000 万到 1 亿。传统的基于 HNSW 的矢量数据库在处理更大的数据集时面临特定挑战:
- 索引构建时间长:通常需要 2 个多小时才能为 500 万条记录构建索引。
- 高内存要求:存储 1000 万个向量的数据集可能需要多达 40GB 的内存。
VectorChord 的解决方案:磁盘友好型 IVF+RabitQ
VectorChord 采用 IVF(倒排文件索引)和 RaBitQ[1] 量化来提供快速、可扩展且准确的向量搜索功能。此方法将 32 位向量压缩为紧凑的位表示,从而显著减少计算需求。大多数比较都是使用这些压缩向量进行的,而全精度计算则保留用于应用于较小子集的自适应重新排序阶段,以确保速度和召回率均得到保留。
许多人认为 IVF 的召回率/速度权衡不如 HNSW,并且需要进行许多优化配置。然而,这是一个复杂的问题,我们现在将简要解释一下,稍后会发布有关该主题的详细文章。
IVF vs. HNSW
向量搜索算法花费的时间中很大一部分用于距离计算。为了提高速度,必须尽可能减少距离比较。原始 IVF 在这方面遇到了困难,通常需要扫描总向量的 1% 到 5%,这比 HNSW 的要求高得多。
然而,RabitQ 提出了一种创新方法,可以将 32 位向量压缩为 1 位。虽然这种压缩会导致一些精度损失,但大大降低了计算要求。通过快速扫描优化,我们可以实现比传统向量距离计算快 100 倍以上的计算。
您可能想知道召回率。我们可以重新排序其他向量以提高召回率,并且只有在重新排序阶段才需要进行全精度距离计算。RaBitQ 保证了严格的理论误差界限,同时提供了良好的经验准确性。这就是 IVF 比 HNSW 更快的原因。
以下是 GIST 数据集的一些初始基准测试结果,该数据集包含 960 个维度的 100 万个向量。在召回率相同的情况下,VectorChord 的 QPS 可能是 pgvector 的两倍。更多详细信息将在 Benchmark 章节提供。
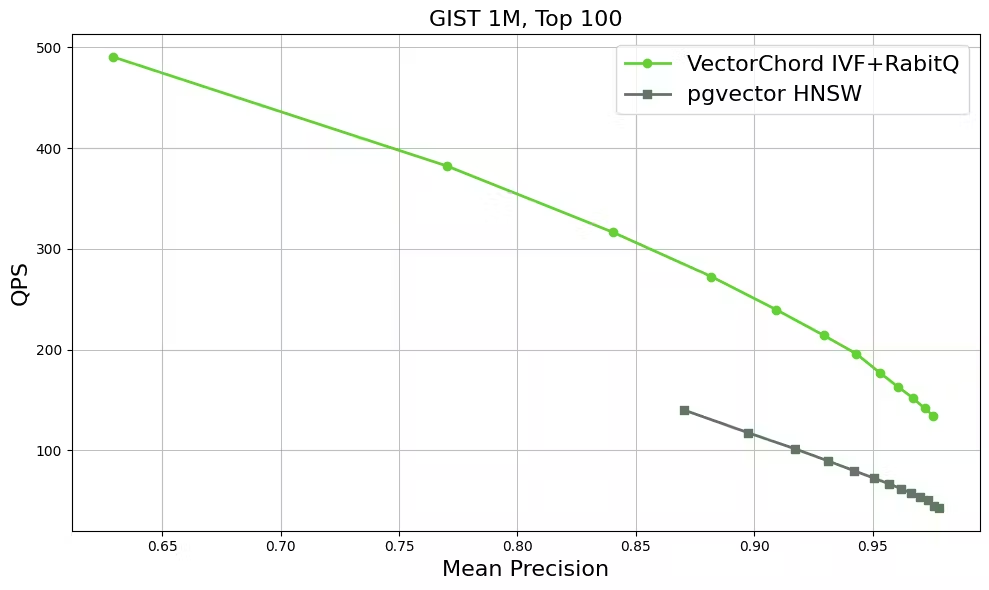
External Index build
原始 IVF 方法通常需要扫描 1-5% 的数据集,这可能会很慢。通过使用 RaBitQ 和快速扫描优化,VectorChord 旨在通过减少需要完全比较的全精度向量数量来加快计算速度。这种方法有助于创建一个稳定且可扩展的向量搜索系统,该系统可与 PostgreSQL 存储系统很好地配合使用。因此,用户可以将物理复制和其他 PostgreSQL 功能与 VectorChord 一起使用。
VectorChord 基于 IVF 构建,允许在外部(例如在 GPU 上)进行 KMeans 聚类并轻松导入数据库。我们在具有 2 个 vCPU 和 16 GB RAM 的 AWS i4i.large 实例上执行了测试以测量索引和插入时间。用于此测试的数据集是 GIST 1M。我们插入了 700,000 个向量,构建了索引,然后添加了另外 300,000 个向量。在预热系统后,我们使用单个线程执行查询。在这个过程中,我们评估了索引的构建时间和插入时间。结果如下:
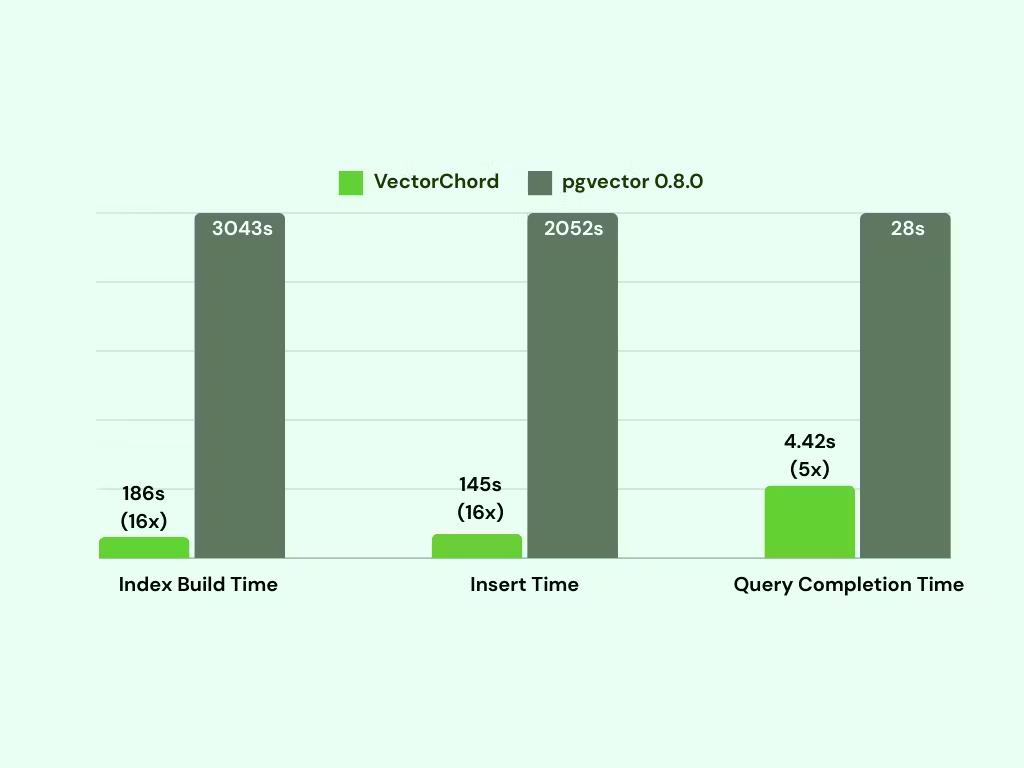
VectorChord 使用一台单独的机器进行 KMeans 聚类,构建索引耗时 186 秒,比 pgvector 快 16 倍。此外,插入时间也比 pgvector 快 14 倍。众所周知,索引是向量数据库中最耗资源的部分,需要大量计算,增加了对 CPU 和内存的需求。通过使用更强大的机器构建索引,然后将其导入到更小的机器进行查询,可以在单台机器上支持数十亿个向量。
Benchmark
我们进行了额外的实验,使用 LAION 5M 和 100M 数据集更彻底地评估性能和成本。
LAION 5M
我们使用 LAION 5M 数据集进行了实验,结果对 Vectorchord 来说令人鼓舞。与其他平台相比,它始终实现更高的每秒查询数 (RPS)。虽然许多数据库在召回率提高时难以在速度和准确率之间保持平衡,但 Vectorchord 即使在更高的召回率水平下也能保持高效。这一特性使其成为需要快速响应和准确率的应用程序的合适选择。
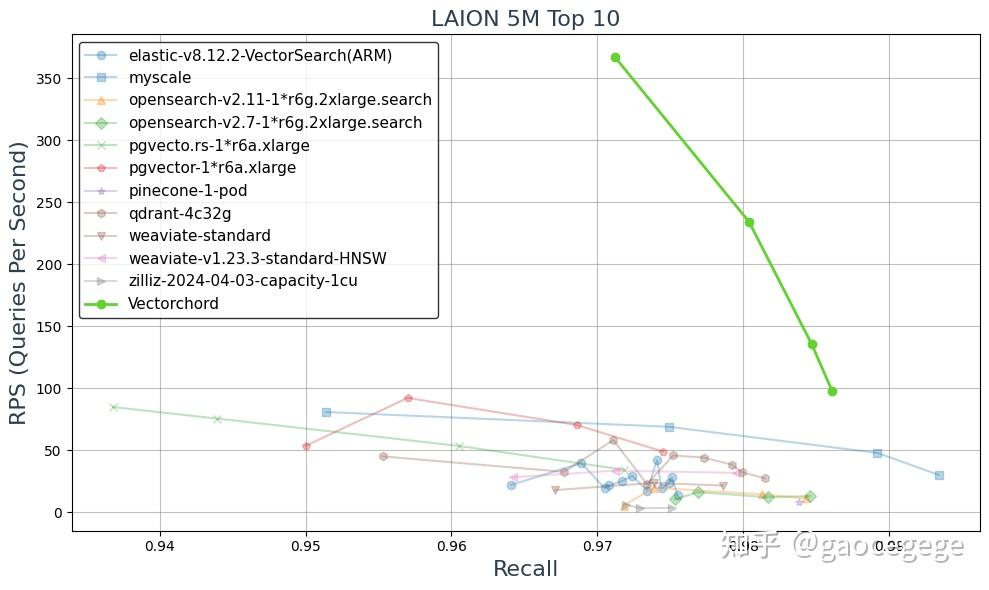
实验采用 Myscale Benchmark,在一台 r6a.xlarge 机器上进行,该机器具有 4 个 vCPU、32GB 内存和 200GB EBS 存储。实验设置的参数包括 nlist 为 8192、共享缓冲区为 28GB、JIT 禁用、有效 I/O 并发数为 200。我们在没有预热的情况下进行了两次实验。
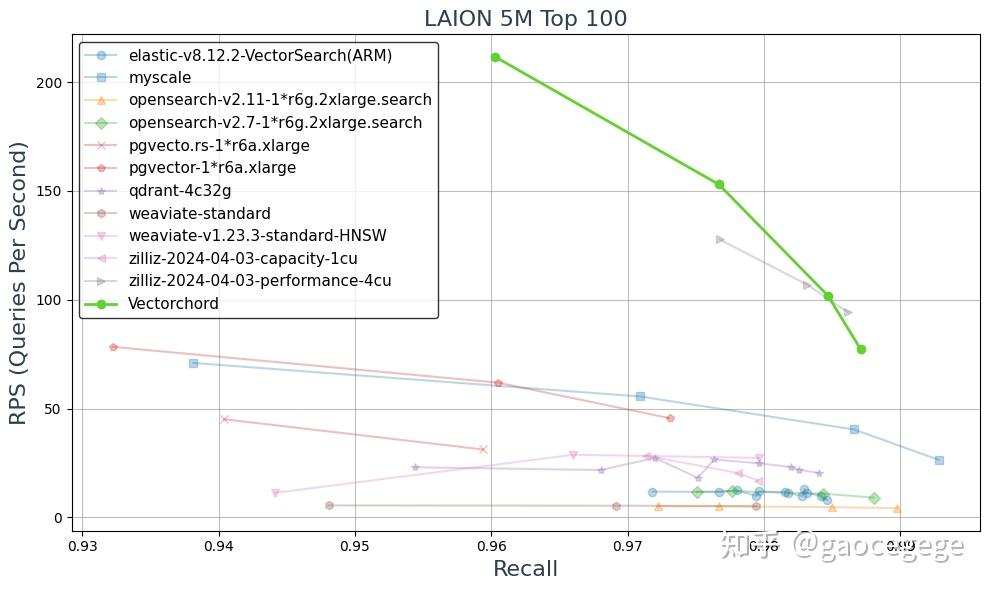
我们使用的机器是一台 r6a.xlarge,每月成本约为 165.56 美元,我们在 LAION 5M 数据集的 Top 100 中取得了相当的性能。
单机支持 LAION 100M
此外,由于其磁盘友好的索引功能,增加单台机器的磁盘容量可以成比例地提高 VectorChord 可以容纳的最大向量数量,可能允许存储 10 亿或更多。
为了评估可扩展性,我们使用 AWS i4i.xlarge 实例对 LAION 100M 数据集(768 个维度)进行了实验,这是一个经济实惠的配置,每月价格为 250 美元。
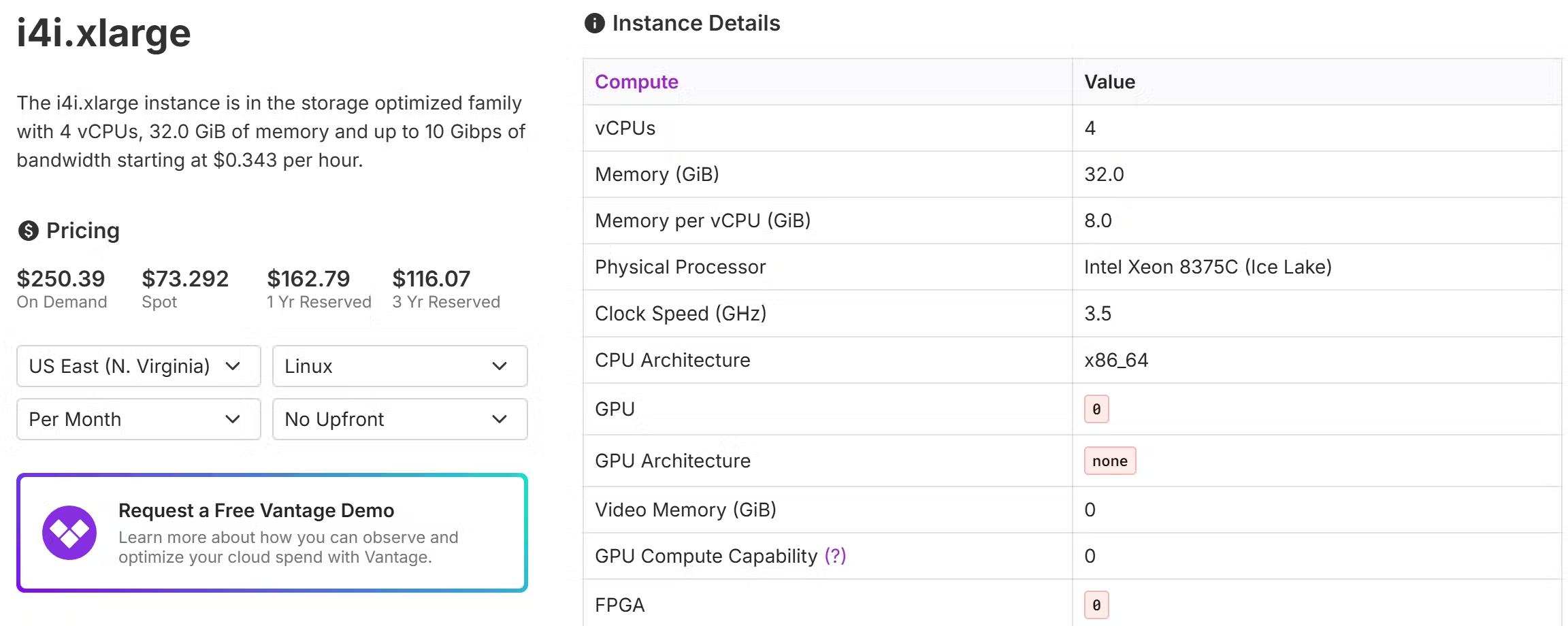
它只有 4 个 CPU 和 32 GB 内存,其中 937 GB 的 SSD 用于存储 1 亿个向量。在此设置下,我们通过单线程查询实现了前 10 个结果的 QPS 为 16.2 @ recall 0.95,前 100 个结果的 QPS 为 4.3 @ recall 0.95。以下是令人印象深刻的结果:
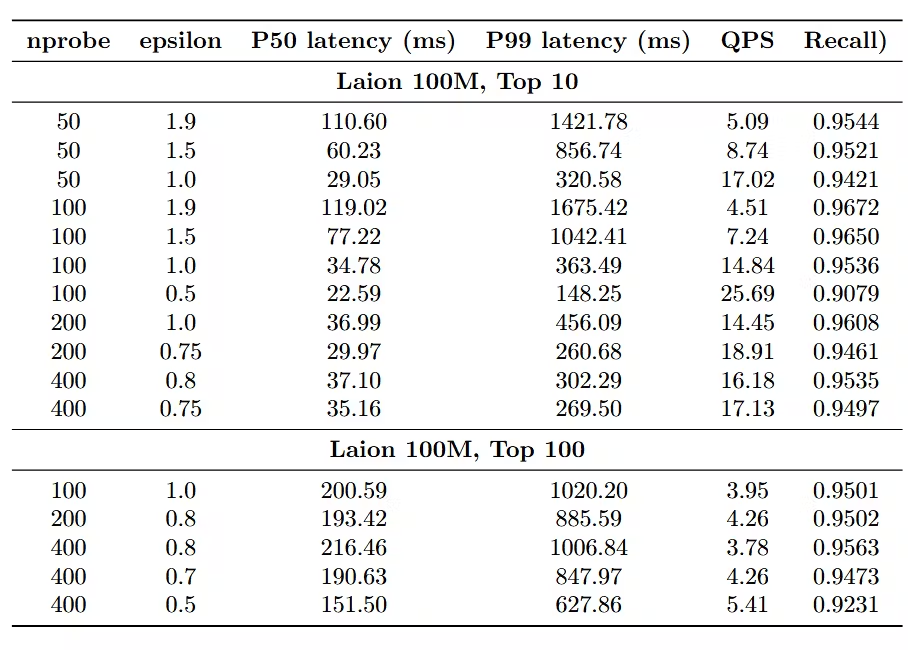
在保持召回率大于0.95的前提下,我们还在这台4vCPU的机器上测试了多线程QPS,在这个场景下,随着请求线程数从1个增加到8个,向量查询的QPS可以线性提升,说明VectorChord具有很好的可扩展性。
总结
VectorChord 是专为高效向量搜索而设计的一款新 PostgreSQL 扩展。它允许用户仅用 1 美元存储 400,000 个向量,比竞争对手便宜得多。通过利用 IVF 和 RaBitQ 量化,VectorChord 优化了搜索速度和内存使用率,使其适用于大型数据集。
我们在 PGVecto.rs Cloud 为 VectorChord 提供云托管服务。我们的平台简化了部署和管理,使您能够轻松高效地扩展向量数据库解决方案。如果您对 VectorChord 有任何疑问,请随时联系我们。我们随时为您提供帮助!您可以在我们的存储库中打开问题,也可以发送电子邮件至 vectorchord-inquiry@tensorchord.ai。
License
- This article is licensed under CC BY-NC-SA 3.0.
- Please contact me for commercial use.