
每一年,全球各地的软件工程师们都会在各种平台上开源各种各样的项目,这里面不乏一些设计优雅,实现精巧,又解决实际问题的优质开源项目。在互联网上寻找这样的项目,宛如在浩如烟海的沙漠中寻宝一般,充满了乐趣。最近忽然非常想分享一下自己私藏的开源项目宝库里那些暂时还不广为人知,或者已经成为过气网红的那些宝藏项目们。安利不会太过深入实现细节,一来我们中的绝大多数都没有时间,没有精力也没有动机真正地参与这些宝藏项目的开发工作;二来我也对很多项目的实现细节不甚了解 :-)
那么,今天聚光灯的主角是 Seldon Core,它是目前在 Kubernetes 上运行机器学习推理负载方面最受欢迎的项目之一。它来自一家 2014 年在英国创立的 AI 公司,其主要产品有 Seldon Core,Seldon Deploy 和 Seldon Alibi。Seldon 也是 Kubeflow KFServing 的积极参与者,Seldon 的 CTO Clive Cox 现在仍在深度地参与 KFServing 的特性设计。KFServing 的 Roadmap 中的许多特性,都能看到 Seldon Core 的影子。
在介绍 Seldon Core 之前,让我们先介绍一下为什么工业界会有在 Kubernetes 上运行机器学习推理负载的需求。
需求来自何方
机器学习的推理,指的是利用已经训练好的模型,对外提供服务的过程。举个例子,比如我们训练好了一个图像分类的模型。接下来,我们就需要把这个模型对外提供服务出去。我们可以把它包装成 RESTful 的服务,也可以通过 RPC 的方式对外暴露。模型的用户只需要通过接口传入一张图片,我们的模型推理服务会告诉用户,图片上的是猫是狗还是虎。
相比于传统的 RESTful 服务,它有一些自己的独特需求。首先,模型推理服务存在对 GPU 等设备的需求。它与训练相比,虽然计算量小很多,但是仍然可以利用 GPU 进行加速。除此之外,一般深度学习模型的推理服务除了模型服务本身,还需要一些前处理,后处理的逻辑。在更加复杂的场景下,可能还会涉及到模型与模型间的关联。比如在 OCR 场景中,有时需要一个模型先对图片进行悬正(就是把图片摆正),再把悬正好的输出作为接下来的模型的输入,进行下一步的处理。模型与模型,模型与前处理后处理逻辑等组成一个有向无环的推理图(DAG)。
因此,我们很难把它当做普通的 RESTful 或者是 gRPC 服务去部署。但我们仍然需要 Kubernetes,去解决一些共同的问题。比如资源调度,对 GPU 的监控,自动扩缩容,请求的监控,对流量的转发与 AB 测试等等。
那么那些在机器学习推理的场景下特有的需求,应该如何解决呢?这就是 Seldon Core 想要做的事情。
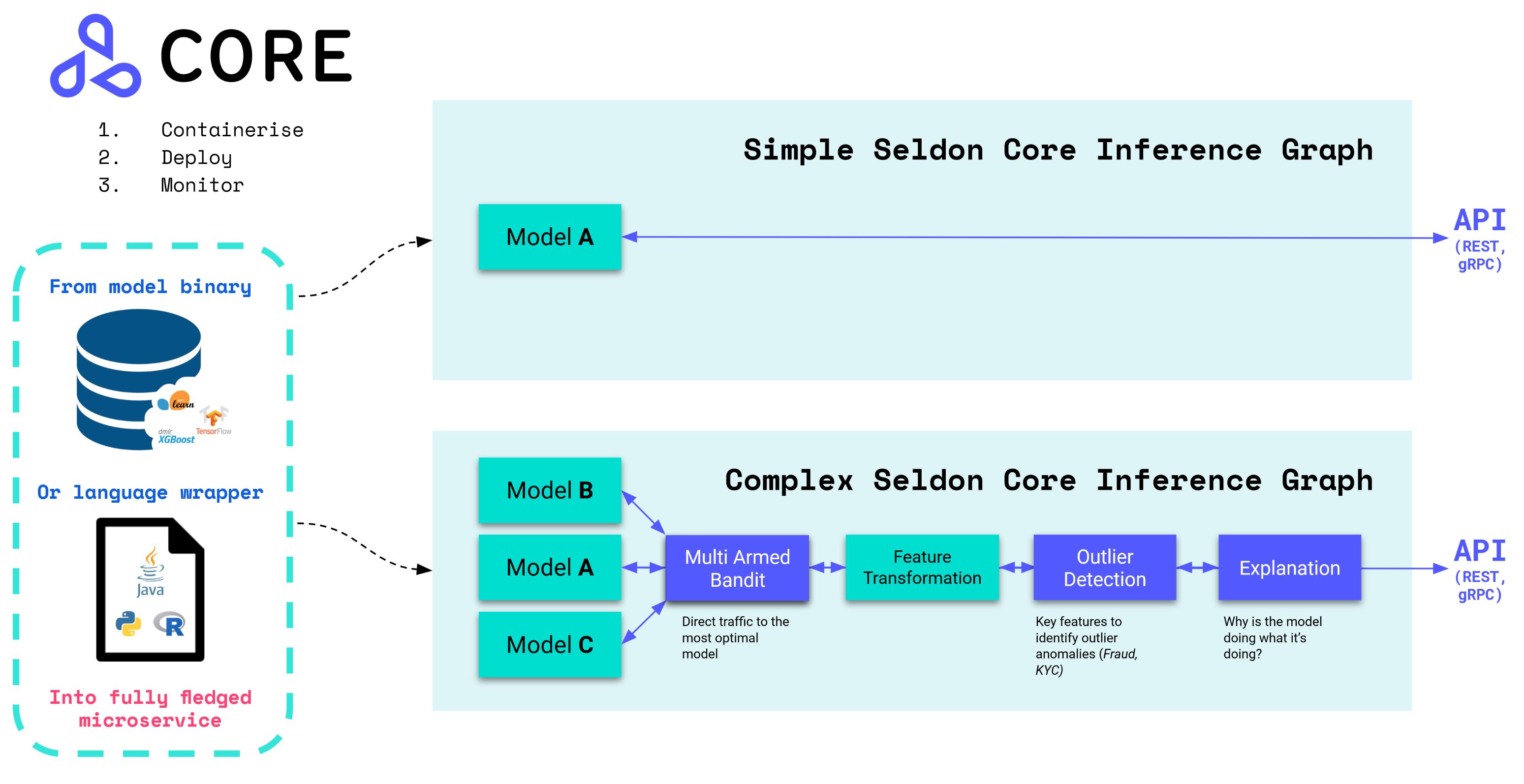
Seldon Core 支持简单的模型推理场景,也支持有向无环的推理图场景。比如在图中的第二个复杂的推理图,一共展示了四个特殊的模型服务的步骤组成的工作流。首先是 Explanation,它负责进行模型的解释。接下来是异常值检测,然后是特征转换 Transformer,最后是通过一个 Router,将流量路由到 A,B,C 三个模型中表现最好的模型中。
核心概念
为了支持推理图,Seldon Core 抽象出了五个组件,每个组件可以理解为是图中的一个节点:
- Model
- Router
- Combiner
- Transformer
- Output_Transformer
其中 Model 是模型,提供 REST 和 gRPC 服务。值得一提的是,Seldon Core 的模型是进行了封装的,提供的是封装后的 API,其输入和输出的格式都是统一的。
Router 是一个路由组件,但是除了路由功能之外,其还接受来自各个路由的节点的 reward feedback(激励反馈),支持实现多臂老虎机的逻辑。
{
"request": {
"data": {
"names": ["a", "b"],
"tensor": {
"shape": [1, 2],
"values": [0, 1]
}
}
},
"response": {
"data": {
"names": ["a", "b"],
"tensor": {
"shape": [1, 1],
"values": [0.9]
}
}
},
"reward": 1.0
}
Combiner 是一个跟 Router 类似的组件,区别在于它不是路由到某个节点,而是将其下所有的节点的输出进行结合,输出一个结合后的唯一的返回。
Transformer 和 Output_Transformer 是类似的组件,负责做输入与输出的转换,可以理解为是预处理和后处理的过程。
系统工作流
Seldon Core 以 Kubernetes CRD 的方式对外提供能力。它提供的 CRD 叫做 SeldonDeployment。
它的 CRD 的设计与 Argo Workflow 的设计类似,首先是组件的定义,Seldon Core 使用 PodTemplateSpec 来表示组件的定义。接下来是推理图的定义,类似于 Argo Workflow 的 DAG 定义。
apiVersion: machinelearning.seldon.io/v1alpha2
kind: SeldonDeployment
metadata:
name: seldon-model
spec:
name: test-deployment
predictors:
- componentSpecs:
- spec:
containers:
- name: step_one
image: seldonio/step_one:1.0
- name: step_two
image: seldonio/step_two:1.0
- name: step_three
image: seldonio/step_three:1.0
graph:
name: step_one
endpoint:
type: REST
type: MODEL
children:
name: step_two
endpoint:
type: REST
type: MODEL
children:
name: step_three
endpoint:
type: REST
type: MODEL
children: []
name: example
replicas: 1
当用户创建了 CRD 后,Seldon Core 的 Operator 会根据 CRD 的 Spec 创建对应的组件,并且对外暴露 RESTful 和 gRPC 的服务接口。其中组件是以容器的方式运行的,当用户访问暴露的服务接口时,Seldon Core 会根据用户在 CRD 的 Spec 中定义的 DAG 推理图来编排请求。
系统设计
具体 CRD 和对应的 Operator 的设计在这里不多做解释,这是大部分 Kubernetes 生态项目都经常涉及的设计。这里主要介绍一下 Seldon Core 是如何实现根据用户定义的 DAG 来路由请求的。
在推理图功能的实现中,Seldon Core 依赖一个 Golang 实现的 Executor(之前版本中被称作 Engine,由 Java Spring Boot 实现)。
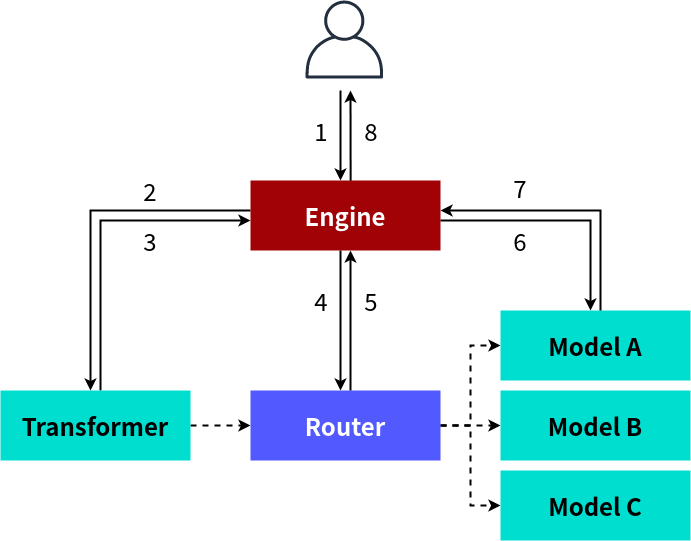
举例说明,当用户定义了推理图时,除了对应的组件,Seldon Core 会为图创建一个 Engine 实例。在这一推理图中,一共三个组件,分别是 Transformer,Router 和三个 Model。Transformer 负责做特征转换,Router 负责将请求路由到三个模型中表现最优的一个,三个模型各自提供服务。
在这一过程中,用户会通过 POST 调用 /api/v1.0/predictions 来访问这一推理图。请求会首先到达 Engine。Engine 会根据推理图的拓扑序,依次访问不同的组件。在这一例子中,首先调用 Transformer 提供的 /transform-input 接口,进行特征转换,随后调用 Router 选择出最优的模型实例。随后,将 Transformer 处理后的 Response 作为 Request 转发给最优模型,最后得到输出,并且发回给用户。
如果只是简单的模型推理,不需要推理图,可以通过修改 annotation 的方式为当前 SeldonDeployment 禁用 Engine。少一层应用层的网络转发,在 latency 上会有所改善。Seldon Core 中的分布式追踪能力,也是在 Engine 中实现的。通过在每次转发时做一些埋点,可以便捷地实现这一功能。
竞品在哪里
除了 Seldon Core 之外,目前也有很多关注在模型服务的开源项目。其中一类是如 TFServing,Triton Inference Server 等关注在模型服务器上的项目。这些项目与 Seldon Core 没有直接竞争关系,Seldon Core 自身也支持多种不同的模型服务器。另外一类是如 Clipper,KFServing 等同样关注在模型服务上的项目。目前 Clipper 已经许久没有更新了(不愧是实验室出来的项目),其他一些利用 Ray 做模型服务的非主流做法就不拿来比较了,主要来介绍一下 KFServing。
KFServing 是在 Kubeflow 社区开源模型服务项目,它依赖 Knative Serving 实现,也通过一个 CRD 对外提供服务。KFServing 定义了一个 CRD:InferenceService(以下简称 IS)。其中定义了两个 Endpoint:Default 和 Canary。其中 Default 是必填的,Canary 是可选的。Canary 支持金丝雀发布。
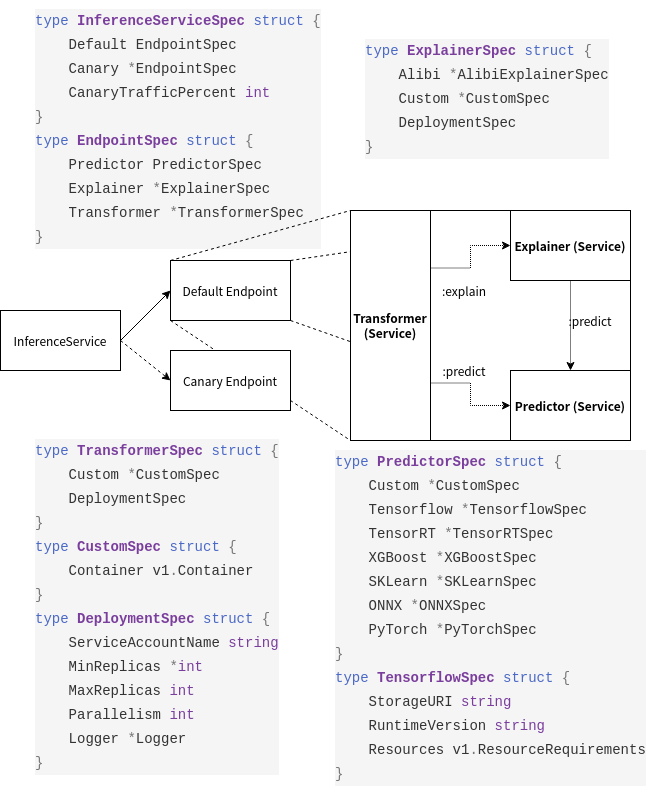
在发布时,每个 Endpoint 有三个组件,分别是 Predictor,Explainer,和 Transformer。其中 Transformer 支持对模型的预处理/后处理,为可选组件,无内置实现。Expainer 支持对模型的解释,内置有 Seldon 开源的模型解释库 Alibi 支持,同样为可选组件。Predictor 为真正的模型服务,为必需组件,内置有 TF,ONNX,Caffe 等格式的支持。
一个简单的示例如下所示:
apiVersion: serving.kubeflow.org/v1alpha2
kind: InferenceService
metadata:
name: transformer-cifar10
spec:
default:
predictor:
pytorch:
modelClassName: Net
resources:
limits:
cpu: 100m
memory: 1Gi
requests:
cpu: 100m
memory: 1Gi
storageUri: gs://kfserving-samples/models/pytorch/cifar10
KFServing 对 Seldon Core 的 DAG 推理图进行了简化。KFServing 只支持 Transformer,Predicator。在实现上,KFServing 因为进行了简化,所以不再需要 Seldon Core 中的 Engine 这一角色。请求在 Transformer 和 Predicator 间的转发由 SDK 负责。
Seldon Core 对用户代码的侵入性非常低。用户只需要提供对应的 HTTP/gRPC Endpoint 来提供服务就可以,而不需要引用 Seldon Core 的 SDK。因为组合各个请求的职责不是由用户代码负责,而是由 Engine 执行。而在 KFServing 中,用户如果想实现自己的预处理的逻辑,需要引用 KFServing 的 SDK,这就是因为缺失了 Engine,导致转发的逻辑要利用 SDK 来实现。
下面是一个例子。可以看到这一例子中引用了 kfserving 这一个包,同时定义了两个命令行参数。这都是为了要实现转发而做的妥协。当 Transformer 预处理好后,会直接转发给命令行参数中传来的 predictor_host。这里的 predictor_host 是 InferenceService 中定义的 Predicator 的服务地址。
import kfserving
import argparse
from .image_transformer import ImageTransformer
DEFAULT_MODEL_NAME = "model"
parser = argparse.ArgumentParser(parents=[kfserving.kfserver.parser])
parser.add_argument('--model_name', default=DEFAULT_MODEL_NAME,
help='The name that the model is served under.')
parser.add_argument('--predictor_host', help='The URL for the model predict function', required=True)
args, _ = parser.parse_known_args()
class ImageTransformer(kfserving.KFModel):
def __init__(self, name: str, predictor_host: str):
super().__init__(name)
self.predictor_host = predictor_host
self._key = None
def preprocess(self, inputs: Dict) -> Dict:
if inputs['EventType'] == 's3:ObjectCreated:Put':
bucket = inputs['Records'][0]['s3']['bucket']['name']
key = inputs['Records'][0]['s3']['object']['key']
self._key = key
client.download_file(bucket, key, '/tmp/' + key)
request = image_transform('/tmp/' + key)
return {"instances": [request]}
raise Exception("unknown event")
def postprocess(self, inputs: Dict) -> Dict:
logging.info(inputs)
index = inputs["predictions"][0]["classes"]
logging.info("digit:" + str(index))
client.upload_file('/tmp/' + self._key, 'digit-'+str(index), self._key)
return inputs
if __name__ == "__main__":
transformer = ImageTransformer(args.model_name, predictor_host=args.predictor_host)
kfserver = kfserving.KFServer()
kfserver.start(models=[transformer])
我为什么看好 Seldon Core
虽然目前关注在模型服务上的开源项目越来越多,但是我仍然十分看好 Seldon Core。首先,Seldon Core 非常注重侵入性,对于任何改动,都努力保证对用户代码的侵入性足够低。其次 Seldon Core 的社区足够活跃,每次在 Issue 下留言,都会很快地得到回复。在考虑开源采用时,这是一个非常吸引人的加分项。Seldon Core 在国内似乎没有得到什么关注的目光,这一篇文章也算是免费安利了 XD
License
- This article is licensed under CC BY-NC-SA 3.0.
- Please contact me for commercial use.