
Spark 是大数据领域目前的事实标准之一,Google 开源的 spark-on-k8s-operator,使得在 Kubernetes 上也可以便捷地运行 Spark 任务,因此被微软,Salesforce,才云科技(我司)等公司广泛应用。然而在采用的过程中,一个近期出现在测试环境中的问题,出现在了我们的面前。问题的表象与这一 Issue 一样,在创建 Spark Application 时,spark-on-k8s-operator 报错:
I0702 08:24:10.298358 11 controller.go:522] Trying to update SparkApplication spark/test-volume-claim, from: [{ 2019-07-02 07:26:25 +0000 UTC 0001-01-01 00:00:00 +0000 UTC { 0 } {FAILED failed to run spark-submit for SparkApplication spark/test-volume-claim: Exception in thread "main" io.fabric8.kubernetes.client.KubernetesClientException: Operation: [create] for kind: [Pod] with name: [null] in namespace: [spark] failed.
at io.fabric8.kubernetes.client.KubernetesClientException.launderThrowable(KubernetesClientException.java:62)
at io.fabric8.kubernetes.client.KubernetesClientException.launderThrowable(KubernetesClientException.java:71)
at io.fabric8.kubernetes.client.dsl.base.BaseOperation.create(BaseOperation.java:363)
at org.apache.spark.deploy.k8s.submit.Client$$anonfun$run$2.apply(KubernetesClientApplication.scala:141)
at org.apache.spark.deploy.k8s.submit.Client$$anonfun$run$2.apply(KubernetesClientApplication.scala:140)
at org.apache.spark.util.Utils$.tryWithResource(Utils.scala:2543)
at org.apache.spark.deploy.k8s.submit.Client.run(KubernetesClientApplication.scala:140)
at org.apache.spark.deploy.k8s.submit.KubernetesClientApplication$$anonfun$run$5.apply(KubernetesClientApplication.scala:250)
at org.apache.spark.deploy.k8s.submit.KubernetesClientApplication$$anonfun$run$5.apply(KubernetesClientApplication.scala:241)
at org.apache.spark.util.Utils$.tryWithResource(Utils.scala:2543)
at org.apache.spark.deploy.k8s.submit.KubernetesClientApplication.run(KubernetesClientApplication.scala:241)
at org.apache.spark.deploy.k8s.submit.KubernetesClientApplication.start(KubernetesClientApplication.scala:204)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:849)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.net.SocketTimeoutException: timeout
...
... 16 more
Caused by: java.net.SocketException: Socket closed
at java.net.SocketInputStream.read(SocketInputStream.java:204)
...
... 43 more
在原 Issue 中,这一问题通过 -enable-webhook=false 禁用掉 Spark 的 Mutating Webhook 后,可以被避免,但在我们遇到的问题环境中,禁用 Webhook 并不能解决问题。至于为什么在原 Issue 中禁用 Webhook 可以奏效,这里就要介绍一下 spark-on-k8s-operator 的工作流程了。
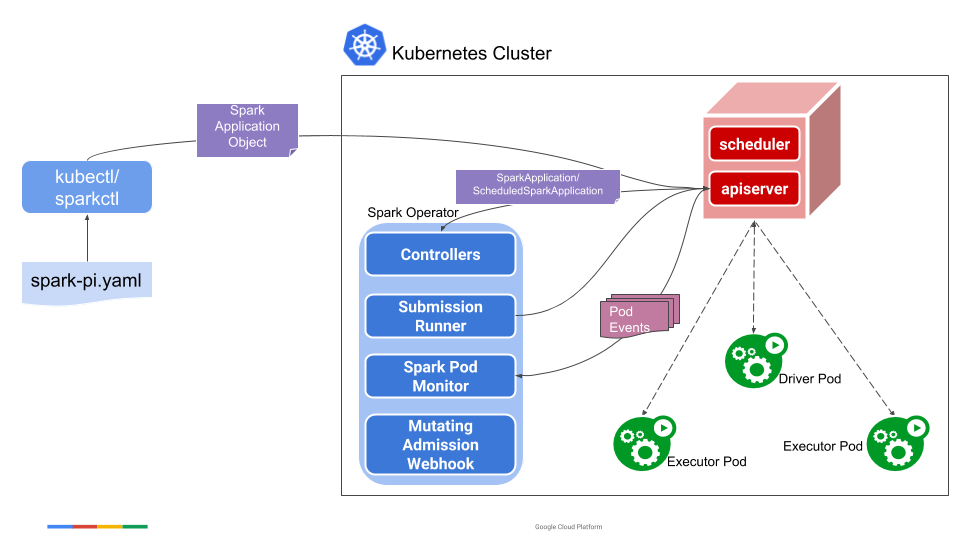
当用户提交了一个 SparkApplication(一个由 spark-on-k8s-operator 定义的 CRD)时,spark-on-k8s-operator 会为这一 SparkApplication 创建一个进程执行 spark-submit 。
func runSparkSubmit(submission *submission) (bool, error) {
sparkHome, present := os.LookupEnv(sparkHomeEnvVar)
if !present {
glog.Error("SPARK_HOME is not specified")
}
var command = filepath.Join(sparkHome, "/bin/spark-submit")
cmd := execCommand(command, submission.args...)
glog.V(2).Infof("spark-submit arguments: %v", cmd.Args)
output, err := cmd.Output()
glog.V(3).Infof("spark-submit output: %s", string(output))
if err != nil {
var errorMsg string
if exitErr, ok := err.(*exec.ExitError); ok {
errorMsg = string(exitErr.Stderr)
}
// The driver pod of the application already exists.
if strings.Contains(errorMsg, podAlreadyExistsErrorCode) {
glog.Warningf("trying to resubmit an already submitted SparkApplication %s/%s", submission.namespace, submission.name)
return false, nil
}
if errorMsg != "" {
return false, fmt.Errorf("failed to run spark-submit for SparkApplication %s/%s: %s", submission.namespace, submission.name, errorMsg)
}
return false, fmt.Errorf("failed to run spark-submit for SparkApplication %s/%s: %v", submission.namespace, submission.name, err)
}
return true, nil
}
spark-submit 其实是一个 bash 脚本,最后真正执行的命令类似如下所示:
/home/gaocegege/.jenv/versions/1.8/bin/java -cp /home/gaocegege/Applications/spark/conf/:/home/gaocegege/Applications/spark/jars/* -Xmx1g org.apache.spark.deploy.SparkSubmit "$@" java -Xmx128m -cp /home/gaocegege/Applications/spark/jars/* org.apache.spark.launcher.Main org.apache.spark.deploy.SparkSubmit "$@"
Operator 创建进程来执行 spark-submit,它会通过 Kubernetes 的 Java Client,利用 SparkApplication CRD 提供的配置,在集群上创建出对应的 Driver Pod 和 Service。随后,Driver 会再利用配置和 Kubernetes 的 Java Client,在集群上创建出对应的 Executor。
而我们遇到的问题,就出现在第一步,在 spark-submit 创建 Driver Pod 时遇到了 Timeout。在 Issue 中作者通过禁用了 Webhook 的方式,避免了因为 Webhook 导致响应时间超时的问题。而在我们遇到的问题中,这一方式并没有奏效。
在初步走读了 spark/resource-managers/kubernetes 的代码后,我们发现了一个可能的原因:在与 Kubernetes APIServer 交互时的 cert 问题可能会导致 timeout。随后我们尝试把宿主机的 crt 拷贝到容器中,然后手动指定 spark.kubernetes.authenticate.submission.caCertFile 参数:
kubectl -n kube-system cp /etc/kubernetes/certs/server.crt clever-spark-operator-operator-v1-0-78bc4b5b6b-klfvm:server.crt
/opt/spark/bin/spark-submit --conf spark.kubernetes.authenticate.submission.caCertFile=/opt/spark/work-dir/server.crt --class org.apache.spark.examples.SparkPi --master k8s://https://10.254.0.1:443 --deploy-mode cluster --conf spark.kubernetes.namespace=smoking-test --conf spark.app.name=sparkapplication-20200110040748-rqb5mlkf --conf spark.kubernetes.driver.pod.name=sparkapplication-20200110040748-rqb5mlkf-driver --conf spark.kubernetes.submission.waitAppCompletion=false --conf spark.kubernetes.namespace=smoking-test --conf spark.eventLog.dir=/clever/events --conf spark.eventLog.enabled=true --conf spark.kubernetes.driver.label.sparkoperator.k8s.io/app-name=sparkapplication-20200110040748-rqb5mlkf --conf spark.kubernetes.driver.label.sparkoperator.k8s.io/launched-by-spark-operator=true --conf spark.kubernetes.driver.label.sparkoperator.k8s.io/submission-id=fbdf4adb-e336-44f7-b817-9937da8c37ca --conf spark.kubernetes.driver.pod.name=sparkapplication-20200110040748-rqb5mlkf-driver --conf spark.kubernetes.driver.container.image=******** --conf spark.driver.cores=200.000000 --conf spark.kubernetes.driver.limit.cores=300 --conf spark.driver.memory=500m --conf spark.driver.memoryOverhead=750m --conf spark.kubernetes.authenticate.driver.serviceAccountName=default --conf spark.kubernetes.driver.label.job-name=sparkapplication-20200110040748-rqb5mlkf --conf spark.kubernetes.driver.annotation.helm.sh/path=sparkapplication-20200110040748-rqb5mlkf --conf spark.kubernetes.driver.annotation.helm.sh/release=sparkapplication-20200110040748-rqb5mlkf --conf spark.kubernetes.driver.annotation.helm.sh/namespace=smoking-test --conf spark.kubernetes.executor.label.sparkoperator.k8s.io/app-name=sparkapplication-20200110040748-rqb5mlkf --conf spark.kubernetes.executor.label.sparkoperator.k8s.io/launched-by-spark-operator=true --conf spark.kubernetes.executor.label.sparkoperator.k8s.io/submission-id=fbdf4adb-e336-44f7-b817-9937da8c37ca --conf spark.executor.instances=1 --conf spark.kubernetes.executor.container.image=******* --conf spark.executor.cores=1 --conf spark.kubernetes.executor.limit.cores=1500m --conf spark.executor.memory=600m --conf spark.executor.memoryOverhead=900m --conf spark.kubernetes.executor.label.job-name=sparkapplication-20200110040748-rqb5mlkf --conf spark.kubernetes.executor.annotation.helm.sh/release=sparkapplication-20200110040748-rqb5mlkf --conf spark.kubernetes.executor.annotation.helm.sh/namespace=smoking-test --conf spark.kubernetes.executor.annotation.helm.sh/path=sparkapplication-20200110040748-rqb5mlkf local:///library/spark-examples_2.11-2.4.0.jar
但问题仍然没有得到解决,报错还是与之前一样。于是我们开始寻找其他的可能。后来,在检查 operator 的资源配额时,我们发现它的内存配额与其他的 operator 一样,被统一配置了较小的内存资源的 Limit 值。而 spark-on-k8s-operator 由于在创建 SparkApplication 后,会创建 JVM 来执行 spark-submit,所以它需要的内存应该会比其他 operator 更多。所以,我们尝试调整了 spark-on-k8s-operator 的资源配额,结果问题果然解决了。
而正当我们松了一口气时,在调整完配额的几天后,我们又遇到了同样的报错,而这一次,无论怎么调整配额,都不能解决这一问题了。在之前,有同事(我司 CTO 邓老师)提过有可能与 JDK 版本有关,我们在容器内的 JDK 版本是 1.8.0_181。再一次遇到这一问题后,我们尝试升级了 SparkApplication 的版本,以及上游 Spark 的版本,和 JDK 的版本(1.8.0_232),但问题仍然还是会出现。所以我们断定,这应该与我们集群环境有关,而不是上游版本的问题。
于是,我们开始在 operator 容器内,利用 serviceaccount,开始手动地访问 APIServer 测试是否能够与其正常交互。结果,确实发现了问题。在通过 APIServer 的 API 去创建 Pod 时,发现请求的响应时间确实非常久,大约需要 30 秒。这可能超出了 spark-submit 使用的 Kubernetes Java Client 的默认等待时间。
CA_CERT=/var/run/secrets/kubernetes.io/serviceaccount/ca.crt
TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)
NAMESPACE=$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace)
curl --cacert $CA_CERT -H "Authorization: Bearer $TOKEN" -w "@curl-format.txt" -o /dev/null -s "https://kubernetes:443/api/v1/namespaces/default/pods/" -H 'Content-Type: application/json' -d @pod.json
time_namelookup: 0.000096
time_connect: 0.001206
time_appconnect: 0.009772
time_pretransfer: 0.010172
time_redirect: 0.000000
time_starttransfer: 0.010246
----------
time_total: 30.022177
通过代码阅读,我们发现 spark-submit 使用的 Kubernetes Java Client 支持通过环境变量 KUBERNETES_REQUEST_TIMEOUT 来设置请求的超时时间。在设置了一个相对较大的值后,终于解决了这一问题。
但是,spark-submit 成功创建了 Driver Pod 后,Driver Pod 也报错,报错与 spark-submit 的报错基本一致,请求超时。随后我们照猫画虎,在为 Driver Pod 也配置了相应的环境变量 KUBERNETES_REQUEST_TIMEOUT 后,终于彻底圆满地解决了这一问题。而后续发现,创建 Pod 的高延迟,来自于环境上某个 Webhook 的原因。虽然不是 spark-on-k8s-operator 自身的,但原 Issue 中关于 Webhook 的回复其实也暗示了问题的根本原因。
在存储与计算分离的大势所趋下,Spark on Kubernetes 一定会得到越来越多的使用和关注。而技术堆栈的复杂程度也随之越来越高。在复杂的系统中,找出引起问题的导火索,并且修复它,真的是件非常有乐趣的事情。做 Manneken Pis 的感觉,还真的是很棒呢(
License
- This article is licensed under CC BY-NC-SA 3.0.
- Please contact me for commercial use.