
随着分布式深度学习在工业界的普及,MPI(比我的年纪还要大两岁)又迎来了新的活力。作为一个从没有在 HPC 领域有过积累的小学生,学习了许多论文与博客,还是没有理清 MPI,OpenMPI,AllReduce,ReduceScatter,RingAllReduce 等等概念之间的关系。在前段时间为了能够更好地阅读 Horovod 和 BytePS 的代码,Horovod 本身的实现并不十分复杂,但是它的部分工作其实是借助 MPI 来实现的。因此针对性地学习了一下 MPI 的相关知识,这里抛砖引玉地介绍一下 MPI 与深度学习的关系,也留作最近业余时间学习过程的记录。近来与朋友交流,有感于之前文章都过于阳春白雪,对于不熟悉这一领域的读者来说不太友好。因此这一篇文章可能会有针对性地铺垫一些背景知识,因此全文可能较长,对熟悉 MPI 的朋友来说可以跳过前面。
MPI 是什么?这里引用一段 MPI 教程介绍 中的内容:
在 90 年代之前,程序员可没我们这么幸运。对于不同的计算架构写并发程序是一件困难而且冗长的事情。当时,很多软件库可以帮助写并发程序,但是没有一个大家都接受的标准来做这个事情。
在当时,大多数的并发程序只出现在科学和研究的领域。最广为接受的模型就是消息传递模型。什么是消息传递模型?它其实只是指程序通过在进程间传递消息(消息可以理解成带有一些信息和数据的一个数据结构)来完成某些任务。在实践中,并发程序用这个模型去实现特别容易。举例来说,主进程(master process)可以通过对从进程(slave process)发送一个描述工作的消息来把这个工作分配给它。另一个例子就是一个并发的排序程序可以在当前进程中对当前进程可见的(我们称作本地的,locally)数据进行排序,然后把排好序的数据发送的邻居进程上面来进行合并的操作。几乎所有的并行程序可以使用消息传递模型来描述。
由于当时很多软件库都用到了这个消息传递模型,但是在定义上有些微小的差异,这些库的作者以及一些其他人为了解决这个问题就在 Supercomputing 1992 大会上定义了一个消息传递接口的标准,也就是 MPI。这个标准接口使得程序员写的并发程序可以在所有主流的并发框架中运行。并且允许他们可以使用当时已经在使用的一些流行库的特性和模型。
到 1994 年的时候,一个完整的接口标准定义好了(MPI-1)。我们要记住 MPI 只是一个接口的定义而已。然后需要程序员去根据不同的架构去实现这个接口。很幸运的是,仅仅一年之后,一个完整的 MPI 实现就已经出现了。在第一个实现之后,MPI 就被大量地使用在消息传递应用程序中,并且依然是写这类程序的标准(de-facto)。
这里十分推荐先阅读完 MPI 教程 的全部内容,它是我在互联网上能找到的所有关于 MPI 的公开材料中最为深入浅出的一个教程。
简单地来理解 MPI,它是一个定义了多个原语的消息传递接口,这一接口主要被用于多进程间的通信。它的竞品包括 RPC,Distributed Shared Memory 等。关于它们的比较可以参考论文 Message Passing, Remote Procedure Calls and Distributed Shared Memory as Communication Paradigms for Distributed Systems。
MPI 的详细文档可以参考 MPI Forum,这里有 MPI 各个版本的文档(目前发布到了 3.1)。在当代的 MPI 中,接口已经有相当多。不过对我们而言最重要的只有三个部分,也对应着 MPI 文档 中的第三和第五章节:端到端通信,数据类型,和集合通信(Collective Communication)。
端到端通信部分主要实现了从一个进程到另一个进程的通信,核心功能由两个原语提供:
int MPI_Send(const void *buf, int count, MPI_Datatype datatype, int dest,
int tag, MPI_Comm comm)
int MPI_Recv(void *buf, int count, MPI_Datatype datatype,
int source, int tag, MPI_Comm comm, MPI_Status *status)
具体内容请参考 MPI 教程:MPI Send and Receive。
集合通讯是建立在端到端通信的基础上,在一组进程内的通讯原语。其中主要包括:
// Broadcasts a message from the process with rank root to all other processes of the group.
int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype,
int root, MPI_Comm comm)
// Gathers values from a group of processes.
int MPI_Gather(const void *sendbuf, int sendcount, MPI_Datatype sendtype,
void *recvbuf, int recvcount, MPI_Datatype recvtype, int root,
MPI_Comm comm)
// Sends data from one task to all tasks in a group.
int MPI_Scatter(const void *sendbuf, int sendcount, MPI_Datatype sendtype,
void *recvbuf, int recvcount, MPI_Datatype recvtype, int root,
MPI_Comm comm)
...
更多请参考 MPI 教程:广播以及集体(collective)通信,MPI 教程:MPI Scatter, Gather, and Allgather 和 MPI 文档。
MPI 提出了这一系列为了解决进程间消息传递问题而存在的接口,但它们需要一个实现。OpenMPI 是 MPI 的常用实现之一。因此我们可以理解,MPI 是定义,是接口,而 OpenMPI 是这一接口的对应实现。这里还有一个容易混淆的概念,就是 OpenMP。OpenMP(Open Multi-Processing)与 OpenMPI,MPI 并无任何关系。它是一个针对共享内存并行编程的 API。这里特意提出,避免混淆。
而既然 OpenMPI 是 MPI 的一种实现,那针对不同的原语,采用什么算法和数据结构来实现,是实现者的自由。我们应该可以轻易地想到,针对不同的情况(主要是消息的大小等),采用不同的算法会提高整体的性能。OpenMPI 也是这样做的。
回到 AllReduce,它是 MPI 定义的一个集合通信的原语,它的语义是:
Combines values from all processes and distributes the result back to all processes.
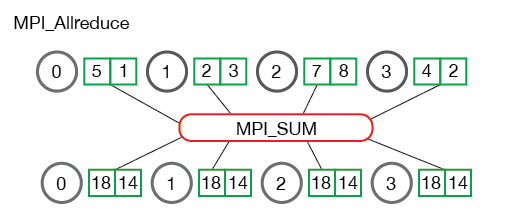
在语义上(注意,仅限于语义的角度,在实现角度并不一定如此),MPI_AllReduce 等于 MPI_Reduce 加 MPI_Bcast。MPI_Reduce 会把结果聚集在 Root 进程,而再利用 MPI_Bcast 把 Root 进程的结果分发给所有进程,就实现了跟 MPI_AllReduce 等价的功能。
而从实现的角度,MPI_AllReduce 这一接口有非常多不同的算法实现,不同的算法在不同情景下具有不同的优劣势。在介绍算法之前,先来介绍一下 MPI_AllReduce 跟深度学习有什么关系。
要理解它们之间的关系,首先要介绍一下模型训练。在一次模型训练中,首先我们会利用数据对模型进行前向的计算。所谓的前向计算,就是将模型上一层的输出作为下一层的输入,并计算下一层的输出,从输入层一直算到输出层为止。根据目标函数,我们将反向计算模型中每个参数的导数,并且结合学习率来更新模型的参数。在分布式训练的场景中,这一问题就会更为复杂一些。比如我们利用 4 个 Worker,利用不同的数据同步地训练相同结构的模型(数据并行的同步训练),在每个 Worker 计算好梯度后,就涉及到一个梯度同步的问题。每个 Worker 都有根据自己的数据计算的梯度,如何能够让自己得到的梯度也能作用于其他的 Worker 呢?有一种方式,是引入一个中心化的组件,参数服务器。所有的参数都存储在参数服务器中,而 Worker 是万年打工仔。Worker 们只负责辛辛苦苦地计算梯度,并且把计算好的梯度发送给参数服务器。参数服务器收到梯度后,执行一定的计算(梯度平均等)后,更新其维护的参数,再把更新好的新参数返回给所有的 Worker。Worker 打工仔们会再进行下一轮的前后向计算。
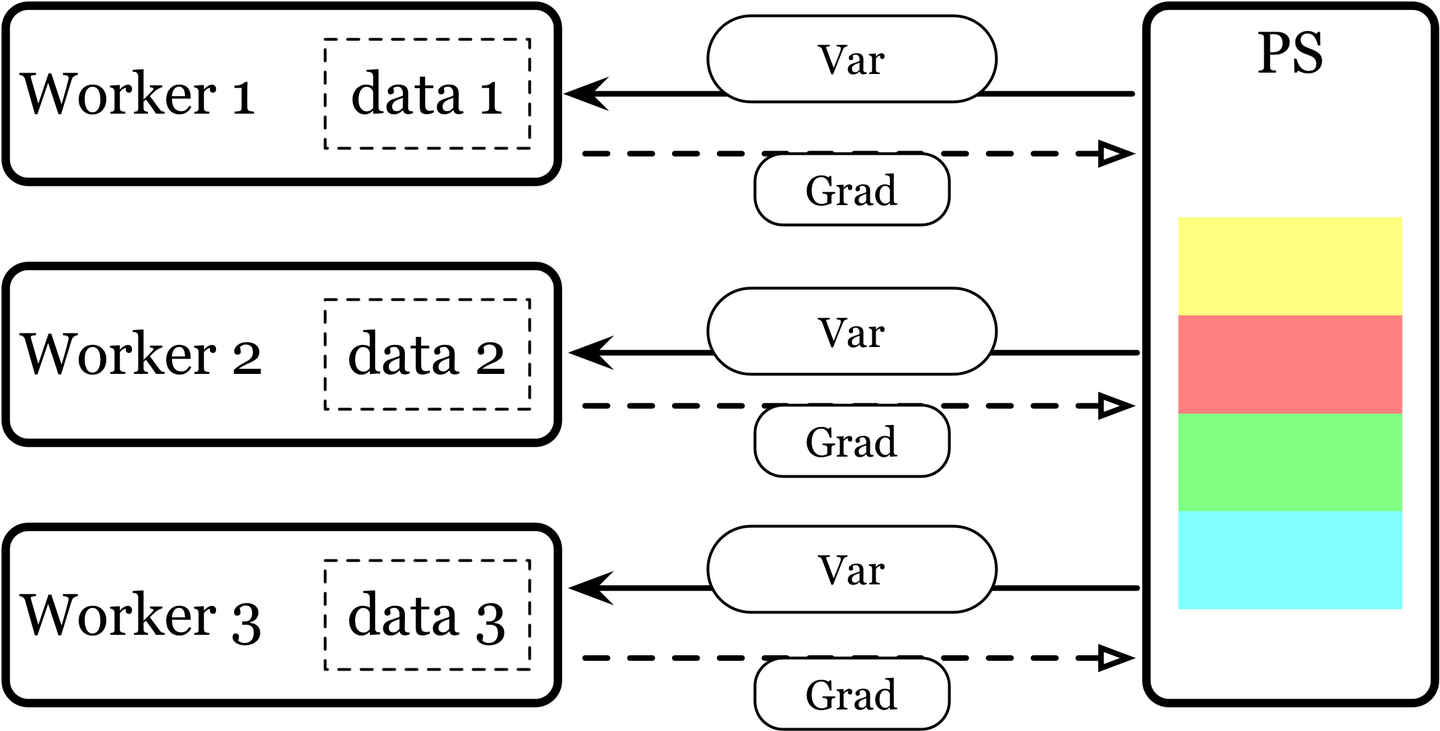
除了这样的方式之外,我们发现,MPI_AllReduce 语义也可以很好地满足这一需要。
我们可以把每个 Worker 看作是 MPI 概念中的一个进程,4 个 Worker 组成了一个 4 个进程组成的组。我们在这四个进程中对梯度进行一次 MPI_AllReduce。根据 MPI_AllReduce 的语义,所有参与计算的进程都有结果,所以梯度就完成了分发。只要在初始化的时候,我们可以保证每个 Worker 的参数是一致的,那在后续的迭代计算中,参数会一直保持一致,因为梯度信息是一致的。
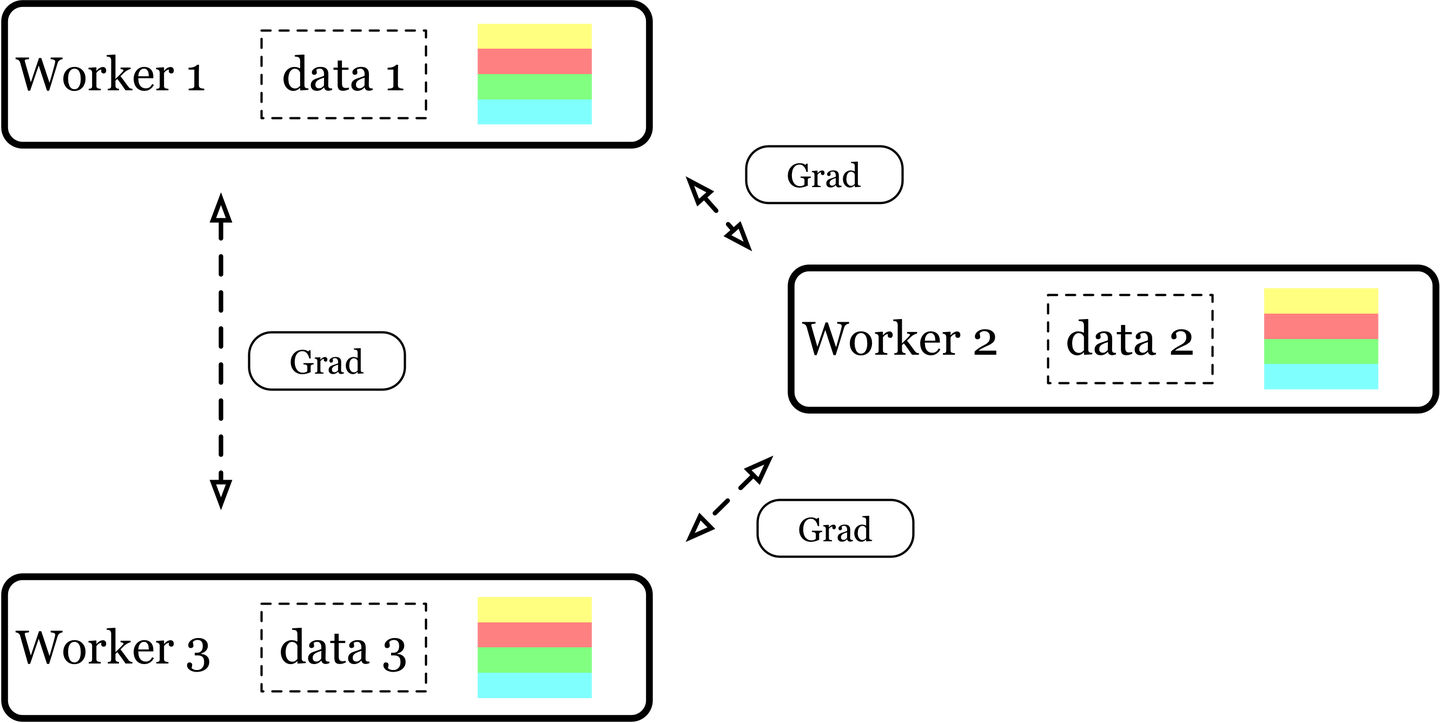
所以,MPI_AllReduce 的语义可以很好地解决深度学习中梯度同步的问题。但是,到底能不能使用它,还是要看下层的实现对这一场景是否足够友好。
在 OpenMPI 的实现中,MPI_AllReduce 主要有 7 种算法,具体可以参考 ompi/mca/coll/tuned/coll_tuned_allreduce_decision.c
/* valid values for coll_tuned_allreduce_forced_algorithm */
static mca_base_var_enum_value_t allreduce_algorithms[] = {
{0, "ignore"},
{1, "basic_linear"},
{2, "nonoverlapping"},
{3, "recursive_doubling"},
{4, "ring"},
{5, "segmented_ring"},
{6, "rabenseifner"},
{0, NULL}
};
我们可以静态地指定算法,也可以让 OpenMPI 来决定。当然,这不是这篇文章的重点。在深度学习这一场景下,被最为广泛应用的是 RingAllReduce 这一实现。在 OpenMPI 中,这一实现在 ompi/mca/coll/base/coll_base_allreduce.c。它的注释非常简洁明了地介绍了实现原理,建议阅读。简单来说,它利用了 MPI 的端到端通信的原语,实现了 RingAllReduce 的功能。将 RingAllReduce 分为了两个阶段。第一个阶段等价于 MPI_ReduceScatter 的语义,是将结果计算到不同的进程。第二个阶段等价于 MPI_AllGather 语义,将计算结果聚合到所有进程。
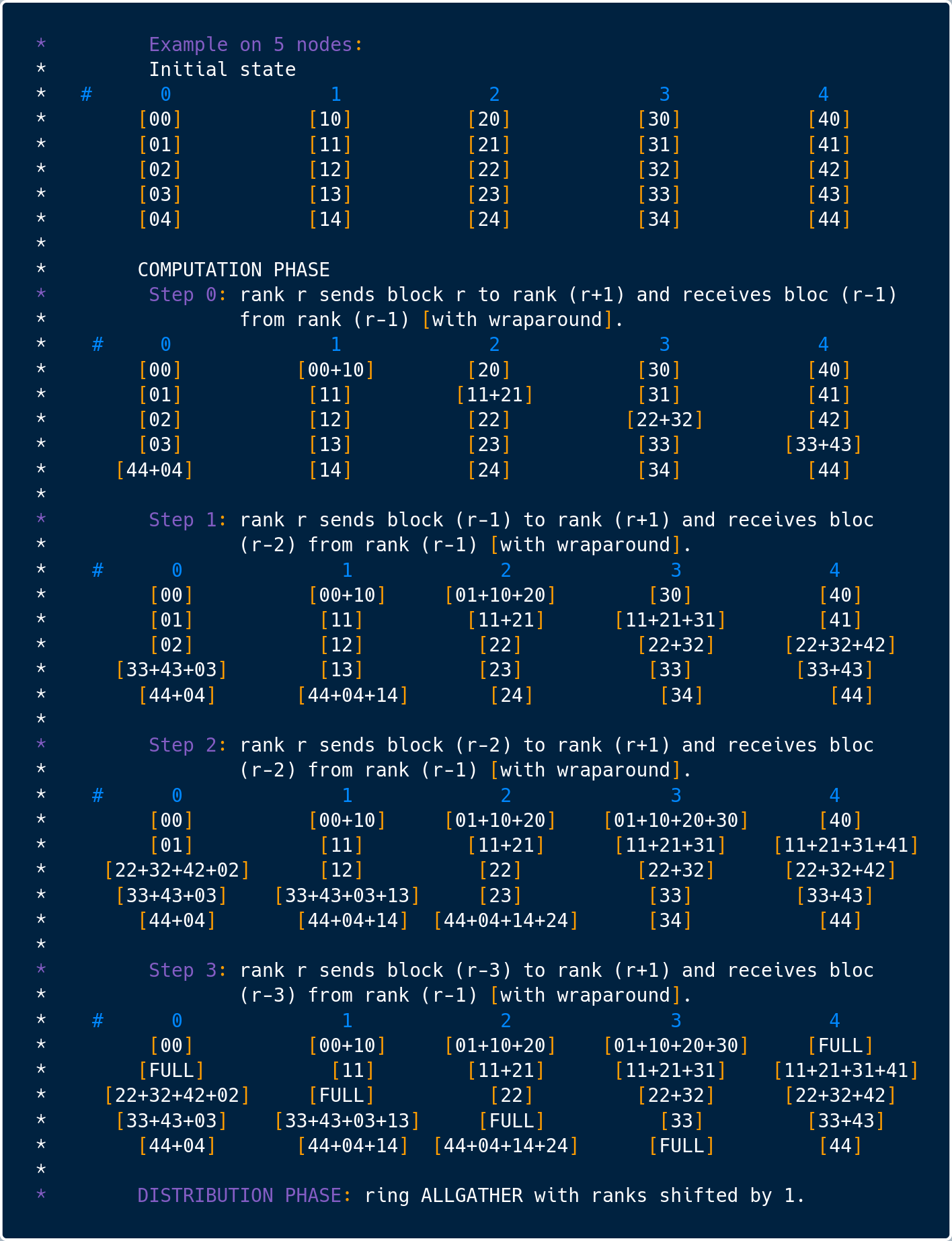
MPI_ReduceScatter 这一接口,本身也对应着非常多的实现。如果先做一次 MPI_Reduce 再做一次 MPI_Scatter(对应 ompi_coll_base_reduce_scatter_intra_nonoverlapping),性能一定无法接受。所以这里的实现使用的是 ompi_coll_base_reduce_scatter_intra_ring。通过 N-1 步,我们可以实现 MPI_ReduceScatter 的语义。其中每步中每个进程的上下行通信量都是 M/N。其中个 M 是数组的长度,N 是进程的数量。数组会被分为 N 等分,所以每次通信量是 M/N。
第二个阶段,就是 MPI_AllGather 了。MPI_AllGather 本身也有非常多的算法实现。RingAllReduce 使用的是 ompi_coll_base_allgather_intra_ring。这一实现一共需要 N-1 步。在第 i 步的时候,Rank r 进程会收到来自 r-1 进程的信息,这一信息中包括了 r-i-1 进程的数据。同时,r 进程会给 r+1 进程发送包含 r-i 进程的数据。所以每步中每个进程的上下行通信量同样都是 M/N。
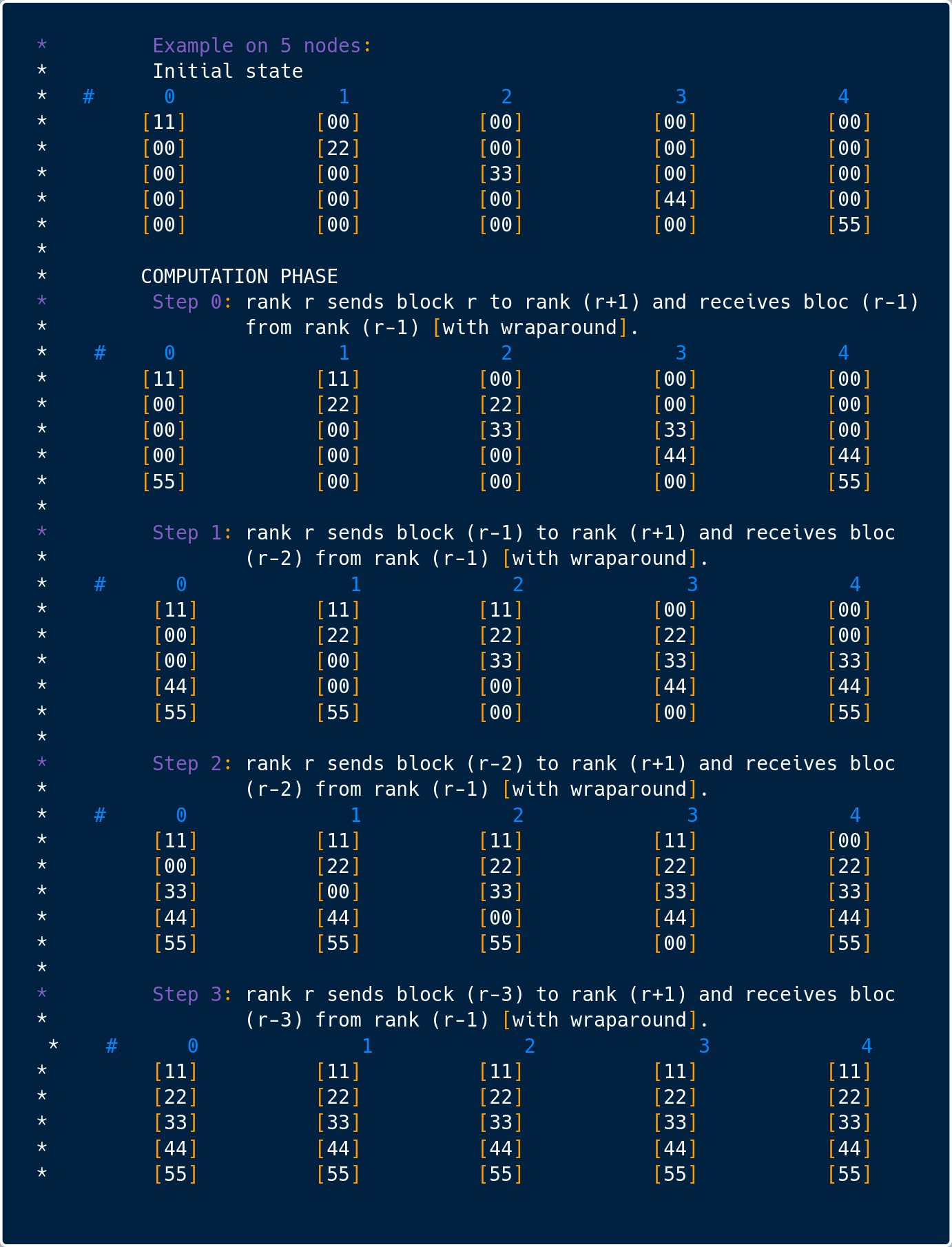
所以整体来看,单步中每个进程的上下行通信量为 M/N,而在整个过程中,每个进程的上下行通信量都是 2(N-1)*M/N。所以我们认为 RingAllReduce 对带宽特别友好,能很好地解决参数服务器架构中的带宽瓶颈问题。其实 MPI_AllGather 除了 Ring 之外还有很多更高效的实现,但由于 MPI_RingAllReduce 中对带宽的要求至少是 M/N,因此 ompi_coll_base_allgather_intra_ring 的实现已经完全够用,在任意时刻都占满 M/N 的上下行。
将 RingAllReduce 引入深度学习,是百度的工作,这一工作开源在 baidu-research/tensorflow-allreduce。百度利用了 MPI 端到端通信的原语,重新实现了 ompi_coll_base_allgather_intra_ring 和 ompi_coll_base_reduce_scatter_intra_ring。至于不直接使用 MPI_AllReduce 的原语,猜测应该是为了兼容更多的 MPI 实现,同时避免动态选择算法导致没有启用 RingAllReduce 的可能(尽管 OpenMPI 可以静态选择算法,但可能其他实现不支持)。
百度的这一实现非常易懂,总共只有 3000 行不到的代码,其中相当部分是测试。百度提供了一个自己的 Optimizer,重载了 compute_gradients 的实现。
class DistributedOptimizer(tf.train.Optimizer):
"""
An optimizer that wraps another tf.Optimizer, using an MPI allreduce to
average gradient values before applying gradients to model weights.
"""
def __init__(self, optimizer, name=None, use_locking=False):
"""
Construct a new DistributedOptimizer, which uses another optimizer
under the hood for computing single-process gradient values and
applying gradient updates after the gradient values have been averaged
across all the MPI ranks.
Args:
optimizer:
Optimizer to use for computing gradients and applying updates.
name:
Optional name prefix for the operations created when applying
gradients. Defaults to "Distributed" followed by the provided
optimizer type.
use_locking:
Whether to use locking when updating variables.
See Optimizer.__init__ for more info.
"""
if name is None:
name = "Distributed{}".format(type(optimizer).__name__)
self._optimizer = optimizer
super(DistributedOptimizer, self).__init__(
name=name, use_locking=use_locking)
def compute_gradients(self, *args, **kwargs):
"""
Compute gradients of all trainable variables.
See Optimizer.compute_gradients() for more info.
In DistributedOptimizer, compute_gradients() is overriden to also
allreduce the gradients before returning them.
"""
gradients = (super(DistributedOptimizer, self)
.compute_gradients(*args, **kwargs))
return [(allreduce(gradient), var) for (gradient, var) in gradients]
...
class Session(tf.Session):
"""
A class for running TensorFlow operations, with copies of the same graph
running distributed across different MPI nodes.
The primary difference between `tf.Session` and `tf.contrib.mpi.Session` is
that the MPI `Session` ensures that the `Session` options are correct for
use with `tf.contrib.mpi`, and initializes MPI immediately upon the start
of the session.
"""
def __init__(self, target='', graph=None, config=None):
"""
Creates a new TensorFlow MPI session.
Unlike a normal `tf.Session`, an MPI Session may only use a single GPU,
which must be specified in advance before the session is initialized.
In addition, it only uses a single graph evaluation thread, and
initializes MPI immediately upon starting.
If no `graph` argument is specified when constructing the session,
the default graph will be launched in the session. If you are
using more than one graph (created with `tf.Graph()` in the same
process, you will have to use different sessions for each graph,
but each graph can be used in multiple sessions. In this case, it
is often clearer to pass the graph to be launched explicitly to
the session constructor.
Args:
target: (Optional.) The execution engine to connect to.
graph: (Optional.) The `Graph` to be launched (described above).
config: (Optional.) A `ConfigProto` protocol buffer with configuration
options for the session.
"""
super(Session, self).__init__(target, graph, config=config)
# Initialize MPI on the relevant device.
# TODO: Move this to library load and eliminate mpi.Session()
self.run(init())
在初始化 optimizer,和使用 session 的时候,语句如下:
optimizer = mpi.DistributedOptimizer(tf.train.AdamOptimizer())
with mpi.Session() as session:
在 optimizer 调用 compute_gradients 的时候,首先会利用 TF 自己的 optimizer 计算出本地梯度,然后利用 AllReduce 来得到各个进程平均后的梯度。而在 Session 初始化的时候会预先执行 MPI_Init 进行 MPI 环境的初始化。
在底层,AllReduce 被注册为 Op,在 ComputeAsync 中,计算请求被入队到一个队列中。这一队列会被一个统一的后台线程处理。之所以引入这样一个后台线程,在注释中有详细的介绍。
在百度的实现中,不同 Rank 的角色是不一样的,Rank 0 会充当 coordinator 的角色。它会协调来自其他 Rank 的 MPI 请求,起到一个调度协调的作用。这是一个工程上的考量,具体可以参考注释。顺便一提,百度的这个工作注释非常详尽,真乃学术界的典范。这一设计也被后来的 Horovod 采用。
Horovod 相比于百度的工作,并无学术上的贡献。但是 Horovod 扎实的工程实现,使得它受到了更多的关注。它最大的优势在于对 RingAllReduce 进行了更高层次的抽象,使其支持多种不同的框架。同时引入了 Nvidia NCCL,对 GPU 更加友好。
与百度的实现类似,Horovod 也需要先进行初始化。只不过百度把这个过程放在了 Session 构建的时候,而 Horovod 提供了显式初始化的函数。在初始化的时候,Horovod 会调用 MPI_Comm_dup 获取一个 Communicator。之所以不直接使用默认的 MPI_COMM_WORLD,参考这里的文档:
While MPI_Comm_split is the most common communicator creation function, there are many others. MPI_Comm_dup is the most basic and creates a duplicate of a communicator. It may seem odd that there would exist a function that only creates a copy, but this is very useful for applications which use libraries to perform specialized functions, such as mathematical libraries. In these kinds of applications, it’s important that user codes and library codes do not interfere with each other. To avoid this, the first thing every application should do is to create a duplicate of MPI_COMM_WORLD, which will avoid the problem of other libraries also using MPI_COMM_WORLD. The libraries themselves should also make duplicates of MPI_COMM_WORLD to avoid the same problem.
除此之外,在初始化的时候,Horovod 还会创建一个后台线程。这里的后台线程的作用与百度的实现类似。
void horovod_init_comm(MPI_Comm comm) {
MPI_Comm_dup(comm, &mpi_context.mpi_comm);
InitializeHorovodOnce(nullptr, 0);
}
// Start Horovod background thread. Ensure that this is
// only done once no matter how many times this function is called.
void InitializeHorovodOnce(const int* ranks, int nranks) {
// Ensure background thread is only started once.
if (!horovod_global.initialize_flag.test_and_set()) {
horovod_global.control_operation = ParseControllerOpsFromEnv();
horovod_global.cpu_operation = ParseCPUOpsFromEnv();
#if HAVE_MPI
// Enable mpi is it's used either in cpu data transfer or controller
if (horovod_global.cpu_operation == LibType::MPI ||
horovod_global.control_operation == LibType::MPI) {
mpi_context.Enable();
}
if (horovod_global.control_operation == LibType::MPI){
horovod_global.controller.reset(new MPIController(
horovod_global.response_cache,
horovod_global.tensor_queue, horovod_global.timeline,
horovod_global.parameter_manager, mpi_context));
horovod_global.controller->SetRanks(ranks, nranks);
}
#endif
// Reset initialization flag
horovod_global.initialization_done = false;
horovod_global.background_thread = std::thread(
BackgroundThreadLoop, std::ref(horovod_global));
}
// Wait to ensure that the background thread has finished initializing MPI.
while (!horovod_global.initialization_done) {
std::this_thread::sleep_for(std::chrono::milliseconds(1));
}
LOG(DEBUG) << "Background thread init done";
}
在这个后台线程的初始化过程中,它会利用进程内共享的全局状态在自己的内存里创建一些对象,以及一些逻辑判断。比如要不要进行 Hierarchical AllReduce,要不要 AutoTune(后面会详细介绍)等。这里是初始化阶段的日志。
$ horovodrun -np 2 python hvd.py
[1,1]<stdout>:[2020-07-09 10:27:48.952760: D horovod/common/utils/env_parser.cc:106] Using MPI to perform controller operations.
[1,1]<stdout>:[2020-07-09 10:27:48.952813: D horovod/common/utils/env_parser.cc:72] Using MPI to perform CPU operations.
[1,1]<stdout>:[2020-07-09 10:27:48.952922: D horovod/common/mpi/mpi_context.h:46] MPI context enabled.
[1,1]<stdout>:[2020-07-09 10:27:48.952968: D horovod/common/mpi/mpi_controller.h:32] MPI Controller Initialized.
[1,0]<stdout>:[2020-07-09 10:27:49. 27002: D horovod/common/utils/env_parser.cc:106] Using MPI to perform controller operations.
[1,0]<stdout>:[2020-07-09 10:27:49. 27064: D horovod/common/utils/env_parser.cc:72] Using MPI to perform CPU operations.
[1,0]<stdout>:[2020-07-09 10:27:49. 27094: D horovod/common/mpi/mpi_context.h:46] MPI context enabled.
[1,0]<stdout>:[2020-07-09 10:27:49. 27118: D horovod/common/mpi/mpi_controller.h:32] MPI Controller Initialized.
[1,0]<stdout>:[2020-07-09 10:27:49. 88254: D horovod/common/mpi/mpi_context.cc:142] Using MPI_COMM_WORLD as a communicator.
[1,1]<stdout>:[2020-07-09 10:27:49. 88459: D horovod/common/mpi/mpi_context.cc:142] Using MPI_COMM_WORLD as a communicator.
[1,0]<stdout>:[2020-07-09 10:27:49. 88947: D horovod/common/mpi/mpi_controller.cc:39] Started Horovod with 2 processes
[1,0]<stdout>:[2020-07-09 10:27:49. 89143: D horovod/common/mpi/mpi_controller.cc:80] MPI controller initialized.
[1,0]<stdout>:[2020-07-09 10:27:49. 89195: I horovod/common/operations.cc:506] [0]: Horovod Initialized
[1,1]<stdout>:[2020-07-09 10:27:49. 89147: D horovod/common/mpi/mpi_controller.cc:80] MPI controller initialized.
[1,1]<stdout>:[2020-07-09 10:27:49. 89489: I horovod/common/operations.cc:506] [1]: Horovod Initialized
[1,0]<stdout>:[2020-07-09 10:27:49. 89945: D horovod/common/operations.cc:649] Background thread init done
[1,1]<stdout>:[2020-07-09 10:27:49. 91335: D horovod/common/operations.cc:649] Background thread init done
在初始化的过程中,有一些比较重要的对象会被构造出来。不过这里暂且按下不表,后续再介绍。在初始化好之后,我们利用下面的代码进行模型的训练:
@tf.function
def training_step(images, labels, first_batch):
with tf.GradientTape() as tape:
probs = mnist_model(images, training=True)
loss_value = loss(labels, probs)
# Horovod: add Horovod Distributed GradientTape.
tape = hvd.DistributedGradientTape(tape)
grads = tape.gradient(loss_value, mnist_model.trainable_variables)
opt.apply_gradients(zip(grads, mnist_model.trainable_variables))
# Horovod: broadcast initial variable states from rank 0 to all other processes.
# This is necessary to ensure consistent initialization of all workers when
# training is started with random weights or restored from a checkpoint.
#
# Note: broadcast should be done after the first gradient step to ensure optimizer
# initialization.
if first_batch:
hvd.broadcast_variables(mnist_model.variables, root_rank=0)
hvd.broadcast_variables(opt.variables(), root_rank=0)
return loss_value
首先会利用 Bcast 来同步 Rank 0 进程的初始化参数给所有的进程,这里是为了保证初始参数一致。
def broadcast_variables(variables, root_rank):
"""Broadcasts variables from root rank to all other processes.
Arguments:
variables: variables for broadcast
root_rank: rank of the process from which global variables will be broadcasted
to all other processes.
"""
broadcast_group = _make_broadcast_group_fn()
return broadcast_group(variables, root_rank)
由于我们是利用 TensorFlow 2 来进行训练。所以梯度更新部分的实现不是基于计算图的实现,而是使用 hvd.DistributedGradientTape。它的实现如下所示,当调用 gradient 的时候,首先会调用 tf.GradientTape 的同名函数,同时进行 AllReduce。这里的逻辑与百度实现中的 Optimizer 是否似曾相识:
class _DistributedGradientTape(tf.GradientTape):
def gradient(self, target, sources, output_gradients=None):
gradients = super(self.__class__, self).gradient(target, sources, output_gradients)
return self._allreduce_grads(gradients)
@_cache
def _make_allreduce_grads_fn(name, device_dense, device_sparse,
compression, sparse_as_dense, op):
def allreduce_grads(grads):
with tf.name_scope(name + "_Allreduce"):
if sparse_as_dense:
grads = [tf.convert_to_tensor(grad)
if grad is not None and isinstance(grad, tf.IndexedSlices)
else grad for grad in grads]
return [_allreduce_cond(grad,
device_dense=device_dense,
device_sparse=device_sparse,
compression=compression,
op=op)
if grad is not None else grad
for grad in grads]
def _allreduce_cond(tensor, *args, **kwargs):
def allreduce_fn():
return allreduce(tensor, *args, **kwargs)
def id_fn():
return tensor
return tf.cond(size_op() > 1, allreduce_fn, id_fn)
def _allreduce(tensor, name=None, op=Sum):
"""An op which reduces an input tensor over all the Horovod processes. The
default reduction is a sum.
The reduction operation is keyed by the name of the op. The tensor type and
shape must be the same on all Horovod processes for a given name. The reduction
will not start until all processes are ready to send and receive the tensor.
Returns:
A tensor of the same shape and type as `tensor`, summed across all
processes.
"""
if name is None and not _executing_eagerly():
name = 'HorovodAllreduce_%s' % _normalize_name(tensor.name)
return MPI_LIB.horovod_allreduce(tensor, name=name, reduce_op=op)
allreduce_grads 会修改 name scope,添加后缀 _Allreduce。在后续的调用中,进行了一些复杂但不核心的逻辑,如压缩等。最后调用 _allreduce。在这一函数中,会直接调用 C++ 实现的 Kernel。
void ComputeAsync(OpKernelContext* context, DoneCallback done) override {
OP_REQUIRES_OK_ASYNC(context, ConvertStatus(common::CheckInitialized()),
done);
...
auto enqueue_result = EnqueueTensorAllreduce(
hvd_context, hvd_tensor, hvd_output, ready_event, node_name, device,
[context, done](const common::Status& status) {
context->SetStatus(ConvertStatus(status));
done();
}, reduce_op);
...
}
在 ComputeAsync 里,会把这一 AllReduce 的请求入队。可以看到,在 TensorFlow 支持的实现上,Horovod 与百度大同小异。都是自定义了 AllReduce Op,在 Op 中把请求入队。
所以在 Horovod 的日志中,我们可以看到这样的日志(当然要设置 HOROVOD_LOG_LEVEL=trace 环境变量)。DistributedGradientTape 的 name scope 被改写成了 DistributedGradientTape_Allreduce,名字被加上了 HorovodAllreduce_ 的前缀。
[1,1]<stdout>:[2020-07-09 10:27:56.839122: T horovod/common/operations.cc:849] [1]: Enqueued DistributedGradientTape_Allreduce/HorovodAllreduce_gradient_tape_sequential_dense_1_BiasAdd_BiasAddGrad_0
[1,1]<stdout>:[2020-07-09 10:27:56.839176: T horovod/common/operations.cc:849] [1]: Enqueued DistributedGradientTape_Allreduce/HorovodAllreduce_gradient_tape_sequential_dense_1_MatMul_1_0
[1,1]<stdout>:[2020-07-09 10:27:56.839280: T horovod/common/operations.cc:849] [1]: Enqueued DistributedGradientTape_Allreduce/HorovodAllreduce_gradient_tape_sequential_dense_BiasAdd_BiasAddGrad_0
EnqueueTensorAllreduce 是进入了一个进程内共享的全局对象维护的一个队列中。之前提到的后台进程,会一直在执行一个循环 RunLoopOnce。在其中,后台线程会利用 MPIController 来处理入队的请求。MPIController 可以理解为是协调不同的 Rank 进程,处理请求的对象。这个抽象是百度所不具备的,主要是为了支持 Facebook gloo 等其他的集合计算库。因此 Horovod 也有 GlooController 等等实现。
在后台线程里,最重要的一个函数调用是 ComputeResponseList。Horovod 也遵循着 Coordinator 的设计,与百度类似。无论是百度还是 Horovod 中的 Coordinator 都类似是 Actor 模式,主要起来协调多个进程工作的作用。在真正执行计算的时候,Horovod 同样引入了一个新的抽象 op_manager。从某种程度来说,我们可以把 controller 看做是对通信和协调管理能力的抽象,而 op_manager 是对实际计算的抽象。
class OperationManager {
public:
OperationManager(ParameterManager* param_manager,
std::vector<std::shared_ptr<AllreduceOp>> allreduce_ops,
std::vector<std::shared_ptr<AllgatherOp>> allgather_ops,
std::vector<std::shared_ptr<BroadcastOp>> broadcast_ops,
std::shared_ptr<JoinOp> join_op,
std::vector<std::shared_ptr<AllreduceOp>> adasum_ops,
std::shared_ptr<ErrorOp> error_op);
virtual ~OperationManager() = default;
Status ExecuteAllreduce(std::vector<TensorTableEntry>& entries, const Response& response) const;
...
}
总结来说,Horovod 的设计与实现都与百度的工作并无二致,只是进行了更多的抽象,支持更多的通信库,更多的训练框架。这些工作虽然都是 dirty work,但也是它受欢迎的最大原因。Horovod 可以说是 RingAllReduce 数据并行训练框架方面的 State-of-art 了,不过最近还有一个工作,同样受到了很多的关注,那就是字节跳动的 BytePS,甚至发了 SOSP(羡慕到变形!)。论文在此处可预览。不过论文和实现有挺大不同的,这里我们以开源实现为准,介绍一下 byteps。
BytePS 的代码目录结构跟 Horovod 很像,在 TensorFlow 的支持上,做法与百度和 Horovod 并无二致。对 Optimizer 进行了包装,实现了自定义的 Op。
def push_pull_grads(grads):
with tf.name_scope(self._name + "_Push_Pull") as scope:
if self._sparse_as_dense:
grads = [tf.convert_to_tensor(grad)
if grad is not None and isinstance(grad, tf.IndexedSlices)
else grad for grad in grads]
return [push_pull(grad, scope,
device_dense=self._device_dense,
device_sparse=self._device_sparse,
compression=self._compression,
enable_async=self._enable_async)
if grad is not None else grad
for grad in grads]
if _executing_eagerly():
self._push_pull_grads = tf.contrib.eager.defun(push_pull_grads)
else:
self._push_pull_grads = push_pull_grads
def compute_gradients(self, *args, **kwargs):
"""Compute gradients of all trainable variables.
See Optimizer.compute_gradients() for more info.
In DistributedOptimizer, compute_gradients() is overriden to also
push_pull the gradients before returning them.
"""
gradients = self._optimizer.compute_gradients(*args, **kwargs)
if size() > 1 and not self._enable_async:
grads, vars = zip(*gradients)
avg_grads = self._push_pull_grads(grads)
return list(zip(avg_grads, vars))
else:
return gradients
在 Horovod 里,C++ 的 Op 会把请求入队到全局的队列中,被后台进程中。而在 BytePS 里,逻辑也类似。
void ComputeAsync(::tensorflow::OpKernelContext* context,
DoneCallback done) override {
...
if (bps_context.initialized) {
StartTask(context, done, tmp_name, bps_input, bps_output, ready_event);
} else {
std::thread t(StartTask, context, done, tmp_name, bps_input, bps_output,
ready_event);
t.detach();
}
}
void StartTask(::tensorflow::OpKernelContext* context,
::tensorflow::AsyncOpKernel::DoneCallback done,
std::string node_name, std::shared_ptr<TFTensor> byteps_input,
std::shared_ptr<TFTensor> byteps_output,
std::shared_ptr<common::ReadyEvent> ready_event) {
...
auto queue_list = common::GetPushQueueList(device);
auto queue_list_pull = common::GetPullQueueList(device);
queue_list->insert(queue_list->end(), queue_list_pull->begin(),
queue_list_pull->end());
// TODO: assign priority based on topological sort
auto enqueue_result =
EnqueueTensor(byteps_context, byteps_input, byteps_output, ready_event,
device, -byteps_context.declared_key, 0,
[context, done](const common::Status& status) {
context->SetStatus(ConvertStatus(status));
done();
},
queue_list);
OP_REQUIRES_OK_ASYNC(context, ConvertStatus(enqueue_result), done);
}
代码注释里写到需要给 Tensor 根据拓扑序设定优先级,这个是在 BytePS 的论文中提到的一个非常重要的优化,看代码这部分的逻辑应该已经实现了,具体可以见这里的讨论。至于这里的注释是什么意思,还需要问一下上游才能确定。
最终请求会在 Partition 后入队。EnqueueTensor 与 Horvod 虽然类似,但是它会划分 Partition,默认是 4096000 字节一个 Task,这个优化在论文中也有提到,不过在开源实现中没有找寻到论文中提到的基于贝叶斯优化的 AutoTune 的痕迹。
跟 Horovod 相比,还有一个比较大的不同。BytePS 为了能够流水线地处理 Push 和 Pull,引入了 QueueType 这个概念。上述代码中的 queue_list 就是将为了处理 Push 和 Pull 的不同事件组成了一个事件队列。后续 BytePS 会按照这一队列依次处理事件,处理完里面的所有事件后,就完成了 PushPullGradients 的过程。
Status EnqueueTensor(BPSContext &context, std::shared_ptr<Tensor> input,
std::shared_ptr<Tensor> output,
std::shared_ptr<ReadyEvent> ready_event, const int device,
const int priority, const int version,
StatusCallback callback,
std::shared_ptr<std::vector<QueueType>> queue_list) {
...
std::vector<std::shared_ptr<TensorTableEntry>> partitions;
PartitionTensor(e, partitions);
...
unsigned int accumulated = 0;
for (size_t i = 0; i < partitions.size(); ++i) {
auto task = partitions[i];
task->key = context.key_list[i]; // assign the key now
BPS_CHECK(task->tensor_name != "");
BPS_LOG(TRACE) << "EnqueueTensor: " << (task->tensor_name)
<< ", key=" << (task->key) << ", offset=" << (task->offset)
<< ", len=" << (task->len) << ", device=" << (task->device)
<< " rank=" << BytePSGlobal::GetLocalRank();
BytePSGlobal::GetScheduledQueue(e->queue_list[0])->addTask(task);
accumulated += task->len;
}
auto tensor = (e->tensor ? e->tensor : e->output);
BPS_CHECK(tensor);
BPS_CHECK_EQ(accumulated, tensor->size())
<< "accumulated partition size not equal to original tensor size";
BPS_LOG(TRACE) << "EnqueueTensor finished: " << name
<< ", rank=" << BytePSGlobal::GetLocalRank();
return Status::OK();
}
BytePS 的 PS 部分是利用 dmlc/ps-lite 实现的,dmlc/ps-lite 也被用于 MXNet,因此 BytePS 的分布式训练中也有三个角色,Server,Worker 和 Scheduler。其中的 Server 并不是传统意义上的 Parameter Server,而是一个具备一定的计算能力和 KV 存储能力的,只使用 CPU 的普通 Server。为了加法做的足够好,Server 这边对加法操作也有一个抽象,那就是 CPUReducer。从这个角度来理解,BytePS 是采用了 Server-Worker 这种通信的模型实现了 AllReduce 的语义,并不是传统意义上的 PS。从这样的设计来讲,确实可以通过 Tensor 的分区分段把流水线跑起来。就像知乎老师木的回答一样。不过我对老师木说的这是把 ReduceScatter 和 AllGather 流水起来还是不太理解。
总体来看,自从百度的 RingAllReduce 以来,后续越来越多的工作是关注在怎么样能够把计算和通信重叠起来,通过类似于流水线的方式隐藏掉一部分的成本。这里我很赞同 BytePS 在文档里的两点观察:
- Cloud, either public or private, is different from HPC. Using ideas from HPC is a shortcut, but not optimal.
- In a (public or private) cloud, PS architecture is theoretically better than allreduce, with minimal additional costs.
AllReduce 来自 HPC,如果在真实的集群环境里不能做到机架感知,会带来一定的影响。BytePS 同样对调度提出了新要求,但这种拿 CPU 和一点点的网络换训练速度的事情,非常值得一试。
参考文献
License
- This article is licensed under CC BY-NC-SA 3.0.
- Please contact me for commercial use.