
前置知识
网络IO与Socket
在Linux系统中,有这样一句话,叫做『万物皆文件』,也就是说,所有东西,都可以抽象成『open –> write/read –> close』模式来操作。所以在Linux中,网络的操作,也会被当做是文件的读写操作那样去对待。每个网络连接都是一个特殊的文件,根据这个文件也可以进行读写操作。因此对网络的操作,也是用IO来描述的。
在网络编程中,有一个绕不开的概念,那就是Socket。Socket是网络分层模型中的应用层与TCP,UDP为代表的的运输层之间的facade,Socket封装了网络底层的操作,把TCP/IP抽象成了几个简单的接口,使得应用层在实现网络中通信时能够更加简便。之前提到的,每个网络连接都是一个特殊的文件,落实到Socket来看,就是说,每一个Socket,都是一个特殊文件。
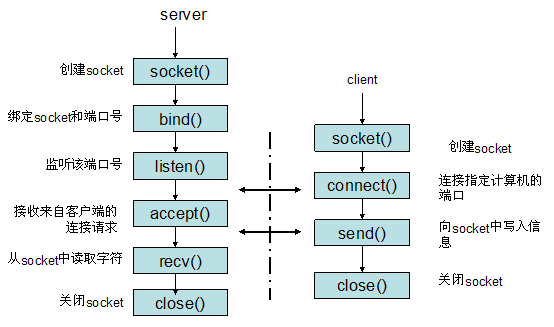
关于Socket的操作,这张图可以比较清楚地了解到所有的步骤。在一次网络通信中,服务端和客户端都会先调用Socket函数,去产生一个Socket文件,这时候,函数的返回值是一个File Descriptor。接下来。服务器端会把得到的文件描述符和具体的端口绑定,然后调用listen函数来监听文件的操作。到这里,服务器的初始化任务就结束了。而在客户端,客户端在创建了Socket文件后,会调用connect来建立与指定IP的服务器的某个端口的联系。因为这个时候服务器已经在监听端口,因此会监听到来自客户端的connect请求,接下来就会调用accept来接受来自客户端的请求,这个时候,服务器还要创建一个Socket文件描述符,这个描述符跟之前服务器调用socket函数创建出来的监听Socket文件的描述符不同,这是为每个由服务器进程接受的客户连接创建的一个已连接socket描述符,这个描述符就代表了跟客户端之间的连接,可以对这个描述符进行读写,就代表了跟客户端之间的交互。关于阻塞IO与非阻塞IO,主要是在对于这个已连接描述的读写阻塞性上。
内核空间与用户空间
因为所有socket的函数,都是系统调用,最终都是由内核去做事情,这里就涉及到用户态与内核态的问题。一般来讲,在Linux中每一个进程都有两个栈,一个内核栈一个用户栈,用户栈就是常规意义上的栈,而内核栈就是内核代码运行使用的栈。在网络IO的过程中,需要注意的地方就在于内核使用的内存跟用户使用的内存是相互独立的,两者之间没有共享内存的存在,所以,在我们的read方法的时候,内核其实是做了两步操作,首先准备好read的数据,然后把数据从内核中拷贝到用户可以访问的内存中。
正式开始
非阻塞IO与阻塞IO的区别
之前已经提到,关于阻塞IO与非阻塞IO,主要是在对于已连接描述的读写阻塞性上。那就来具体看看,非阻塞到底跟阻塞有啥区别。
首先,服务器端在处理来自客户端的请求时,是用read来做的。read在内核中,需要做的有两步,第一步,就是准备好read的数据,第二步把数据从内核中拷贝到用户可以访问的内存中。
两者之间的区别,就在于阻塞IO,在调用read后,第一第二步都是阻塞的,也就是说,在内核准备数据,再到拷贝数据的时候,用户的线程是被阻塞掉的。而非阻塞IO,是指第一步,内核准备数据是不会阻塞用户线程的,会直接返回,而第二步拷贝数据跟阻塞IO一样,是阻塞的。但一般来讲,网络通信最大的瓶颈在于准备数据的过程,因为这段过程需要依靠TCP/UDP从网络上传输数据,而拷贝数据本身只是内存操作,是非常快的。所以,非阻塞IO可以空闲出很多用户线程的时间来处理别的事情。
但是,非阻塞IO虽然第一步不阻塞用户线程,但是为了得知内核是否已经将数据准备好,可以拷贝到用户空间,用户线程需要不断轮询内核,来获取数据准备的情况。这时候,就引入了一种处理这种轮询的方式,多路复用的概念就被提了出来。
IO多路复用
在我看来,IO多路复用是一种建立在非阻塞IO上的设计方式而已。 select为例,来讲讲我对它的理解。
如果要讲这个,就先要提到一种设计模式,那就是reactor模式。
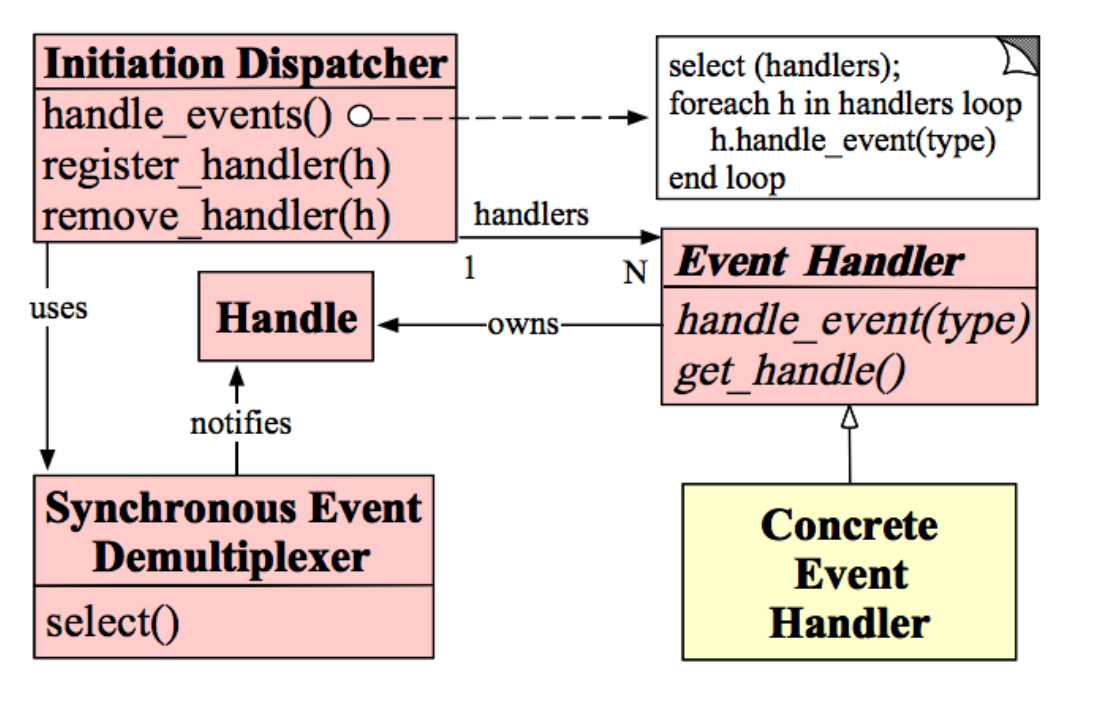
这是一种事件驱动的设计模式,关于这个设计模式的详细介绍,可以去参考链接中的第二个链接中看看。大致说来,这个模式由三个接口组成,分别是Initiation Dispatcher,Event Demultiplexer,和Event Handler。
Event Handler,就是在某个特定Handle上发生的事件的处理器。所有的Concrete Event Handler都会在Initiation Dispatcher注册,等待回调。
Initiation Dispatcher主要有两个函数,一个是注册Handler,一个是handle_events。注册Handler就是根据Handle来注册Handle对应的Handler。handle_events,就是调用Event Demultiplexer的轮询函数,然后根据不同Handle上触发的不同事件来回调之前注册的Handler上对应的函数。
Event Demultiplexer,其实就是select函数的封装,轮询每个句柄上发生的事件。Initiation Dispatcher会依赖它来决定触发回调哪些Handler的哪些函数。
落实到IO多路复用这个场景上,Handle就是Linux下的文件描述符,Event Demultiplexer就是select,poll等轮询函数。而Initiation Dispatcher和Event Handler还是要自己去抽象实现的。
整个事件循环的流程如下所示:
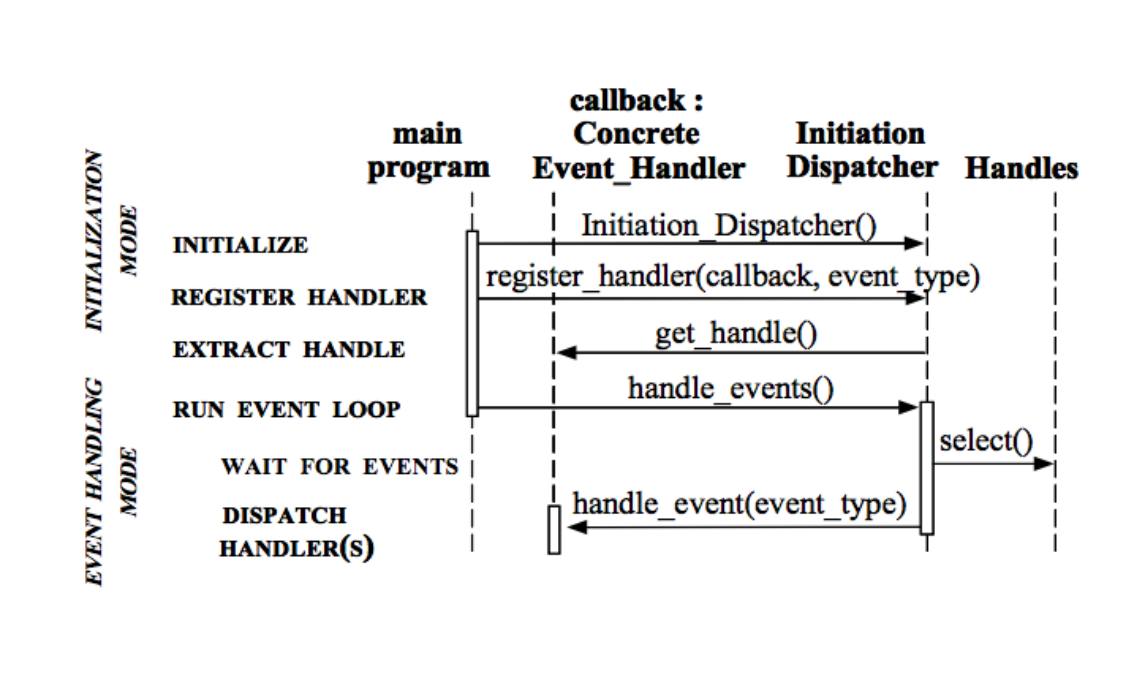
这样就构成了一个事件驱动的循环。这就是非阻塞IO带来的好处,在内核进行操作的第一步,也就是准备数据的阶段,是不阻塞用户线程的,因此可以用这种方式,以一定的周期轮询事件的发生,这样一个服务器端的线程可以为较多的客户端服务。而select,poll等等,在我看来,只是在非阻塞IO的基础上使用了一定的设计模式,使得设计更加合理化了而已,不知这样理解对不对。
而至于epoll,BSD上的kqueue,应该是相比于select和poll而言是更高效的实现方式,用到了红黑树,双链表,mmap等等提高了效率,避免了像select函数那样需要遍历整个Socket集合,随着Socket的增加,select和epoll是O(N)和O(1)的差距。具体内容还没有去看,这个留待之后有机会再总结吧。