这个lab,本来是打算着压着DeadLine写完的,但是后来发现并不是很难,不像上一个lab,简直就是逆天的难度。总体来说,这次的lab还是不难- -前几天在熊神的博客里看到了这个lab的经验,妈蛋要是早点看到就好了。
代码
我的代码在这里,仅供参考哦
第一道题目
第一个题目rotate,就是把这个矩阵90度旋转嘛,似乎这个题目也可以分块做(其实我也是分块啦),把矩阵分为1616或者3232的size的块,按块转,其实差不多,都是一样的写缓存命中率吧(大概)。
我的做法是先分成32*dim的块,然后把读取src的缓存命中改为dst的写缓存命中,因为在上课的时候问了鑫爷他说写缓存命中更划算(也不知道是不是真的),但是改完以后真的快好多- -至于为什么这么分块,我也不知道,只是觉得32这个数字不错(其实只要跟测试数据整除就好了吧)- -大概直白点说我的方法就是先把矩阵第一列的前32个元素转到最后一行的前32个元素的位置,然后再把第二列的前32个元素转到倒数第二行的前32个元素的位置,转完前32行的所有以后再转接下去的32行。(横的是行,纵的是列)这样做了以后还是不够满分啊,再做些小优化,位运算什么的,就差不多了。
总体的思路就是变读缓存命中为写缓存命中。
第二道题目
至于第二题,都说很容易,可是我现在都没满分0 0真是惨,大神们是厉害啊。他的要求是求元素所在九宫格的平均数,放到这个元素中。我最初的想法是:因为很多加法是会重复去做,那我为何不把他们先存起来,用的时候直接拿出来用就可以了嘛,但是这样不是很快,效果不是很明显,至于问题出在哪里,不知道>_C等找到再说吧0 0这样做,SpeedUp是1.6似乎。
接下来我完全抛弃了这种做法,转而进行了一个艰苦卓绝的改动,把各种情况分开讨论,这种做法本质是很好的,最终我用这个方法达到了3.8,最初的时候,我把这个方法想的太复杂,做了很多自己认为是优化的优化,但是反而只有2.6。
但是其实就是单纯把情况分开讨论,然后再简简单单的把九宫格里的值一次加起来再求平均赋值给dst对应的位置,这样就有3.8了,我做了很多改动反而很低,不知道为啥。
其实在优化第二个函数的时候,我偶然间看到了一种优化方法,虽然可能实现以后提高不是很大(我没能成功),但是似乎很有意思。就是说,把除法转换成乘法。这个我也不是很懂, 自己试了试,发现如果是int类型的变量,只有整除的时候才能转换,这个鸡肋啊- -但是如果是无符号数,似乎可以万能转换。具体可以参考这个网站:http://www.cppblog.com/huyutian/articles/124742.html,但是用到这个函数里面,例如把/6变成*0x2aab>>16,老是不能通过test,但是我自己写一个测试程序发现是可以这么做转换的啊,我也不知道为啥- -希望有知道原因的可以告诉我下- -
题外话,我看到的最夸张的做法就是这个http://www.cs.utah.edu/~jking/lab3/kernels.c,这位名叫jeremy的神人对测试数据分情况讨论,代码长的吓人0 0,理论上来说我觉得会很快,但是其实慢的不行- -我也不知道是为什么- -很多时候自己认为很牛逼的优化实现以后反而cpe更大了0 0不科学。
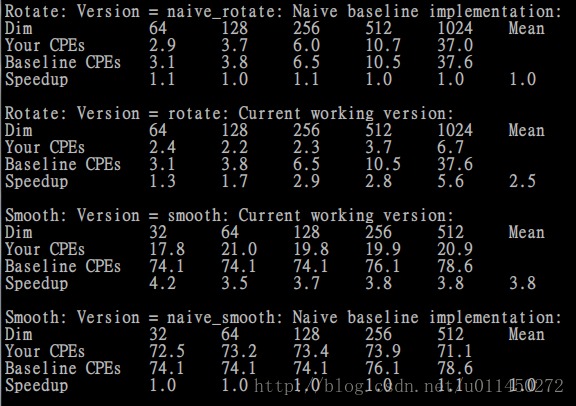
结果
最终的结果就是如图所示,印象中没有拿到满分啊=-=